 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel Estimation for Massive MIMO systems using Tensor Cores in GPU
Jun 11, 2022

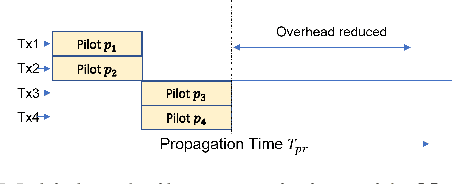

For efficient use of Massive MIMO systems, fast and accurate channel estimation is very important. But the Large-scale antenna array presence requires high pilot overhead for high accuracy of estimation. Also, when used with software-based processing systems like CPUs and GPUs, high processing latency becomes a major issue. To reduce Pilot overhead, a Pilot transmission scheme in combination with PN Sequence correlation based channel estimation scheme is implemented. Then, to deal with the issue of high processing latency, Tensor Cores in Nvidia GPUs are used for computing the channel estimation. Experiments are performed by using Nvidia V100 GPU in the ORBIT Testbed to show the performance of the Pilot transmission scheme. By varying factors like PN sequence length, Channel Impulse Response length, number of multiplexed transmitters, and scale of MIMO, the accuracy and processing latency of Tensor Core implementation of the Channel Estimation is evaluated.
Implementation of FGPA based Channel Sounder for Large scale antenna systems using RFNoC on USRP Platform
Jan 12, 2022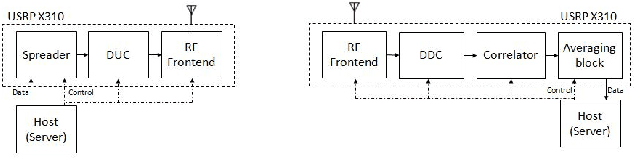
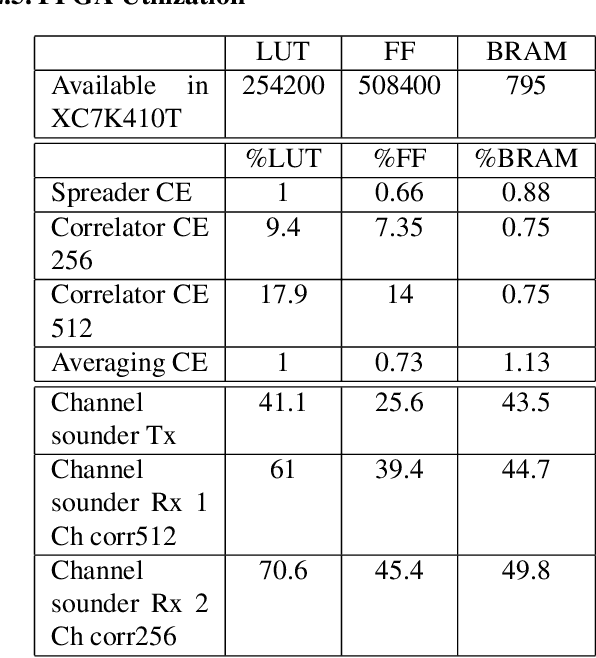


