 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Random Forest approach to detect and identify Unlawful Insider Trading
Nov 09, 2024According to The Exchange Act, 1934 unlawful insider trading is the abuse of access to privileged corporate information. While a blurred line between "routine" the "opportunistic" insider trading exists, detection of strategies that insiders mold to maneuver fair market prices to their advantage is an uphill battle for hand-engineered approaches. In the context of detailed high-dimensional financial and trade data that are structurally built by multiple covariates, in this study, we explore, implement and provide detailed comparison to the existing study (Deng et al. (2019)) and independently implement automated end-to-end state-of-art methods by integrating principal component analysis to the random forest (PCA-RF) followed by a standalone random forest (RF) with 320 and 3984 randomly selected, semi-manually labeled and normalized transactions from multiple industry. The settings successfully uncover latent structures and detect unlawful insider trading. Among the multiple scenarios, our best-performing model accurately classified 96.43 percent of transactions. Among all transactions the models find 95.47 lawful as lawful and $98.00$ unlawful as unlawful percent. Besides, the model makes very few mistakes in classifying lawful as unlawful by missing only 2.00 percent. In addition to the classification task, model generated Gini Impurity based features ranking, our analysis show ownership and governance related features based on permutation values play important roles. In summary, a simple yet powerful automated end-to-end method relieves labor-intensive activities to redirect resources to enhance rule-making and tracking the uncaptured unlawful insider trading transactions. We emphasize that developed financial and trading features are capable of uncovering fraudulent behaviors.
The Application of Affective Measures in Text-based Emotion Aware Recommender Systems
May 04, 2023This paper presents an innovative approach to address the problems researchers face in Emotion Aware Recommender Systems (EARS): the difficulty and cumbersome collecting voluminously good quality emotion-tagged datasets and an effective way to protect users' emotional data privacy. Without enough good-quality emotion-tagged datasets, researchers cannot conduct repeatable affective computing research in EARS that generates personalized recommendations based on users' emotional preferences. Similarly, if we fail to fully protect users' emotional data privacy, users could resist engaging with EARS services. This paper introduced a method that detects affective features in subjective passages using the Generative Pre-trained Transformer Technology, forming the basis of the Affective Index and Affective Index Indicator (AII). Eliminate the need for users to build an affective feature detection mechanism. The paper advocates for a separation of responsibility approach where users protect their emotional profile data while EARS service providers refrain from retaining or storing it. Service providers can update users' Affective Indices in memory without saving their privacy data, providing Affective Aware recommendations without compromising user privacy. This paper offers a solution to the subjectivity and variability of emotions, data privacy concerns, and evaluation metrics and benchmarks, paving the way for future EARS research.
