 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOASI: Objective-Aware Surrogate Initialization for Multi-Objective Bayesian Optimization in TinyML Keyword Spotting
Dec 17, 2025



Voice assistants utilize Keyword Spotting (KWS) to enable efficient, privacy-friendly activation. However, realizing accurate KWS models on ultra-low-power TinyML devices (often with less than $<2$ MB of flash memory) necessitates a delicate balance between accuracy with strict resource constraints. Multi-objective Bayesian Optimization (MOBO) is an ideal candidate for managing such a trade-off but is highly initialization-dependent, especially under the budgeted black-box setting. Existing methods typically fall back to naive, ad-hoc sampling routines (e.g., Latin Hypercube Sampling (LHS), Sobol sequences, or Random search) that are adapted to neither the Pareto front nor undergo rigorous statistical comparison. To address this, we propose Objective-Aware Surrogate Initialization (OASI), a novel initialization strategy that leverages Multi-Objective Simulated Annealing (MOSA) to generate a seed Pareto set of high-performing and diverse configurations that explicitly balance accuracy and model size. Evaluated in a TinyML KWS setting, OASI outperforms LHS, Sobol, and Random initialization, achieving the highest hypervolume (0.0627) and the lowest generational distance (0.0) across multiple runs, with only a modest increase in computation time (1934 s vs. $\sim$1500 s). A non-parametric statistical analysis using the Kruskal-Wallis test ($H = 5.40$, $p = 0.144$, $η^2 = 0.0007$) and Dunn's post-hoc test confirms OASI's superior consistency despite the non-significant overall difference with respect to the $α=0.05$ threshold.
Advances in Small-Footprint Keyword Spotting: A Comprehensive Review of Efficient Models and Algorithms
Jun 12, 2025
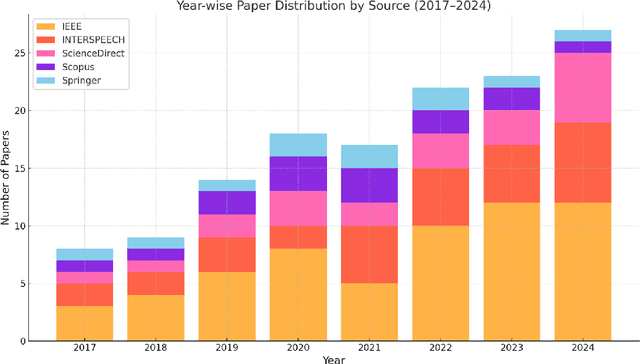
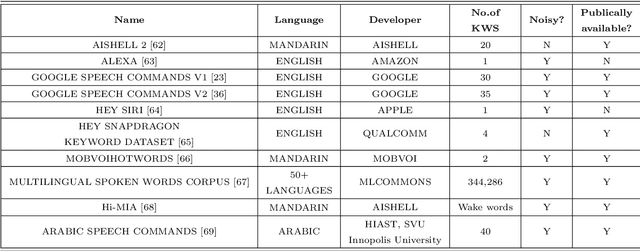
Small-Footprint Keyword Spotting (SF-KWS) has gained popularity in today's landscape of smart voice-activated devices, smartphones, and Internet of Things (IoT) applications. This surge is attributed to the advancements in Deep Learning, enabling the identification of predefined words or keywords from a continuous stream of words. To implement the SF-KWS model on edge devices with low power and limited memory in real-world scenarios, a efficient Tiny Machine Learning (TinyML) framework is essential. In this study, we explore seven distinct categories of techniques namely, Model Architecture, Learning Techniques, Model Compression, Attention Awareness Architecture, Feature Optimization, Neural Network Search, and Hybrid Approaches, which are suitable for developing an SF-KWS system. This comprehensive overview will serve as a valuable resource for those looking to understand, utilize, or contribute to the field of SF-KWS. The analysis conducted in this work enables the identification of numerous potential research directions, encompassing insights from automatic speech recognition research and those specifically pertinent to the realm of spoken SF-KWS.
