 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Inference for Auto-Encoding Variational Bayes
Dec 18, 2017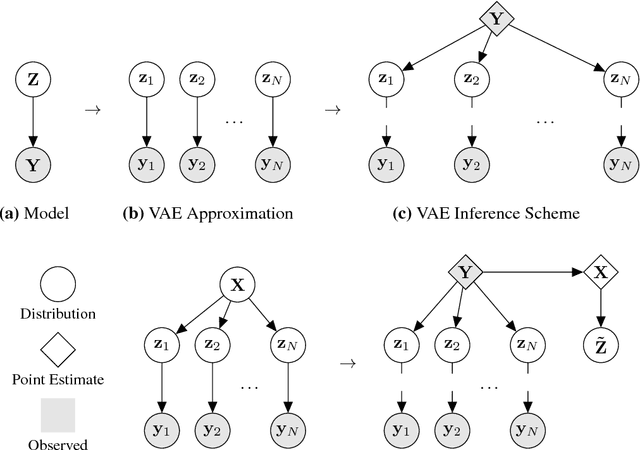
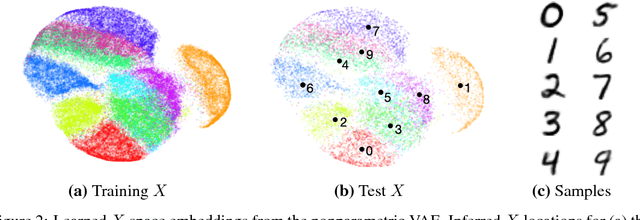
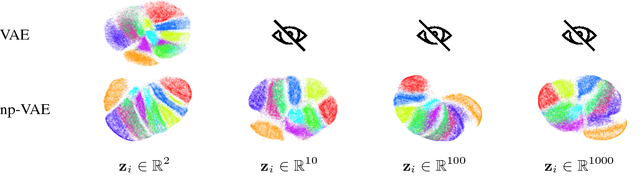

We would like to learn latent representations that are low-dimensional and highly interpretable. A model that has these characteristics is the Gaussian Process Latent Variable Model. The benefits and negative of the GP-LVM are complementary to the Variational Autoencoder, the former provides interpretable low-dimensional latent representations while the latter is able to handle large amounts of data and can use non-Gaussian likelihoods. Our inspiration for this paper is to marry these two approaches and reap the benefits of both. In order to do so we will introduce a novel approximate inference scheme inspired by the GP-LVM and the VAE. We show experimentally that the approximation allows the capacity of the generative bottle-neck (Z) of the VAE to be arbitrarily large without losing a highly interpretable representation, allowing reconstruction quality to be unlimited by Z at the same time as a low-dimensional space can be used to perform ancestral sampling from as well as a means to reason about the embedded data.
Neural Translation of Musical Style
Aug 11, 2017
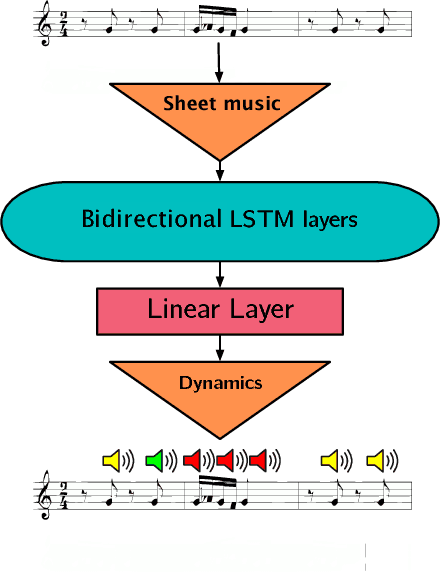
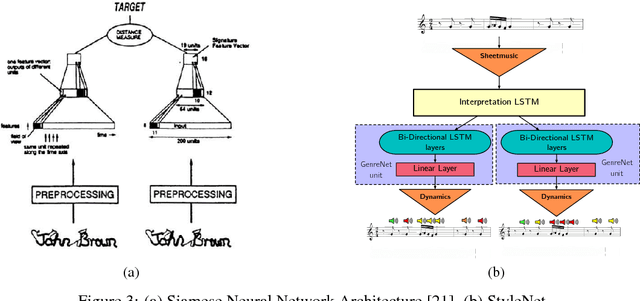
Music is an expressive form of communication often used to convey emotion in scenarios where "words are not enough". Part of this information lies in the musical composition where well-defined language exists. However, a significant amount of information is added during a performance as the musician interprets the composition. The performer injects expressiveness into the written score through variations of different musical properties such as dynamics and tempo. In this paper, we describe a model that can learn to perform sheet music. Our research concludes that the generated performances are indistinguishable from a human performance, thereby passing a test in the spirit of a "musical Turing test".