 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditory Model based Phase-Aware Bayesian Spectral Amplitude Estimator for Single-Channel Speech Enhancement
Feb 10, 2022
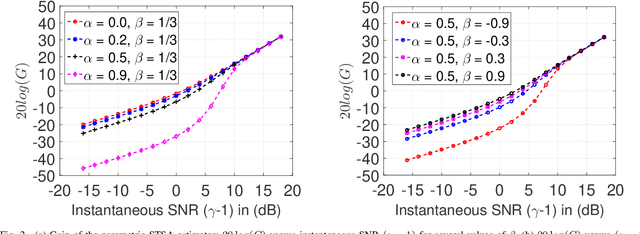
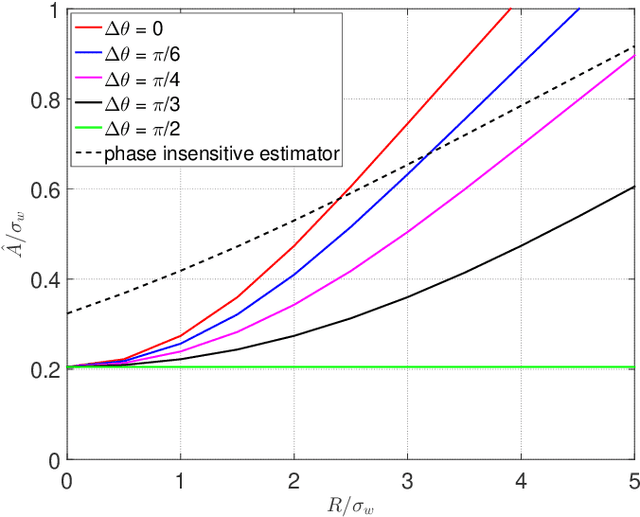
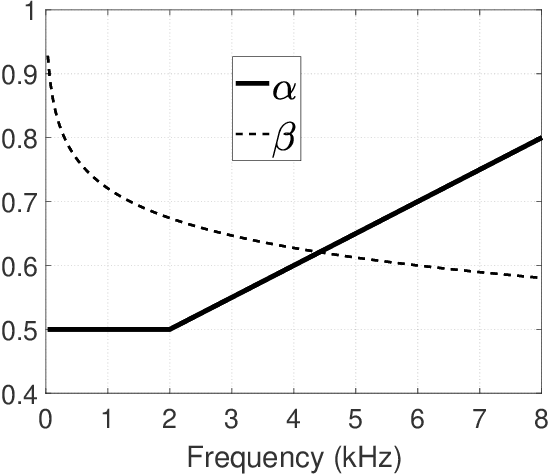
Bayesian estimation of short-time spectral amplitude is one of the most predominant approaches for the enhancement of the noise corrupted speech. The performance of these estimators are usually significantly improved when any perceptually relevant cost function is considered. On the other hand, the recent progress in the phase-based speech signal processing have shown that the phase-only enhancement based on spectral phase estimation methods can also provide joint improvement in the perceived speech quality and intelligibility, even in low SNR conditions. In this paper, to take advantage of both the perceptually motivated cost function involving STSAs of estimated and true clean speech and utilizing the prior spectral phase information, we have derived a phase-aware Bayesian STSA estimator. The parameters of the cost function are chosen based on the characteristics of the human auditory system, namely, the dynamic compressive nonlinearity of the cochlea, the perceived loudness theory and the simultaneous masking properties of the ear. This type of parameter selection scheme results in more noise reduction while limiting the speech distortion. The derived STSA estimator is optimal in the MMSE sense if the prior phase information is available. In practice, however, typically only an estimate of the clean speech phase can be obtained via employing different types of spectral phase estimation techniques which have been developed throughout the last few years. In a blind setup, we have evaluated the proposed Bayesian STSA estimator with different types of standard phase estimation methods available in the literature. Experimental results have shown that the proposed estimator can achieve substantial improvement in performance than the traditional phase-blind approaches.