Towards Power-Efficient Design of Myoelectric Controller based on Evolutionary Computation
Apr 02, 2022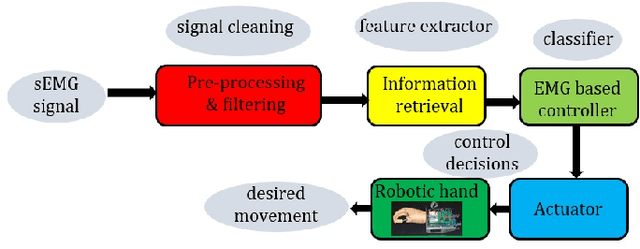
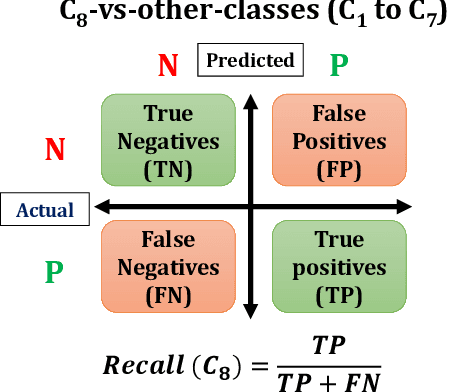
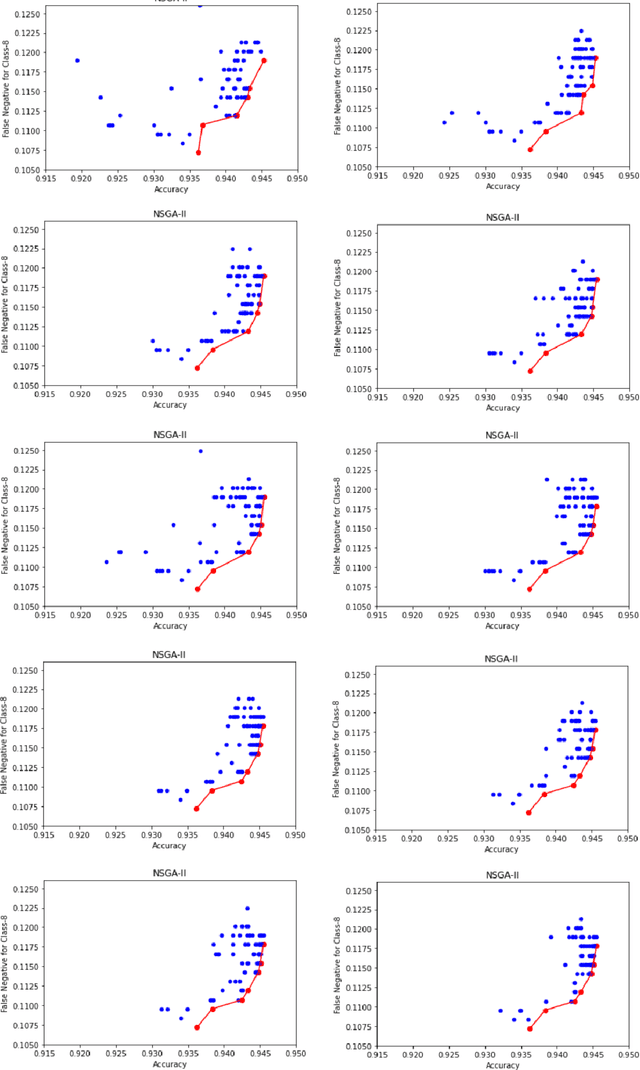
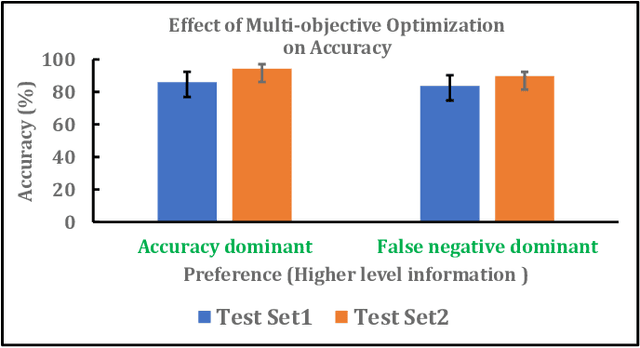
Myoelectric pattern recognition is one of the important aspects in the design of the control strategy for various applications including upper-limb prostheses and bio-robotic hand movement systems. The current work has proposed an approach to design an energy-efficient EMG-based controller by considering a supervised learning framework using a kernelized SVM classifier for decoding the information of surface electromyography (sEMG) signals to infer the underlying muscle movements. In order to achieve the optimized performance of the EMG-based controller, our main strategy of classifier design is to reduce the false movements of the overall system (when the EMG-based controller is at the `Rest' position). To this end, unlike the traditional single training objective of soft margin kernelized SVM, we have formulated the training algorithm of the proposed supervised learning system as a general constrained multi-objective optimization problem. An elitist multi-objective evolutionary algorithm $-$ the non-dominated sorting genetic algorithm II (NSGA-II) has been used for the tuning of SVM hyperparameters. We have presented the experimental results by performing the experiments on a dataset consisting of the sEMG signals collected from eleven subjects at five different upper limb positions. It is evident from the presented result that the proposed approach provides much more flexibility to the designer in selecting the parameters of the classifier to optimize the energy efficiency of the EMG-based controller.
