 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multi-level convolutional LSTM model for the segmentation of left ventricle myocardium in infarcted porcine cine MR images
Nov 14, 2018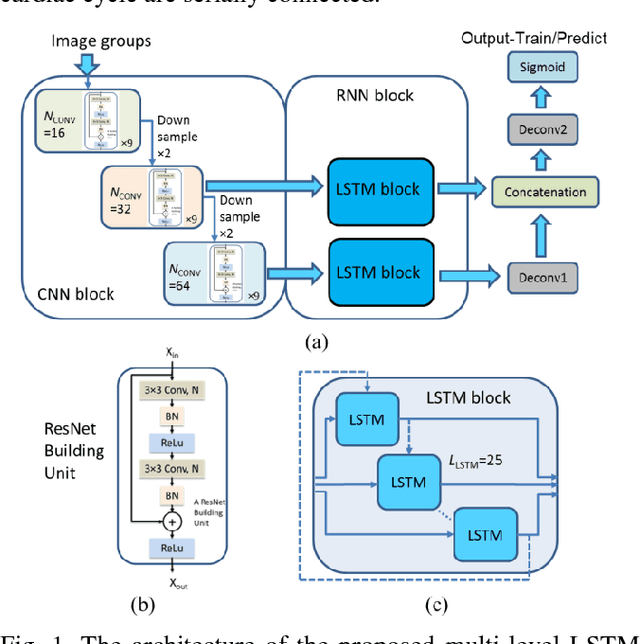
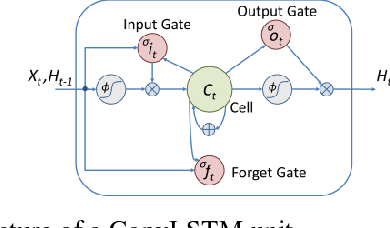
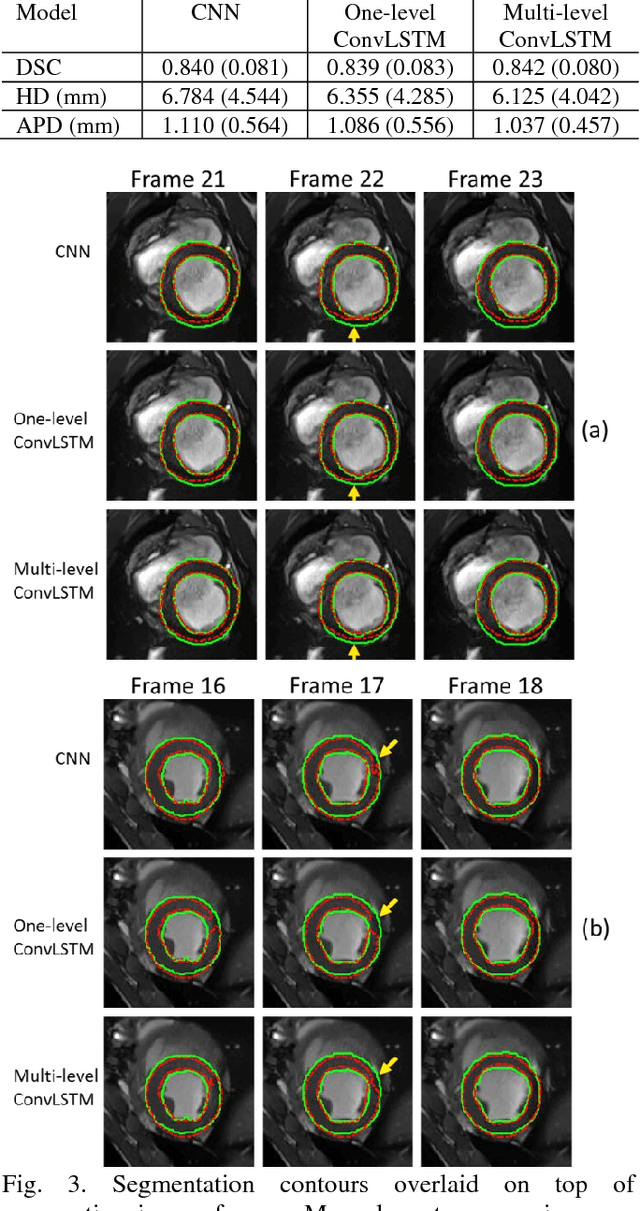
Automatic segmentation of left ventricle (LV) myocardium in cardiac short-axis cine MR images acquired on subjects with myocardial infarction is a challenging task, mainly because of the various types of image inhomogeneity caused by the infarctions. Among the approaches proposed to automate the LV myocardium segmentation task, methods based upon deep convolutional neural networks (CNN) have demonstrated their exceptional accuracy and robustness in recent years. However, most of the CNN-based approaches treat the frames in a cardiac cycle independently, which fails to capture the valuable dynamics of heart motion. Herein, an approach based on recurrent neural network (RNN), specifically a multi-level convolutional long short-term memory (ConvLSTM) model, is proposed to take the motion of the heart into consideration. Based on a ResNet-56 CNN, LV-related image features in consecutive frames of a cardiac cycle are extracted at both the low- and high-resolution levels, which are processed by the corresponding multi-level ConvLSTM models to generate the myocardium segmentations. A leave-one-out experiment was carried out on a set of 3,600 cardiac cine MR slices collected in-house for 8 porcine subjects with surgically induced myocardial infarction. Compared with a solely CNN-based approach, the proposed approach demonstrated its superior robustness against image inhomogeneity by incorporating information from adjacent frames. It also outperformed a one-level ConvLSTM approach thanks to its capabilities to take advantage of image features at multiple resolution levels.