An Affective Aware Pseudo Association Method to Connect Disjoint Users Across Multiple Datasets -- An Enhanced Validation Method for Text-based Emotion Aware Recommender
Feb 10, 2021
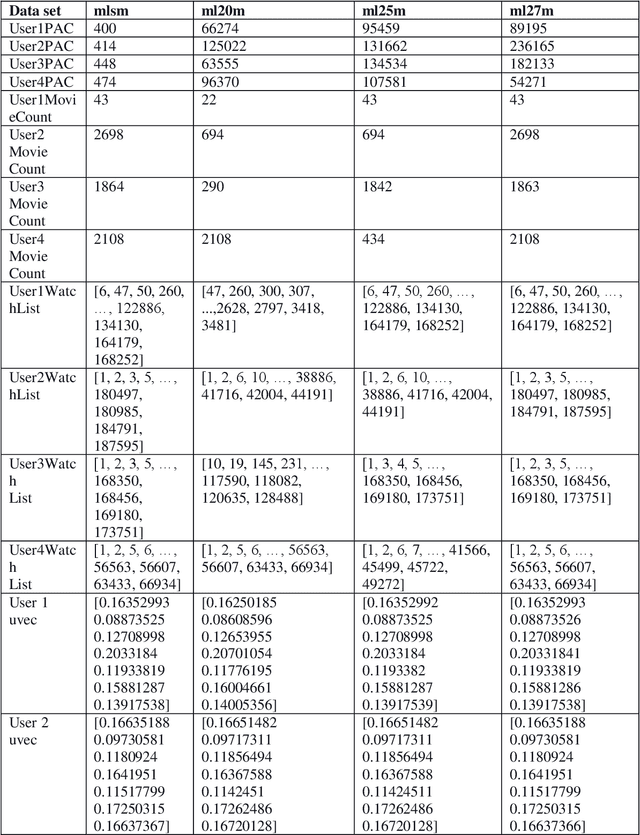
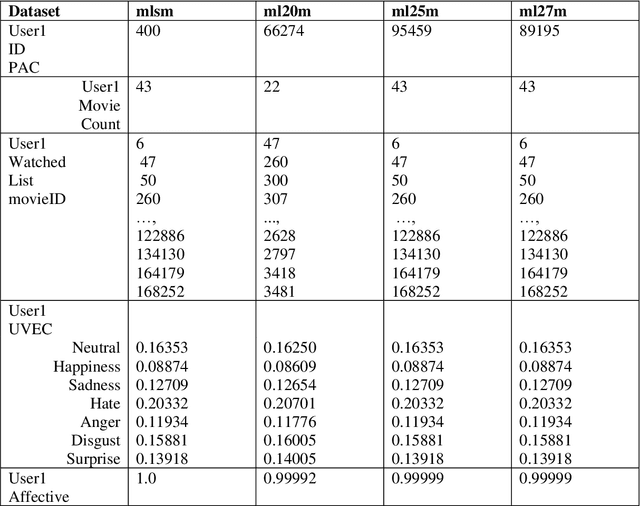
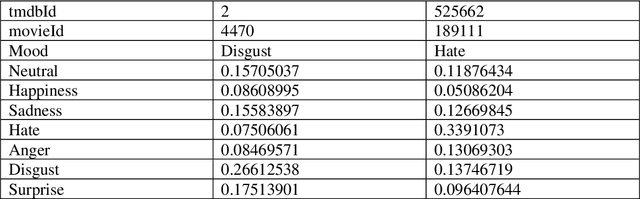
We derive a method to enhance the evaluation for a text-based Emotion Aware Recommender that we have developed. However, we did not implement a suitable way to assess the top-N recommendations subjectively. In this study, we introduce an emotion-aware Pseudo Association Method to interconnect disjointed users across different datasets so data files can be combined to form a more extensive data file. Users with the same user IDs found in separate data files in the same dataset are often the same users. However, users with the same user ID may not be the same user across different datasets. We advocate an emotion aware Pseudo Association Method to associate users across different datasets. The approach interconnects users with different user IDs across different datasets through the most similar users' emotion vectors (UVECs). We found the method improved the evaluation process of assessing the top-N recommendations objectively.
* 21 pages, 9 tables. arXiv admin note: substantial text overlap with arXiv:2007.01455
Applying the Affective Aware Pseudo Association Method to Enhance the Top-N Recommendations Distribution to Users in Group Emotion Recommender Systems
Feb 08, 2021

Recommender Systems are a subclass of information retrieval systems, or more succinctly, a class of information filtering systems that seeks to predict how close is the match of the user's preference to a recommended item. A common approach for making recommendations for a user group is to extend Personalized Recommender Systems' capability. This approach gives the impression that group recommendations are retrofits of the Personalized Recommender Systems. Moreover, such an approach not taken the dynamics of group emotion and individual emotion into the consideration in making top_N recommendations. Recommending items to a group of two or more users has certainly raised unique challenges in group behaviors that influence group decision-making that researchers only partially understand. This study applies the Affective Aware Pseudo Association Method in studying group formation and dynamics in group decision-making. The method shows its adaptability to group's moods change when making recommendations.
Unsupervised Selective Manifold Regularized Matrix Factorization
Oct 20, 2020
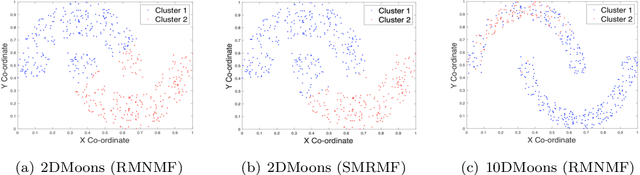

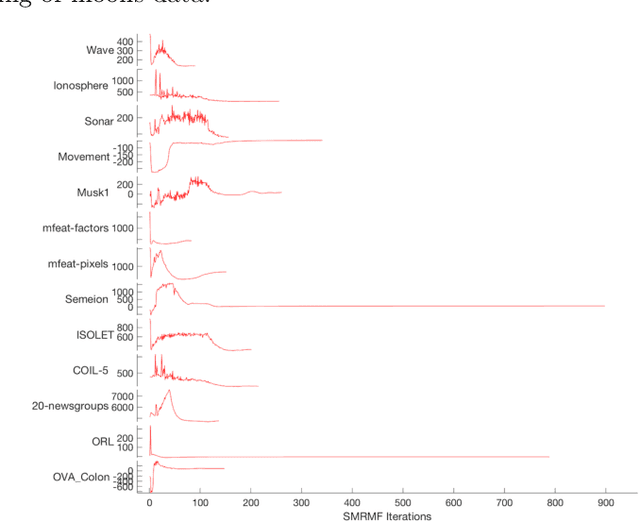
Manifold regularization methods for matrix factorization rely on the cluster assumption, whereby the neighborhood structure of data in the input space is preserved in the factorization space. We argue that using the k-neighborhoods of all data points as regularization constraints can negatively affect the quality of the factorization, and propose an unsupervised and selective regularized matrix factorization algorithm to tackle this problem. Our approach jointly learns a sparse set of representatives and their neighbor affinities, and the data factorization. We further propose a fast approximation of our approach by relaxing the selectivity constraints on the data. Our proposed algorithms are competitive against baselines and state-of-the-art manifold regularization and clustering algorithms.