 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy not both? Complementing explanations with uncertainty, and the role of self-confidence in Human-AI collaboration
Apr 27, 2023AI and ML models have already found many applications in critical domains, such as healthcare and criminal justice. However, fully automating such high-stakes applications can raise ethical or fairness concerns. Instead, in such cases, humans should be assisted by automated systems so that the two parties reach a joint decision, stemming out of their interaction. In this work we conduct an empirical study to identify how uncertainty estimates and model explanations affect users' reliance, understanding, and trust towards a model, looking for potential benefits of bringing the two together. Moreover, we seek to assess how users' behaviour is affected by their own self-confidence in their abilities to perform a certain task, while we also discuss how the latter may distort the outcome of an analysis based on agreement and switching percentages.
Explainability in Machine Learning: a Pedagogical Perspective
Feb 21, 2022Given the importance of integrating of explainability into machine learning, at present, there are a lack of pedagogical resources exploring this. Specifically, we have found a need for resources in explaining how one can teach the advantages of explainability in machine learning. Often pedagogical approaches in the field of machine learning focus on getting students prepared to apply various models in the real world setting, but much less attention is given to teaching students the various techniques one could employ to explain a model's decision-making process. Furthermore, explainability can benefit from a narrative structure that aids one in understanding which techniques are governed by which questions about the data. We provide a pedagogical perspective on how to structure the learning process to better impart knowledge to students and researchers in machine learning, when and how to implement various explainability techniques as well as how to interpret the results. We discuss a system of teaching explainability in machine learning, by exploring the advantages and disadvantages of various opaque and transparent machine learning models, as well as when to utilize specific explainability techniques and the various frameworks used to structure the tools for explainability. Among discussing concrete assignments, we will also discuss ways to structure potential assignments to best help students learn to use explainability as a tool alongside any given machine learning application. Data science professionals completing the course will have a birds-eye view of a rapidly developing area and will be confident to deploy machine learning more widely. A preliminary analysis on the effectiveness of a recently delivered course following the structure presented here is included as evidence supporting our pedagogical approach.
Principled Diverse Counterfactuals in Multilinear Models
Jan 17, 2022


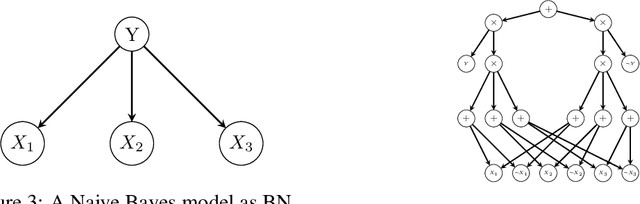
