 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Beyond Labels: Measuring LLM Sentiment in Low-Resource, Culturally Nuanced Contexts
Aug 06, 2025Sentiment analysis in low-resource, culturally nuanced contexts challenges conventional NLP approaches that assume fixed labels and universal affective expressions. We present a diagnostic framework that treats sentiment as a context-dependent, culturally embedded construct, and evaluate how large language models (LLMs) reason about sentiment in informal, code-mixed WhatsApp messages from Nairobi youth health groups. Using a combination of human-annotated data, sentiment-flipped counterfactuals, and rubric-based explanation evaluation, we probe LLM interpretability, robustness, and alignment with human reasoning. Framing our evaluation through a social-science measurement lens, we operationalize and interrogate LLMs outputs as an instrument for measuring the abstract concept of sentiment. Our findings reveal significant variation in model reasoning quality, with top-tier LLMs demonstrating interpretive stability, while open models often falter under ambiguity or sentiment shifts. This work highlights the need for culturally sensitive, reasoning-aware AI evaluation in complex, real-world communication.
Dukawalla: Voice Interfaces for Small Businesses in Africa
May 08, 2025Small and medium sized businesses often struggle with data driven decision making do to a lack of advanced analytics tools, especially in African countries where they make up a majority of the workforce. Though many tools exist they are not designed to fit into the ways of working of SMB workers who are mobile first, have limited time to learn new workflows, and for whom social and business are tightly coupled. To address this, the Dukawalla prototype was created. This intelligent assistant bridges the gap between raw business data, and actionable insights by leveraging voice interaction and the power of generative AI. Dukawalla provides an intuitive way for business owners to interact with their data, aiding in informed decision making. This paper examines Dukawalla's deployment across SMBs in Nairobi, focusing on their experiences using this voice based assistant to streamline data collection and provide business insights
AI and the Future of Work in Africa White Paper
Nov 15, 2024
This white paper is the output of a multidisciplinary workshop in Nairobi (Nov 2023). Led by a cross-organisational team including Microsoft Research, NEPAD, Lelapa AI, and University of Oxford. The workshop brought together diverse thought-leaders from various sectors and backgrounds to discuss the implications of Generative AI for the future of work in Africa. Discussions centred around four key themes: Macroeconomic Impacts; Jobs, Skills and Labour Markets; Workers' Perspectives and Africa-Centris AI Platforms. The white paper provides an overview of the current state and trends of generative AI and its applications in different domains, as well as the challenges and risks associated with its adoption and regulation. It represents a diverse set of perspectives to create a set of insights and recommendations which aim to encourage debate and collaborative action towards creating a dignified future of work for everyone across Africa.
Beyond Metrics: Evaluating LLMs' Effectiveness in Culturally Nuanced, Low-Resource Real-World Scenarios
Jun 01, 2024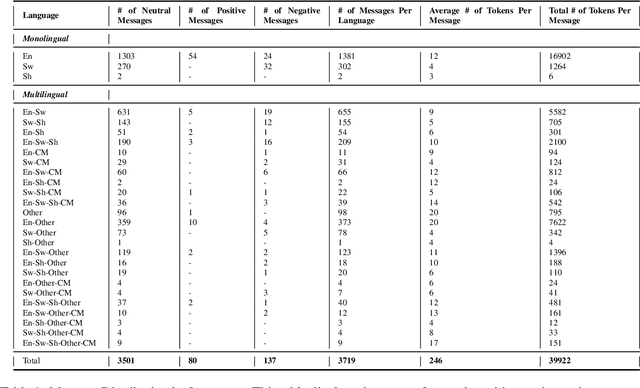
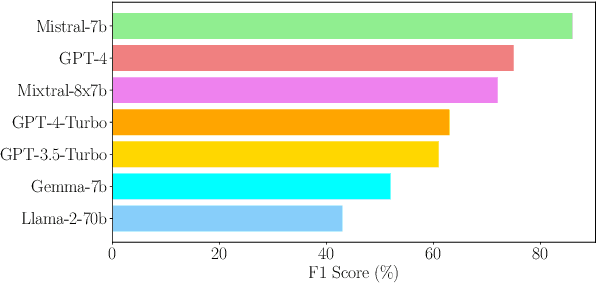
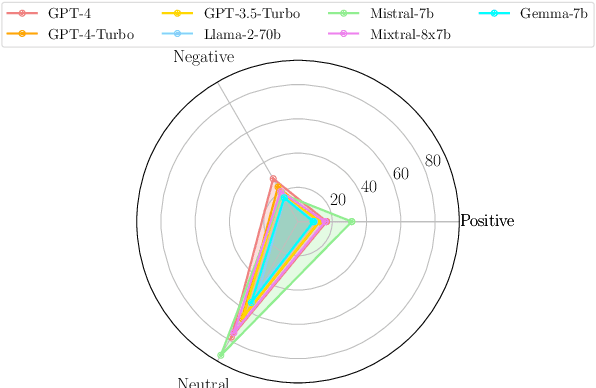
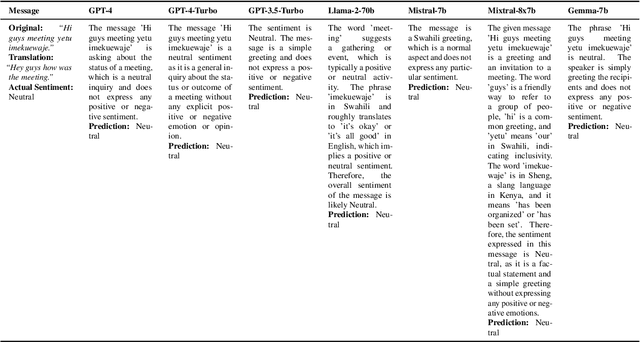
The deployment of Large Language Models (LLMs) in real-world applications presents both opportunities and challenges, particularly in multilingual and code-mixed communication settings. This research evaluates the performance of seven leading LLMs in sentiment analysis on a dataset derived from multilingual and code-mixed WhatsApp chats, including Swahili, English and Sheng. Our evaluation includes both quantitative analysis using metrics like F1 score and qualitative assessment of LLMs' explanations for their predictions. We find that, while Mistral-7b and Mixtral-8x7b achieved high F1 scores, they and other LLMs such as GPT-3.5-Turbo, Llama-2-70b, and Gemma-7b struggled with understanding linguistic and contextual nuances, as well as lack of transparency in their decision-making process as observed from their explanations. In contrast, GPT-4 and GPT-4-Turbo excelled in grasping diverse linguistic inputs and managing various contextual information, demonstrating high consistency with human alignment and transparency in their decision-making process. The LLMs however, encountered difficulties in incorporating cultural nuance especially in non-English settings with GPT-4s doing so inconsistently. The findings emphasize the necessity of continuous improvement of LLMs to effectively tackle the challenges of culturally nuanced, low-resource real-world settings.