 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Decompositions for Large Scale SVMs
Feb 08, 2018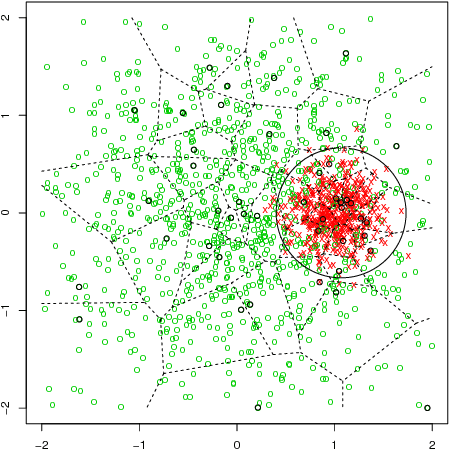
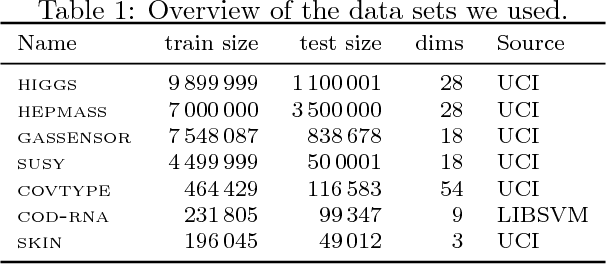
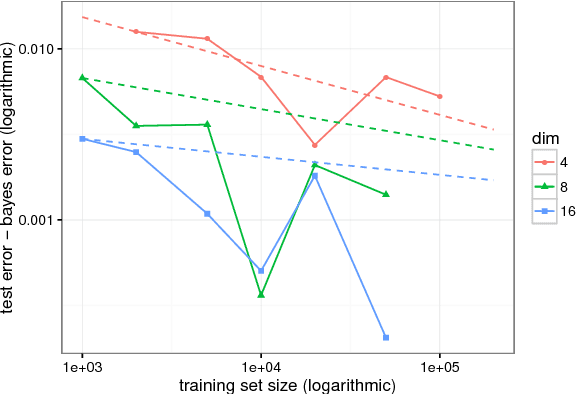
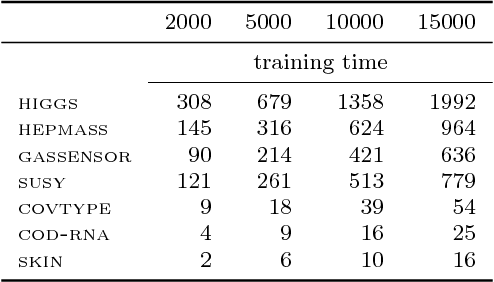
Although support vector machines (SVMs) are theoretically well understood, their underlying optimization problem becomes very expensive, if, for example, hundreds of thousands of samples and a non-linear kernel are considered. Several approaches have been proposed in the past to address this serious limitation. In this work we investigate a decomposition strategy that learns on small, spatially defined data chunks. Our contributions are two fold: On the theoretical side we establish an oracle inequality for the overall learning method using the hinge loss, and show that the resulting rates match those known for SVMs solving the complete optimization problem with Gaussian kernels. On the practical side we compare our approach to learning SVMs on small, randomly chosen chunks. Here it turns out that for comparable training times our approach is significantly faster during testing and also reduces the test error in most cases significantly. Furthermore, we show that our approach easily scales up to 10 million training samples: including hyper-parameter selection using cross validation, the entire training only takes a few hours on a single machine. Finally, we report an experiment on 32 million training samples. All experiments used liquidSVM (Steinwart and Thomann, 2017).