Visual and semantic interpretability of projections of high dimensional data for classification tasks
May 22, 2012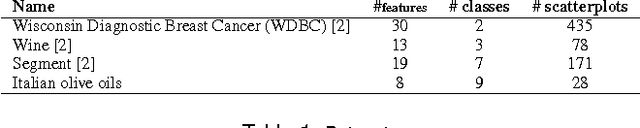
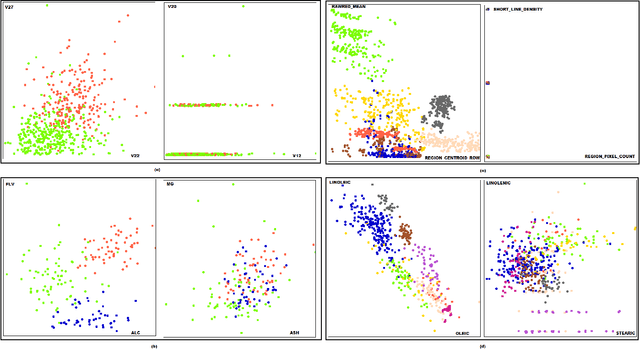

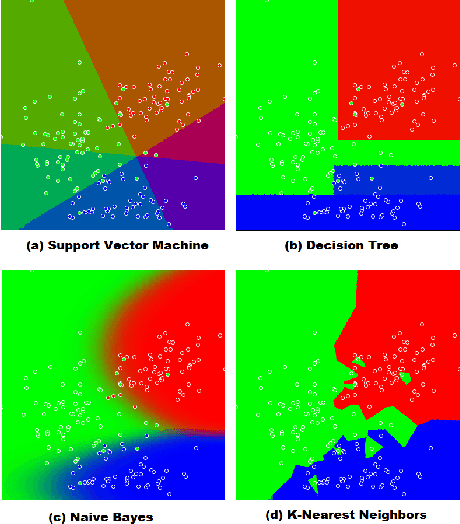
A number of visual quality measures have been introduced in visual analytics literature in order to automatically select the best views of high dimensional data from a large number of candidate data projections. These methods generally concentrate on the interpretability of the visualization and pay little attention to the interpretability of the projection axes. In this paper, we argue that interpretability of the visualizations and the feature transformation functions are both crucial for visual exploration of high dimensional labeled data. We present a two-part user study to examine these two related but orthogonal aspects of interpretability. We first study how humans judge the quality of 2D scatterplots of various datasets with varying number of classes and provide comparisons with ten automated measures, including a number of visual quality measures and related measures from various machine learning fields. We then investigate how the user perception on interpretability of mathematical expressions relate to various automated measures of complexity that can be used to characterize data projection functions. We conclude with a discussion of how automated measures of visual and semantic interpretability of data projections can be used together for exploratory analysis in classification tasks.
