 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow well can VLMs rate audio descriptions: A multi-dimensional quantitative assessment framework
Feb 01, 2026Digital video is central to communication, education, and entertainment, but without audio description (AD), blind and low-vision audiences are excluded. While crowdsourced platforms and vision-language-models (VLMs) expand AD production, quality is rarely checked systematically. Existing evaluations rely on NLP metrics and short-clip guidelines, leaving questions about what constitutes quality for full-length content and how to assess it at scale. To address these questions, we first developed a multi-dimensional assessment framework for uninterrupted, full-length video, grounded in professional guidelines and refined by accessibility specialists. Second, we integrated this framework into a comprehensive methodological workflow, utilizing Item Response Theory, to assess the proficiency of VLM and human raters against expert-established ground truth. Findings suggest that while VLMs can approximate ground-truth ratings with high alignment, their reasoning was found to be less reliable and actionable than that of human respondents. These insights show the potential of hybrid evaluation systems that leverage VLMs alongside human oversight, offering a path towards scalable AD quality control.
NarrationBot and InfoBot: A Hybrid System for Automated Video Description
Nov 07, 2021
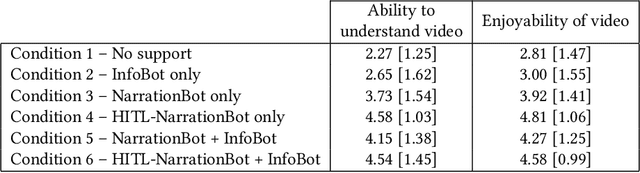


Video accessibility is crucial for blind and low vision users for equitable engagements in education, employment, and entertainment. Despite the availability of professional and amateur services and tools, most human-generated descriptions are expensive and time consuming. Moreover, the rate of human-generated descriptions cannot match the speed of video production. To overcome the increasing gaps in video accessibility, we developed a hybrid system of two tools to 1) automatically generate descriptions for videos and 2) provide answers or additional descriptions in response to user queries on a video. Results from a mixed-methods study with 26 blind and low vision individuals show that our system significantly improved user comprehension and enjoyment of selected videos when both tools were used in tandem. In addition, participants reported no significant difference in their ability to understand videos when presented with autogenerated descriptions versus human-revised autogenerated descriptions. Our results demonstrate user enthusiasm about the developed system and its promise for providing customized access to videos. We discuss the limitations of the current work and provide recommendations for the future development of automated video description tools.