 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver-the-Air Transmission of Zak-OTFS on mmWave Communications Testbed
Nov 10, 2025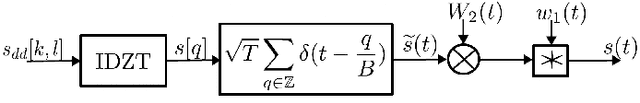
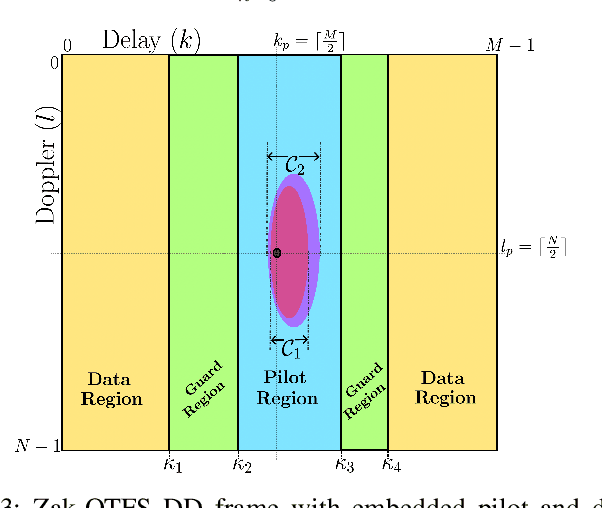
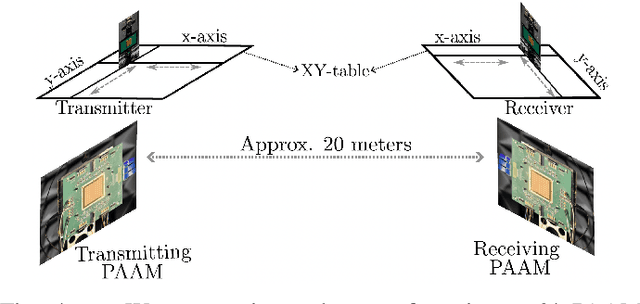
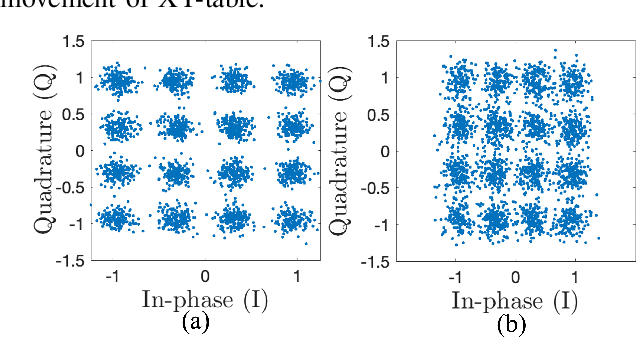
Millimeter-wave (mmWave) communication offers vast bandwidth for next-generation wireless systems but faces severe path loss, Doppler effects, and hardware impairments. Orthogonal Time Frequency Space (OTFS) modulation has emerged as a robust waveform for high-mobility and doubly dispersive channels, outperforming OFDM under strong Doppler. However, the most studied multicarrier OTFS (MC-OTFS) is not easily predictable because the input-output (I$/$O) relation is not given by (twisted) convolution. Recently, the Zak-transform based OTFS (Zak-OTFS or OTFS 2$.$0) was proposed, which provides a single domain delay Doppler (DD) processing framework with predictable I$/$O behavior. This paper presents one of the first over-the-air (OTA) demonstrations of Zak-OTFS at mmWave frequencies. We design a complete Zak-OTFS based mmWave OTA system featuring root-raised-cosine (RRC) filtering for enhanced DD-domain predictability, higher-order modulations up to 16-QAM, and a low-overhead preamble for synchronization. A comprehensive signal model incorporating carrier frequency offset (CFO) and timing impairments is developed, showing these effects can be jointly captured within the effective DD-domain channel. Experimental validation on the COSMOS testbed confirms the feasibility and robustness of Zak-OTFS under realistic mmWave conditions, highlighting its potential for efficient implementations in beyond-5G and 6G systems.
