 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetries, flat minima, and the conserved quantities of gradient flow
Oct 31, 2022



Empirical studies of the loss landscape of deep networks have revealed that many local minima are connected through low-loss valleys. Ensemble models sampling different parts of a low-loss valley have reached SOTA performance. Yet, little is known about the theoretical origin of such valleys. We present a general framework for finding continuous symmetries in the parameter space, which carve out low-loss valleys. Importantly, we introduce a novel set of nonlinear, data-dependent symmetries for neural networks. These symmetries can transform a trained model such that it performs similarly on new samples. We then show that conserved quantities associated with linear symmetries can be used to define coordinates along low-loss valleys. The conserved quantities help reveal that using common initialization methods, gradient flow only explores a small part of the global minimum. By relating conserved quantities to convergence rate and sharpness of the minimum, we provide insights on how initialization impacts convergence and generalizability. We also find the nonlinear action to be viable for ensemble building to improve robustness under certain adversarial attacks.
Quiver neural networks
Jul 26, 2022
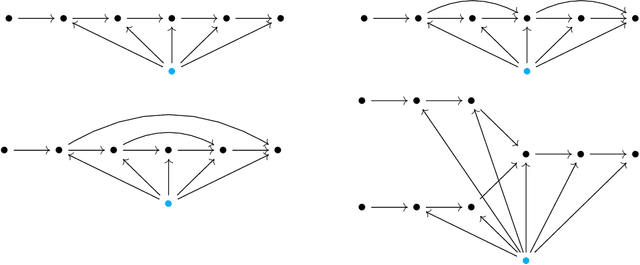


We develop a uniform theoretical approach towards the analysis of various neural network connectivity architectures by introducing the notion of a quiver neural network. Inspired by quiver representation theory in mathematics, this approach gives a compact way to capture elaborate data flows in complex network architectures. As an application, we use parameter space symmetries to prove a lossless model compression algorithm for quiver neural networks with certain non-pointwise activations known as rescaling activations. In the case of radial rescaling activations, we prove that training the compressed model with gradient descent is equivalent to training the original model with projected gradient descent.
The QR decomposition for radial neural networks
Jul 06, 2021

We provide a theoretical framework for neural networks in terms of the representation theory of quivers, thus revealing symmetries of the parameter space of neural networks. An exploitation of these symmetries leads to a model compression algorithm for radial neural networks based on an analogue of the QR decomposition. A projected version of backpropogation on the original model matches usual backpropogation on the compressed model.