Intelligent Wireless Sensor Nodes for Human Footstep Sound Classification for Security Application
Dec 23, 2019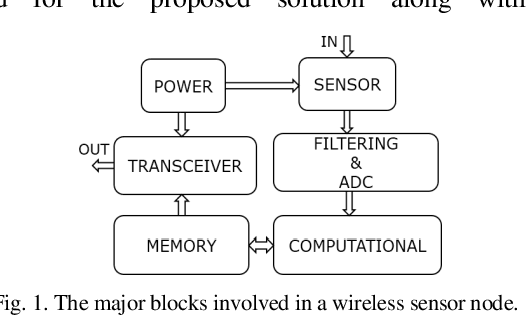
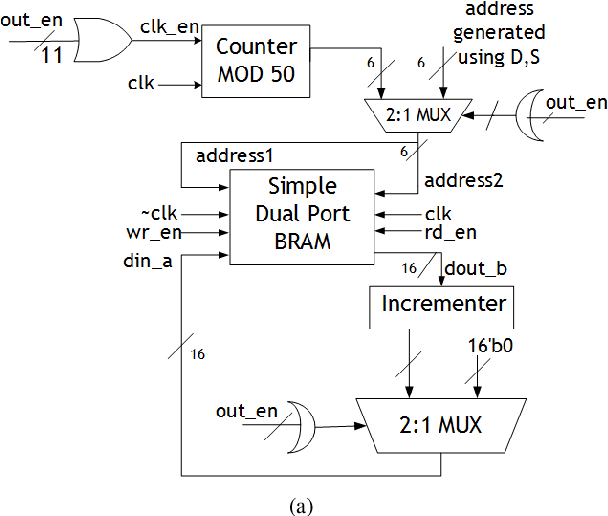
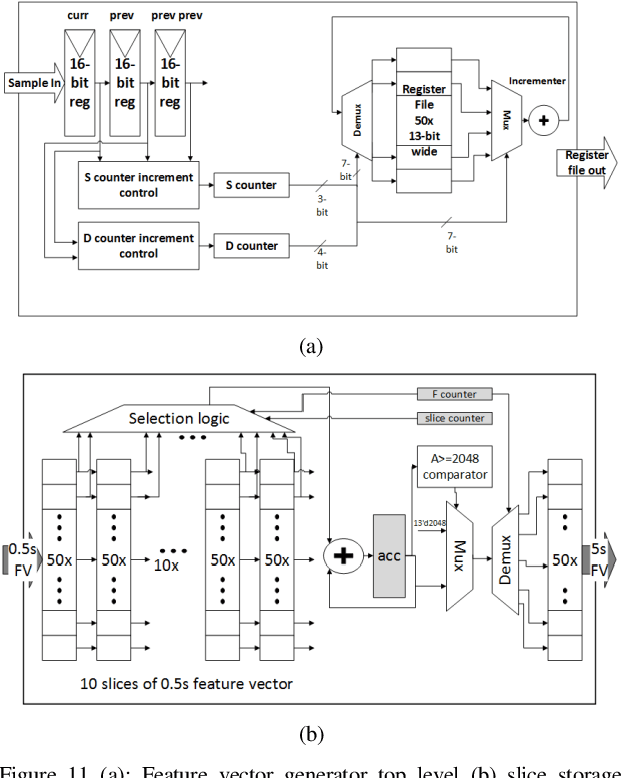
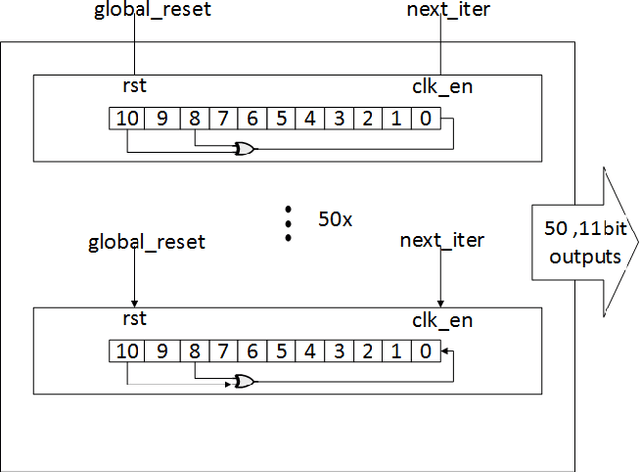
Sensor nodes present in a wireless sensor network (WSN) for security surveillance applications should preferably be small, energy-efficient and inexpensive with on-sensor computational abilities. An appropriate data processing scheme in the sensor node can help in reducing the power dissipation of the transceiver through compression of information to be communicated. In this paper, authors have attempted a simulation-based study of human footstep sound classification in natural surroundings using simple time-domain features. We used a spiking neural network (SNN), a computationally low weight classifier, derived from an artificial neural network (ANN), for classification. A classification accuracy greater than 85% is achieved using an SNN, degradation of ~5% as compared to ANN. The SNN scheme, along with the required feature extraction scheme, can be amenable to low power sub-threshold analog implementation. Results show that all analog implementation of the proposed SNN scheme can achieve significant power savings over the digital implementation of the same computing scheme and also over other conventional digital architectures using frequency-domain feature extraction and ANN-based classification.