Wall-Street: Smart Surface-Enabled 5G mmWave for Roadside Networking
May 10, 2024



5G mmWave roadside networks promise high-speed wireless connectivity, but face significant challenges in maintaining reliable connections for users moving at high speed. Frequent handovers, complex beam alignment, and signal attenuation due to obstacles like car bodies lead to service interruptions and degraded performance. We present Wall-Street, a smart surface installed on vehicles to enhance 5G mmWave connectivity for users inside. Wall-Street improves mobility management by (1) steering outdoor mmWave signals into the vehicle, ensuring coverage for all users; (2) enabling simultaneous serving cell data transfer and candidate handover cell measurement, allowing seamless handovers without service interruption; and (3) combining beams from source and target cells during a handover to increase reliability. Through its flexible and diverse signal manipulation capabilities, Wall-Street provides uninterrupted high-speed connectivity for latency-sensitive applications in challenging mobile environments. We have implemented and integrated Wall-Street in the COSMOS testbed and evaluated its real-time performance with four gNBs and a mobile client inside a surface-enabled vehicle, driving on a nearby road. Wall-Street achieves a 2.5-3.4x TCP throughput improvement and a 0.4-0.8x reduction in delay over a baseline 5G Standalone handover protocol.
Design and Testbed Deployment of Frequency-Domain Equalization Full Duplex Radios
Jan 31, 2024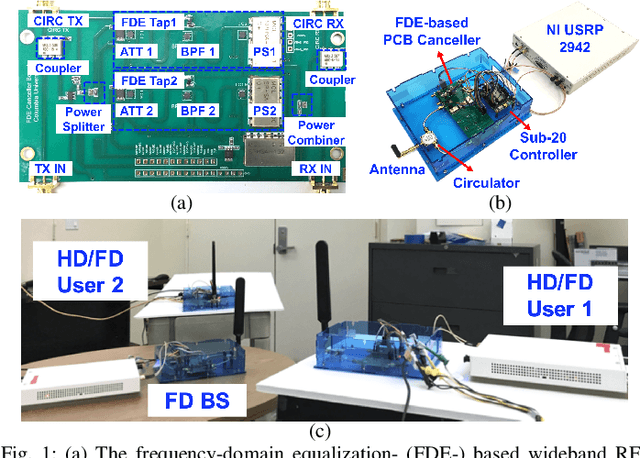
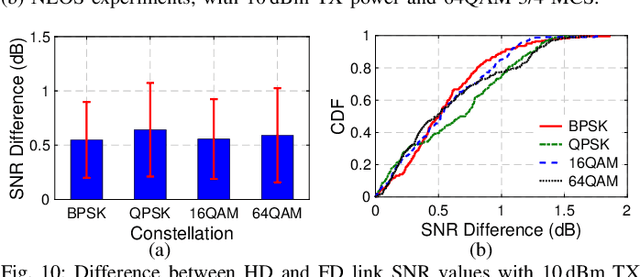
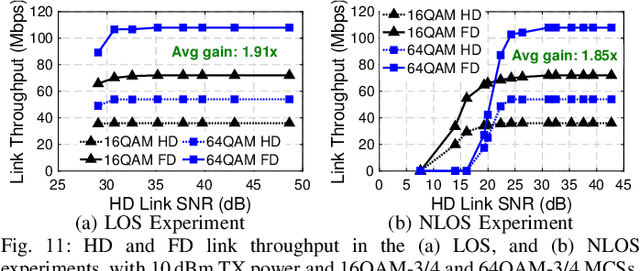
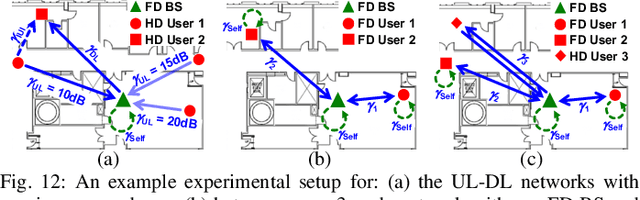
Full-duplex (FD) wireless can significantly enhance spectrum efficiency but requires effective self-interference (SI) cancellers. RF SI cancellation (SIC) via frequency-domain equalization (FDE), where bandpass filters channelize the SI, is suited for integrated circuits (ICs). In this paper, we explore the limits and higher layer challenges associated with using such cancellers. We evaluate the performance of a custom FDE-based canceller using two testbeds; one with mobile FD radios and the other with upgraded, static FD radios in the PAWR COSMOS testbed. The latter is a lasting artifact for the research community, alongside a dataset containing baseband waveforms captured on the COSMOS FD radios, facilitating FD-related experimentation at the higher networking layers. We evaluate the performance of the FDE-based FD radios in both testbeds, with experiments showing 95 dB overall achieved SIC (52 dB from RF SIC) across 20 MHz bandwidth, and an average link-level FD rate gain of 1.87x. We also conduct experiments in (i) uplink-downlink networks with inter-user interference, and (ii) heterogeneous networks with half-duplex and FD users. The experimental FD gains in the two types of networks depend on the users' SNR values and the number of FD users, and are 1.14x-1.25x and 1.25x-1.73x, respectively, confirming previous analytical results.