Single-channel speech enhancement by using psychoacoustical model inspired fusion framework
Feb 10, 2022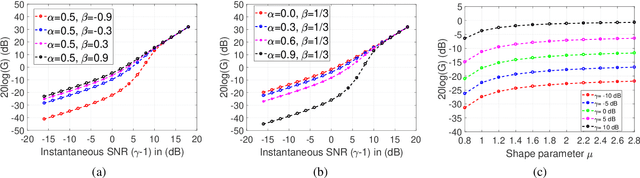
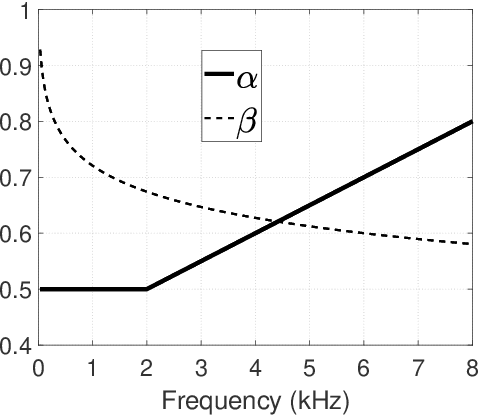
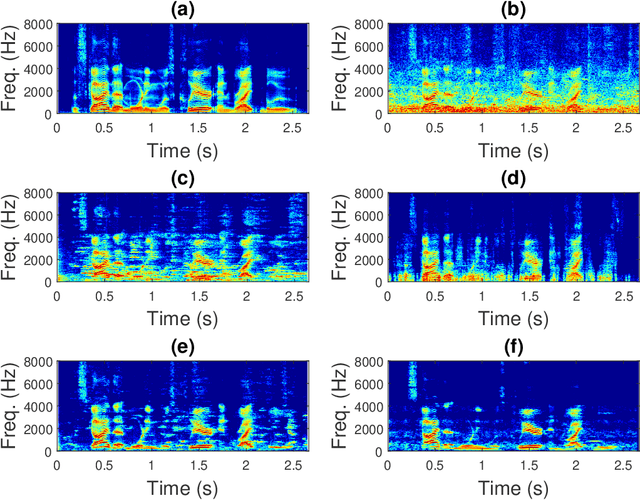
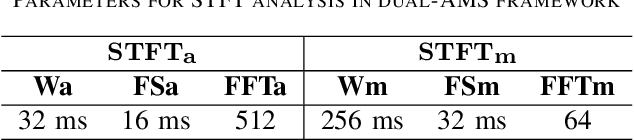
When the parameters of Bayesian Short-time Spectral Amplitude (STSA) estimator for speech enhancement are selected based on the characteristics of the human auditory system, the gain function of the estimator becomes more flexible. Although this type of estimator in acoustic domain is quite effective in reducing the back-ground noise at high frequencies, it produces more speech distortions, which make the high-frequency contents of the speech such as friciatives less perceptible in heavy noise conditions, resulting in intelligibility reduction. On the other hand, the speech enhancement scheme, which exploits the psychoacoustic evidence of frequency selectivity in the modulation domain, is found to be able to increase the intelligibility of noisy speech by a substantial amount, but also suffers from the temporal slurring problem due to its essential design constraint. In order to achieve the joint improvements in both the perceived speech quality and intelligibility, we proposed and investigated a fusion framework by combining the merits of acoustic and modulation domain approaches while avoiding their respective weaknesses. Objective measure evaluation shows that the proposed speech enhancement fusion framework can provide consistent improvements in the perceived speech quality and intelligibility across different SNR levels in various noise conditions, while compared to the other baseline techniques.