Tensor-Train Long Short-Term Memory for Monaural Speech Enhancement
Dec 25, 2018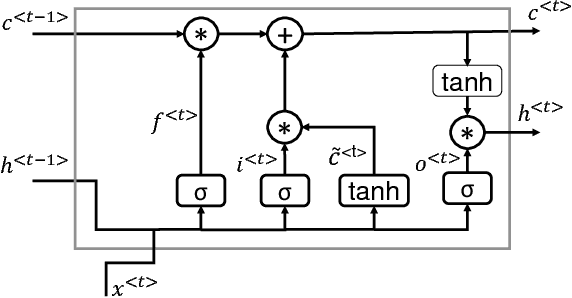
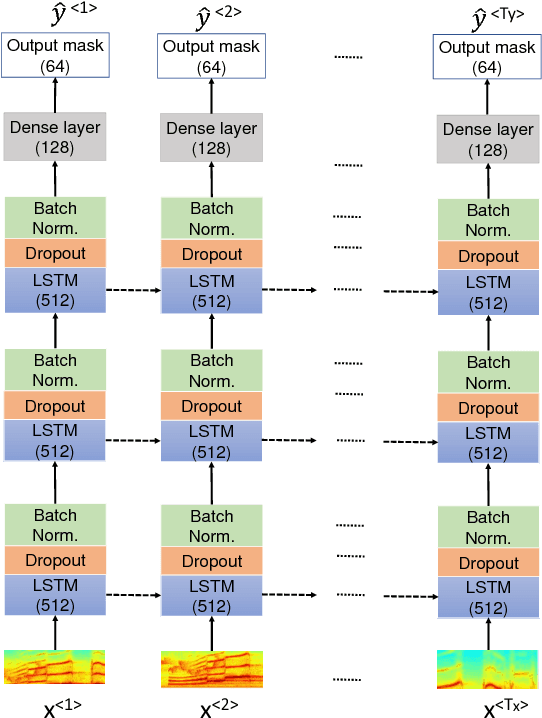
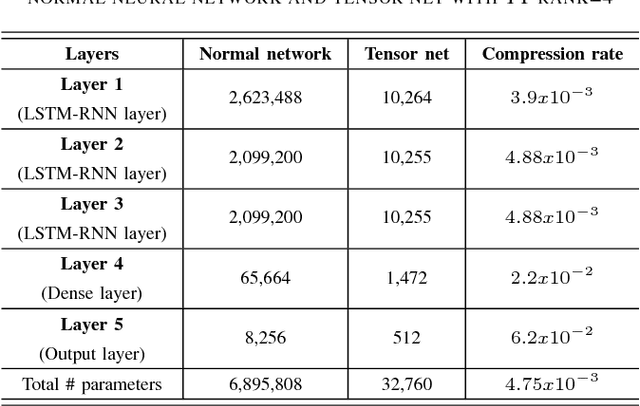
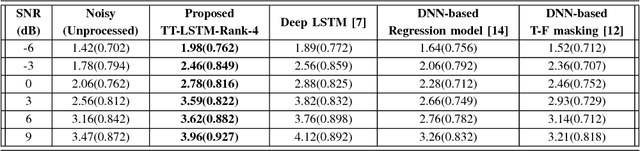
In recent years, Long Short-Term Memory (LSTM) has become a popular choice for speech separation and speech enhancement task. The capability of LSTM network can be enhanced by widening and adding more layers. However, this would introduce millions of parameters in the network and also increase the requirement of computational resources. These limitations hinders the efficient implementation of RNN models in low-end devices such as mobile phones and embedded systems with limited memory. To overcome these issues, we proposed to use an efficient alternative approach of reducing parameters by representing the weight matrix parameters of LSTM based on Tensor-Train (TT) format. We called this Tensor-Train factorized LSTM as TT-LSTM model. Based on this TT-LSTM units, we proposed a deep TensorNet model for single-channel speech enhancement task. Experimental results in various test conditions and in terms of standard speech quality and intelligibility metrics, demonstrated that the proposed deep TT-LSTM based speech enhancement framework can achieve competitive performances with the state-of-the-art uncompressed RNN model, even though the proposed model architecture is orders of magnitude less complex.