Channel Estimation for Massive MIMO systems using Tensor Cores in GPU
Jun 11, 2022

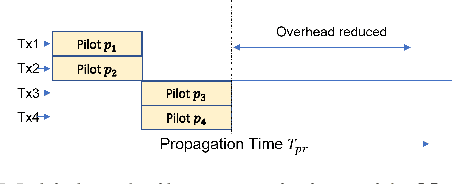

For efficient use of Massive MIMO systems, fast and accurate channel estimation is very important. But the Large-scale antenna array presence requires high pilot overhead for high accuracy of estimation. Also, when used with software-based processing systems like CPUs and GPUs, high processing latency becomes a major issue. To reduce Pilot overhead, a Pilot transmission scheme in combination with PN Sequence correlation based channel estimation scheme is implemented. Then, to deal with the issue of high processing latency, Tensor Cores in Nvidia GPUs are used for computing the channel estimation. Experiments are performed by using Nvidia V100 GPU in the ORBIT Testbed to show the performance of the Pilot transmission scheme. By varying factors like PN sequence length, Channel Impulse Response length, number of multiplexed transmitters, and scale of MIMO, the accuracy and processing latency of Tensor Core implementation of the Channel Estimation is evaluated.
Smart City Intersections: Intelligence Nodes for Future Metropolises
May 13, 2022


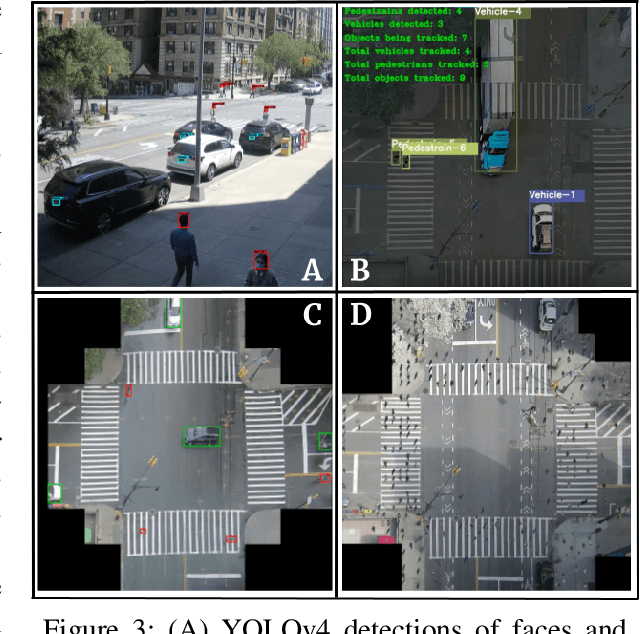
Traffic intersections are the most suitable locations for the deployment of computing, communications, and intelligence services for smart cities of the future. The abundance of data to be collected and processed, in combination with privacy and security concerns, motivates the use of the edge-computing paradigm which aligns well with physical intersections in metropolises. This paper focuses on high-bandwidth, low-latency applications, and in that context it describes: (i) system design considerations for smart city intersection intelligence nodes; (ii) key technological components including sensors, networking, edge computing, low latency design, and AI-based intelligence; and (iii) applications such as privacy preservation, cloud-connected vehicles, a real-time "radar-screen", traffic management, and monitoring of pedestrian behavior during pandemics. The results of the experimental studies performed on the COSMOS testbed located in New York City are illustrated. Future challenges in designing human-centered smart city intersections are summarized.