Auditory Model based Phase-Aware Bayesian Spectral Amplitude Estimator for Single-Channel Speech Enhancement
Feb 10, 2022
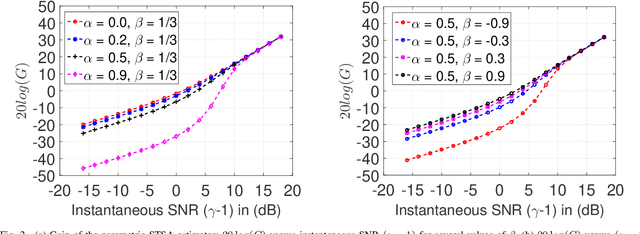
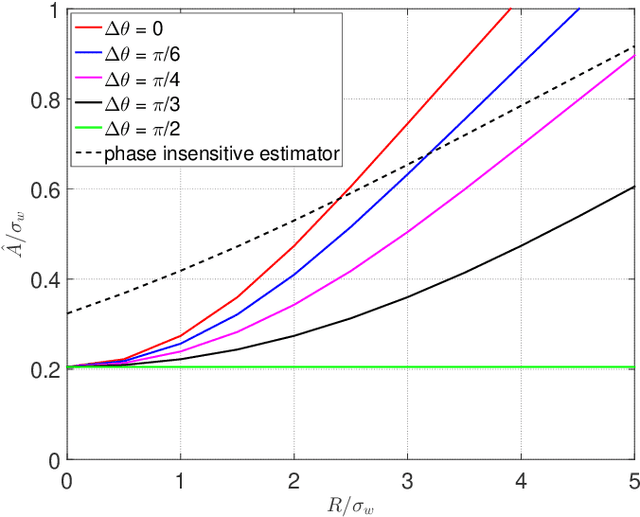
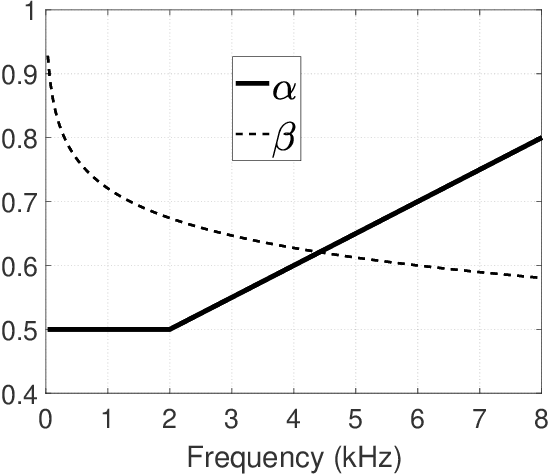
Bayesian estimation of short-time spectral amplitude is one of the most predominant approaches for the enhancement of the noise corrupted speech. The performance of these estimators are usually significantly improved when any perceptually relevant cost function is considered. On the other hand, the recent progress in the phase-based speech signal processing have shown that the phase-only enhancement based on spectral phase estimation methods can also provide joint improvement in the perceived speech quality and intelligibility, even in low SNR conditions. In this paper, to take advantage of both the perceptually motivated cost function involving STSAs of estimated and true clean speech and utilizing the prior spectral phase information, we have derived a phase-aware Bayesian STSA estimator. The parameters of the cost function are chosen based on the characteristics of the human auditory system, namely, the dynamic compressive nonlinearity of the cochlea, the perceived loudness theory and the simultaneous masking properties of the ear. This type of parameter selection scheme results in more noise reduction while limiting the speech distortion. The derived STSA estimator is optimal in the MMSE sense if the prior phase information is available. In practice, however, typically only an estimate of the clean speech phase can be obtained via employing different types of spectral phase estimation techniques which have been developed throughout the last few years. In a blind setup, we have evaluated the proposed Bayesian STSA estimator with different types of standard phase estimation methods available in the literature. Experimental results have shown that the proposed estimator can achieve substantial improvement in performance than the traditional phase-blind approaches.