Power efficient Spiking Neural Network Classifier based on memristive crossbar network for spike sorting application
Feb 25, 2018
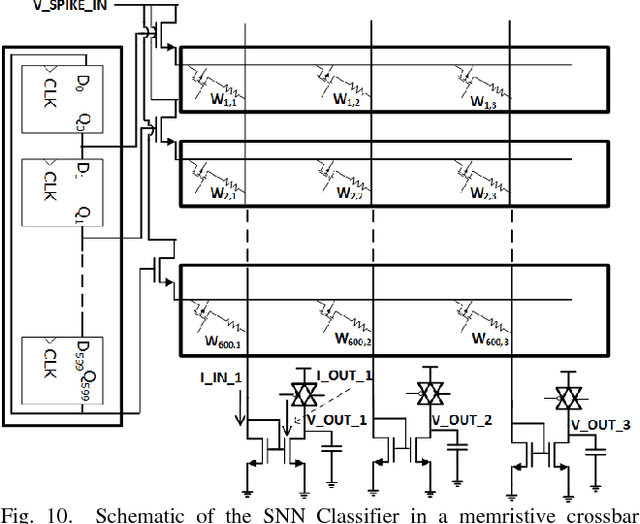
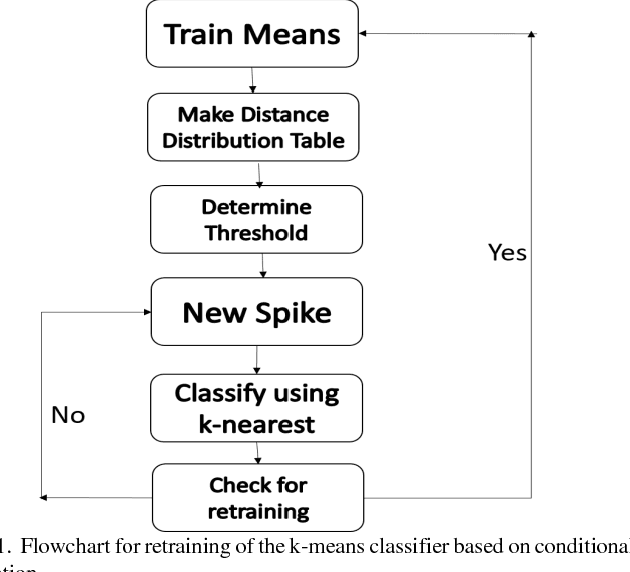

In this paper authors have presented a power efficient scheme for implementing a spike sorting module. Spike sorting is an important application in the field of neural signal acquisition for implantable biomedical systems whose function is to map the Neural-spikes (N-spikes) correctly to the neurons from which it originates. The accurate classification is a pre-requisite for the succeeding systems needed in Brain-Machine-Interfaces (BMIs) to give better performance. The primary design constraint to be satisfied for the spike sorter module is low power with good accuracy. There lies a trade-off in terms of power consumption between the on-chip and off-chip training of the N-spike features. In the former case care has to be taken to make the computational units power efficient whereas in the later the data rate of wireless transmission should be minimized to reduce the power consumption due to the transceivers. In this work a 2-step shared training scheme involving a K-means sorter and a Spiking Neural Network (SNN) is elaborated for on-chip training and classification. Also, a low power SNN classifier scheme using memristive crossbar type architecture is compared with a fully digital implementation. The advantage of the former classifier is that it is power efficient while providing comparable accuracy as that of the digital implementation due to the robustness of the SNN training algorithm which has a good tolerance for variation in memristance.