Implementation of FGPA based Channel Sounder for Large scale antenna systems using RFNoC on USRP Platform
Jan 12, 2022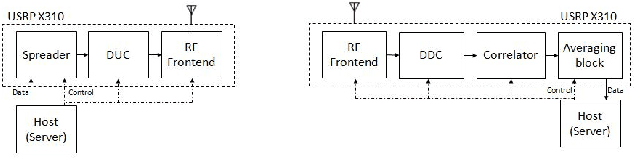
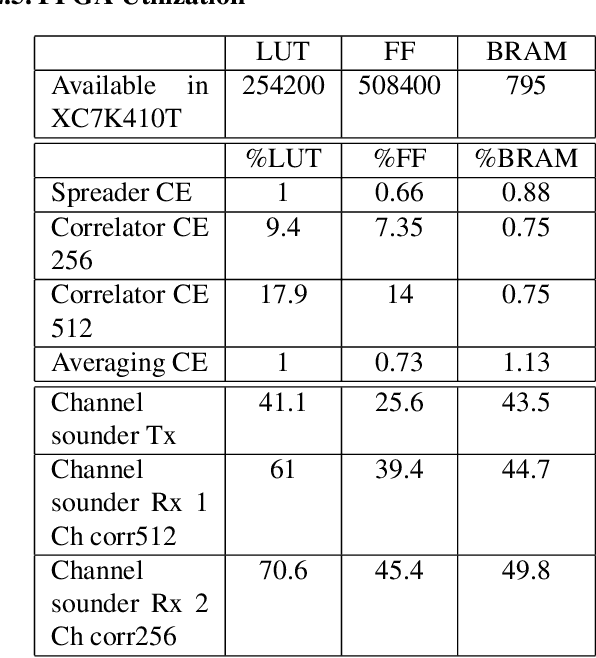


This paper concentrates on building a multi-antenna FPGA based Channel Sounder with single transmitter and multiple receivers to realize wireless propagation characteristics of an indoor environment. A DSSS signal (spread with a real maximum length PN sequence) is transmitted, which is correlated with the same PN sequence at each receiver to obtain the power delay profile . Multiple power delay profiles are averaged and the result is then sent to host. To utilize high bandwidth, the computationally expensive tasks related to generation and parallel correlation of PN sequences are moved to the FPGA present in each USRP (Universal Software Radio Peripheral). Channel sounder blocks were built using Vivado HLS and integrated with RFNoC (RF Network on Chip) framework, which were then used on USRP X310 devices.
* This paper was presented in GRCon 2017 and published in the Proceedings of the GNU Radio Conference