Tensor-Train Long Short-Term Memory for Monaural Speech Enhancement
Dec 25, 2018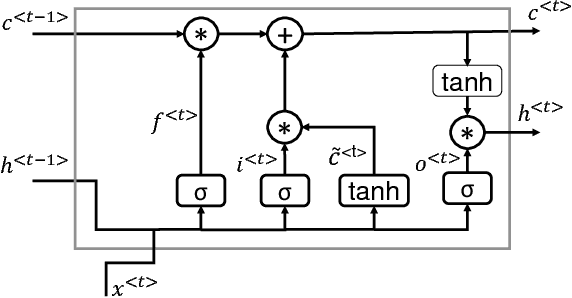
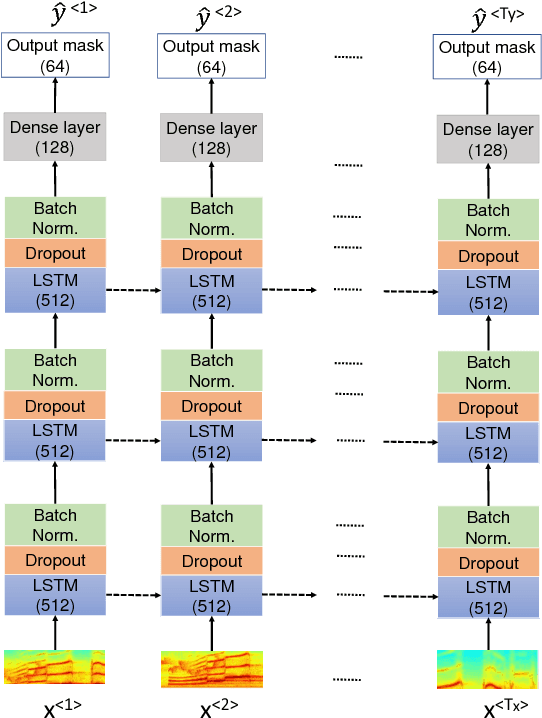
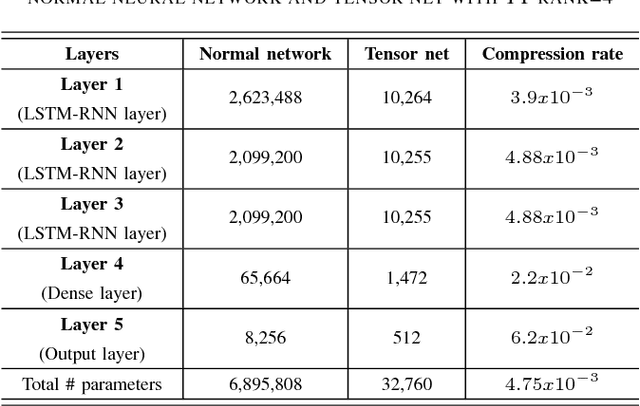
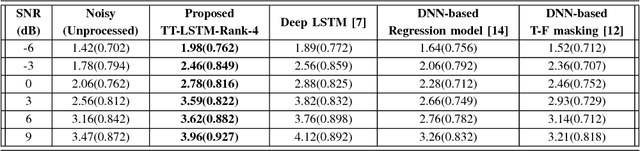
In recent years, Long Short-Term Memory (LSTM) has become a popular choice for speech separation and speech enhancement task. The capability of LSTM network can be enhanced by widening and adding more layers. However, this would introduce millions of parameters in the network and also increase the requirement of computational resources. These limitations hinders the efficient implementation of RNN models in low-end devices such as mobile phones and embedded systems with limited memory. To overcome these issues, we proposed to use an efficient alternative approach of reducing parameters by representing the weight matrix parameters of LSTM based on Tensor-Train (TT) format. We called this Tensor-Train factorized LSTM as TT-LSTM model. Based on this TT-LSTM units, we proposed a deep TensorNet model for single-channel speech enhancement task. Experimental results in various test conditions and in terms of standard speech quality and intelligibility metrics, demonstrated that the proposed deep TT-LSTM based speech enhancement framework can achieve competitive performances with the state-of-the-art uncompressed RNN model, even though the proposed model architecture is orders of magnitude less complex.