Machine learning (ML) applications have automated numerous real-life tasks, improving both private and public life. However, the black-box nature of many state-of-the-art models poses the challenge of model verification; how can one be sure that the algorithm bases its decisions on the proper criteria, or that it does not discriminate against certain minority groups? In this paper we propose a way to generate diverse counterfactual explanations from multilinear models, a broad class which includes Random Forests, as well as Bayesian Networks.
Principles and Practice of Explainable Machine Learning
Sep 18, 2020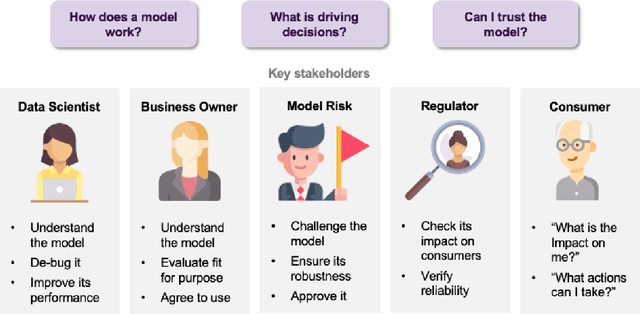
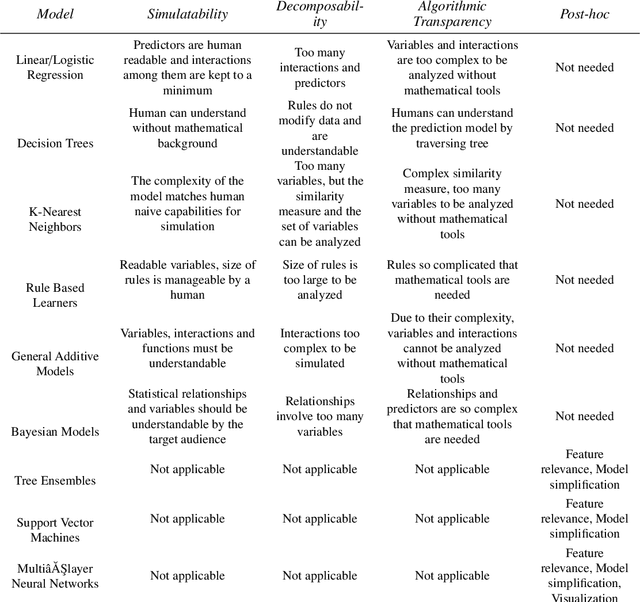
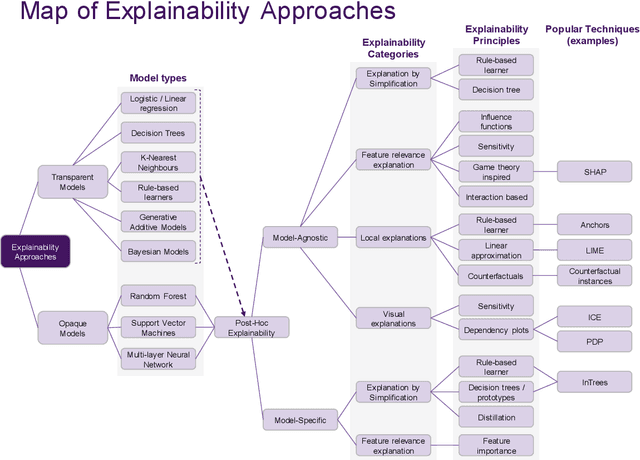
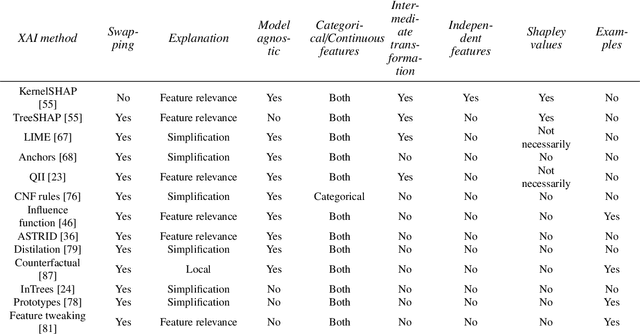
Artificial intelligence (AI) provides many opportunities to improve private and public life. Discovering patterns and structures in large troves of data in an automated manner is a core component of data science, and currently drives applications in diverse areas such as computational biology, law and finance. However, such a highly positive impact is coupled with significant challenges: how do we understand the decisions suggested by these systems in order that we can trust them? In this report, we focus specifically on data-driven methods -- machine learning (ML) and pattern recognition models in particular -- so as to survey and distill the results and observations from the literature. The purpose of this report can be especially appreciated by noting that ML models are increasingly deployed in a wide range of businesses. However, with the increasing prevalence and complexity of methods, business stakeholders in the very least have a growing number of concerns about the drawbacks of models, data-specific biases, and so on. Analogously, data science practitioners are often not aware about approaches emerging from the academic literature, or may struggle to appreciate the differences between different methods, so end up using industry standards such as SHAP. Here, we have undertaken a survey to help industry practitioners (but also data scientists more broadly) understand the field of explainable machine learning better and apply the right tools. Our latter sections build a narrative around a putative data scientist, and discuss how she might go about explaining her models by asking the right questions.
On Constraint Definability in Tractable Probabilistic Models
Jan 29, 2020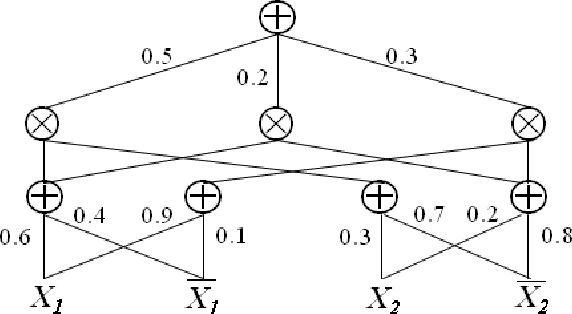
Incorporating constraints is a major concern in probabilistic machine learning. A wide variety of problems require predictions to be integrated with reasoning about constraints, from modelling routes on maps to approving loan predictions. In the former, we may require the prediction model to respect the presence of physical paths between the nodes on the map, and in the latter, we may require that the prediction model respect fairness constraints that ensure that outcomes are not subject to bias. Broadly speaking, constraints may be probabilistic, logical or causal, but the overarching challenge is to determine if and how a model can be learnt that handles all the declared constraints. To the best of our knowledge, this is largely an open problem. In this paper, we consider a mathematical inquiry on how the learning of tractable probabilistic models, such as sum-product networks, is possible while incorporating constraints.