Distributed Processing for Encoding and Decoding of Binary LDPC codes using MPI
Jan 12, 2022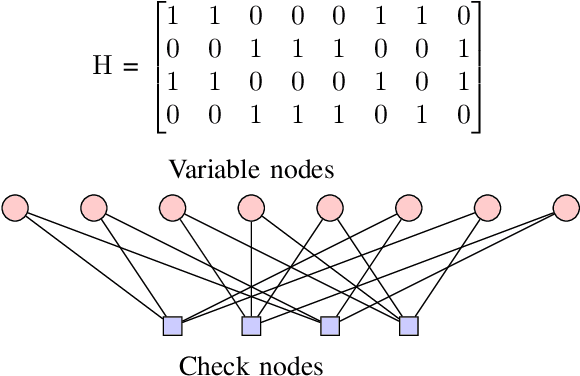
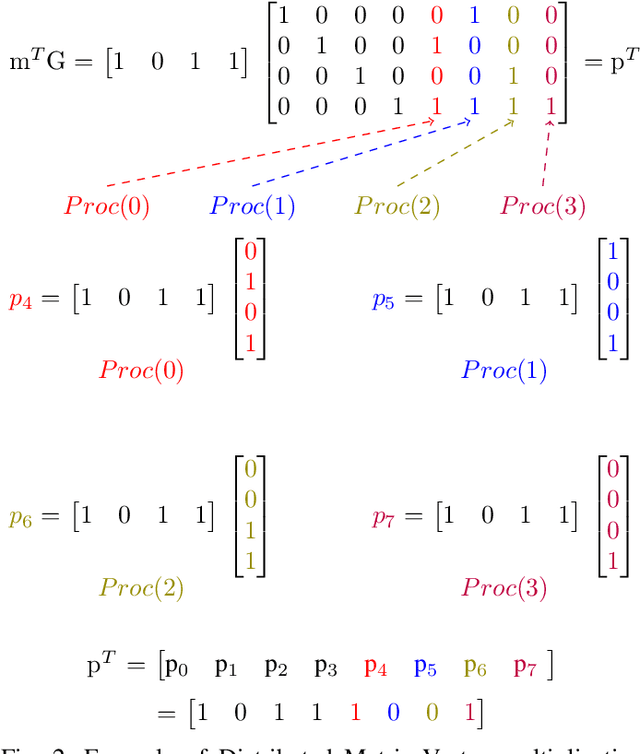
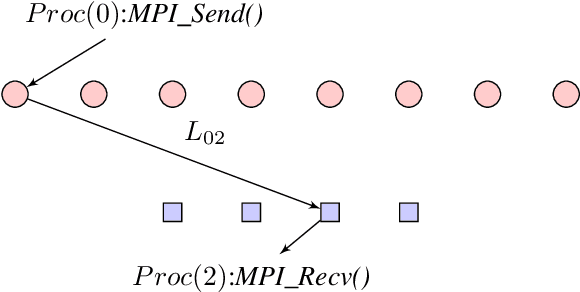
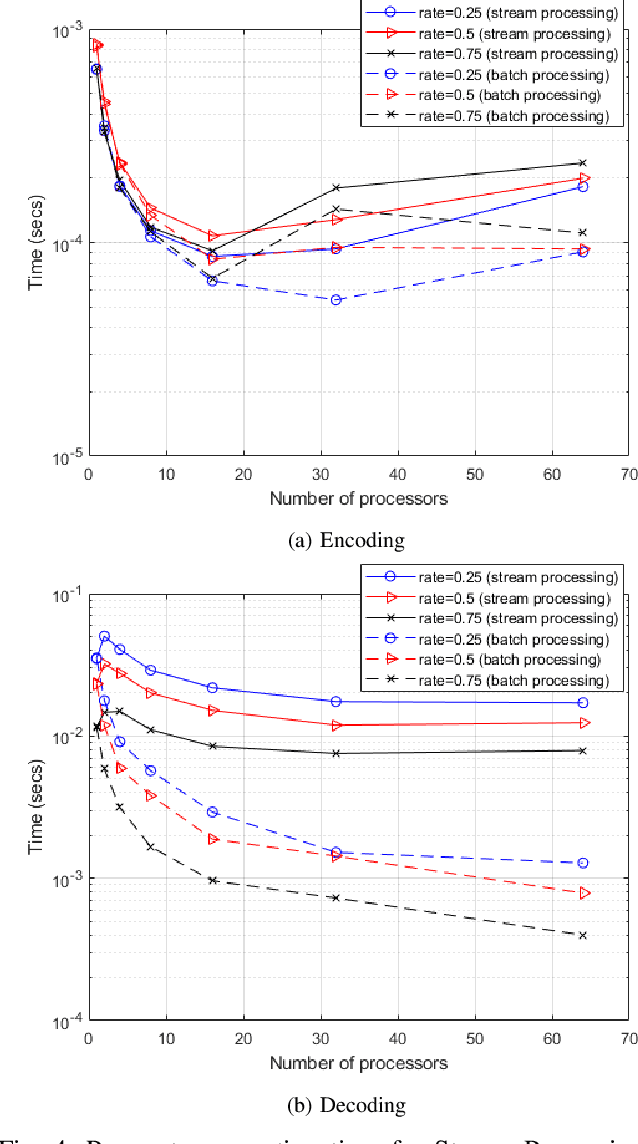
Low Density Parity Check (LDPC) codes are linear error correcting codes used in communication systems for Forward Error Correction (FEC). But, intensive computation is required for encoding and decoding of LDPC codes, making it difficult for practical usage in general purpose software based signal processing systems. In order to accelerate the encoding and decoding of LDPC codes, distributed processing over multiple multi-core CPUs using Message Passing Interface (MPI) is performed. Implementation is done using Stream Processing and Batch Processing mechanisms and the execution time for both implementations is compared w.r.t variation in number of CPUs and number of cores per CPU. Performance evaluation of distributed processing is shown by variation in execution time w.r.t. increase in number of processors (CPU cores).