This paper concentrates on building a multi-antenna FPGA based Channel Sounder with single transmitter and multiple receivers to realize wireless propagation characteristics of an indoor environment. A DSSS signal (spread with a real maximum length PN sequence) is transmitted, which is correlated with the same PN sequence at each receiver to obtain the power delay profile . Multiple power delay profiles are averaged and the result is then sent to host. To utilize high bandwidth, the computationally expensive tasks related to generation and parallel correlation of PN sequences are moved to the FPGA present in each USRP (Universal Software Radio Peripheral). Channel sounder blocks were built using Vivado HLS and integrated with RFNoC (RF Network on Chip) framework, which were then used on USRP X310 devices.
* This paper was presented in GRCon 2017 and published in the Proceedings of the GNU Radio Conference
Distributed Processing for Encoding and Decoding of Binary LDPC codes using MPI
Jan 12, 2022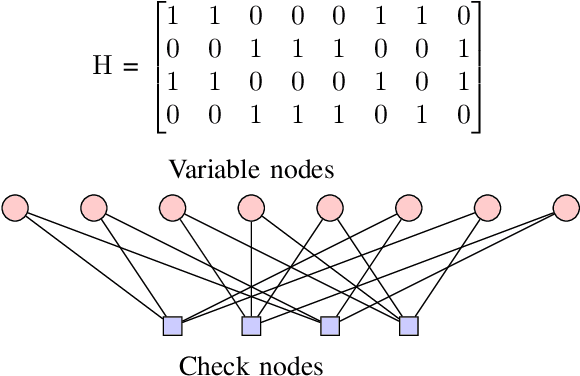
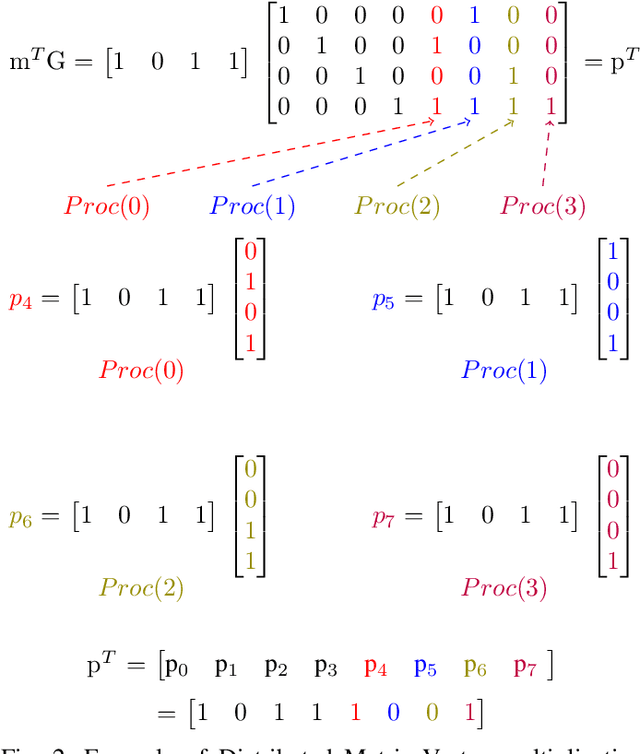
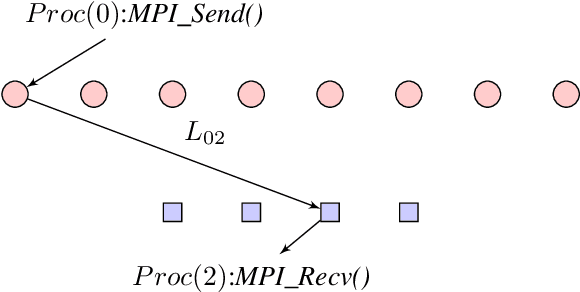
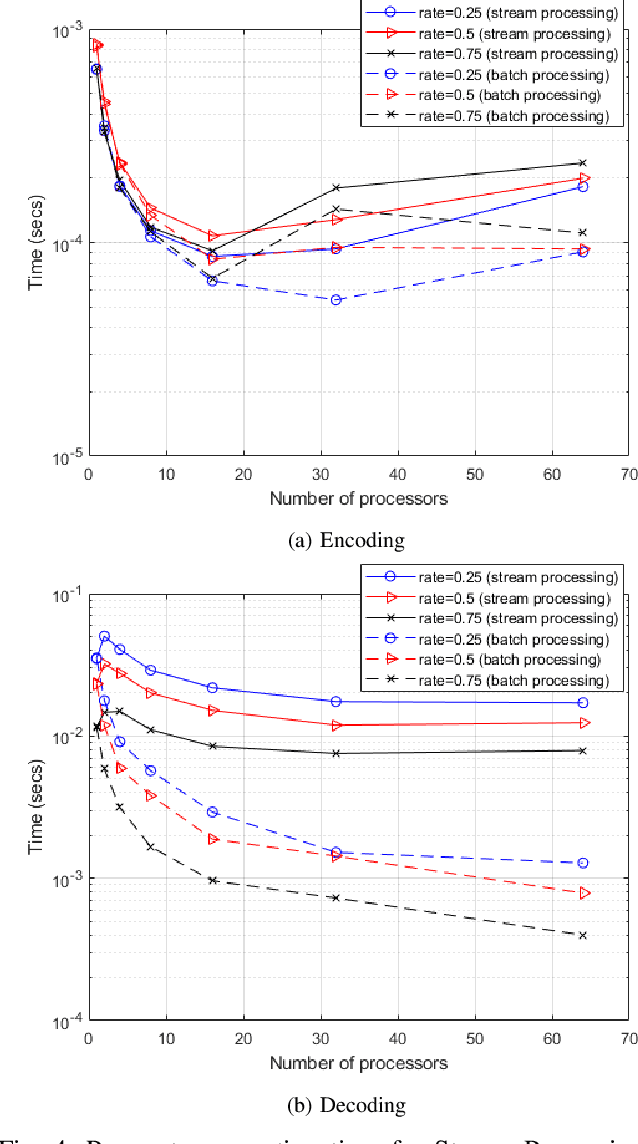
Low Density Parity Check (LDPC) codes are linear error correcting codes used in communication systems for Forward Error Correction (FEC). But, intensive computation is required for encoding and decoding of LDPC codes, making it difficult for practical usage in general purpose software based signal processing systems. In order to accelerate the encoding and decoding of LDPC codes, distributed processing over multiple multi-core CPUs using Message Passing Interface (MPI) is performed. Implementation is done using Stream Processing and Batch Processing mechanisms and the execution time for both implementations is compared w.r.t variation in number of CPUs and number of cores per CPU. Performance evaluation of distributed processing is shown by variation in execution time w.r.t. increase in number of processors (CPU cores).