Interventions and Counterfactuals in Tractable Probabilistic Models: Limitations of Contemporary Transformations
Jan 29, 2020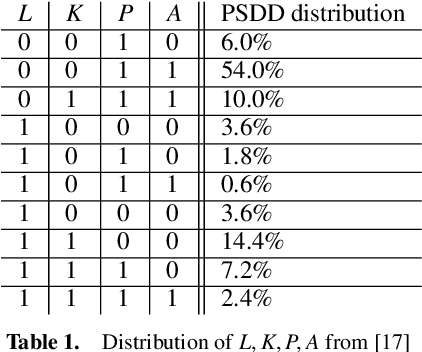
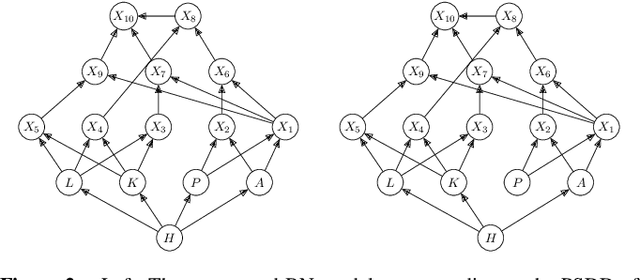
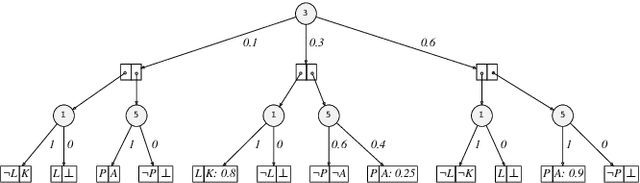
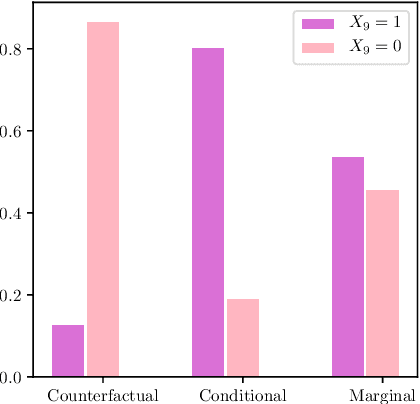
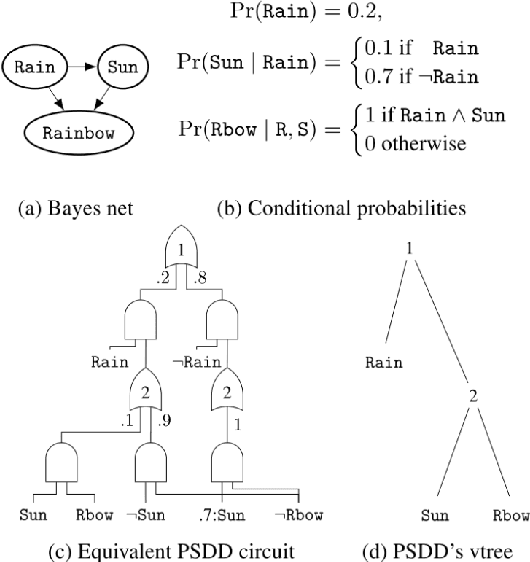
In recent years, there has been an increasing interest in studying causality-related properties in machine learning models generally, and in generative models in particular. While that is well motivated, it inherits the fundamental computational hardness of probabilistic inference, making exact reasoning intractable. Probabilistic tractable models have also recently emerged, which guarantee that conditional marginals can be computed in time linear in the size of the model, where the model is usually learned from data. Although initially limited to low tree-width models, recent tractable models such as sum product networks (SPNs) and probabilistic sentential decision diagrams (PSDDs) exploit efficient function representations and also capture high tree-width models. In this paper, we ask the following technical question: can we use the distributions represented or learned by these models to perform causal queries, such as reasoning about interventions and counterfactuals? By appealing to some existing ideas on transforming such models to Bayesian networks, we answer mostly in the negative. We show that when transforming SPNs to a causal graph interventional reasoning reduces to computing marginal distributions; in other words, only trivial causal reasoning is possible. For PSDDs the situation is only slightly better. We first provide an algorithm for constructing a causal graph from a PSDD, which introduces augmented variables. Intervening on the original variables, once again, reduces to marginal distributions, but when intervening on the augmented variables, a deterministic but nonetheless causal-semantics can be provided for PSDDs.