Multi-Objective Genetic Programming Projection Pursuit for Exploratory Data Modeling
Oct 10, 2010
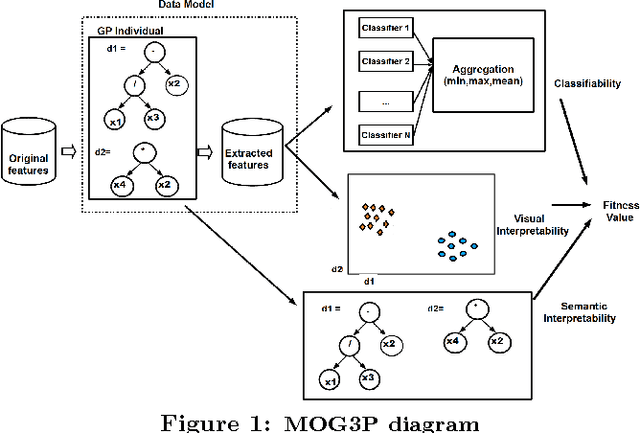
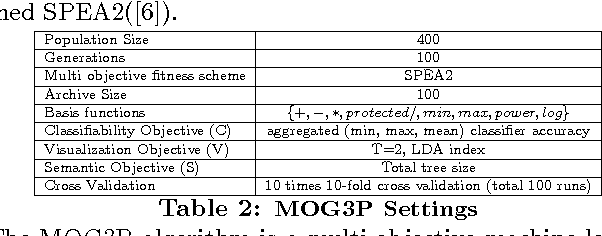
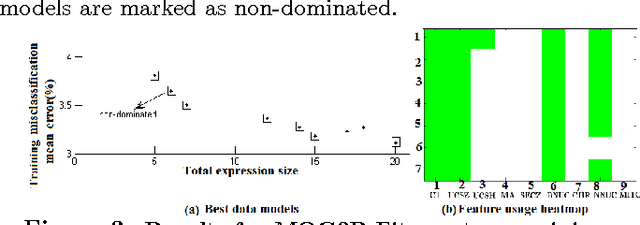
For classification problems, feature extraction is a crucial process which aims to find a suitable data representation that increases the performance of the machine learning algorithm. According to the curse of dimensionality theorem, the number of samples needed for a classification task increases exponentially as the number of dimensions (variables, features) increases. On the other hand, it is costly to collect, store and process data. Moreover, irrelevant and redundant features might hinder classifier performance. In exploratory analysis settings, high dimensionality prevents the users from exploring the data visually. Feature extraction is a two-step process: feature construction and feature selection. Feature construction creates new features based on the original features and feature selection is the process of selecting the best features as in filter, wrapper and embedded methods. In this work, we focus on feature construction methods that aim to decrease data dimensionality for visualization tasks. Various linear (such as principal components analysis (PCA), multiple discriminants analysis (MDA), exploratory projection pursuit) and non-linear (such as multidimensional scaling (MDS), manifold learning, kernel PCA/LDA, evolutionary constructive induction) techniques have been proposed for dimensionality reduction. Our algorithm is an adaptive feature extraction method which consists of evolutionary constructive induction for feature construction and a hybrid filter/wrapper method for feature selection.