 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Combinatorial Optimization Model Using Learning-to-Rank Distillation
Dec 24, 2021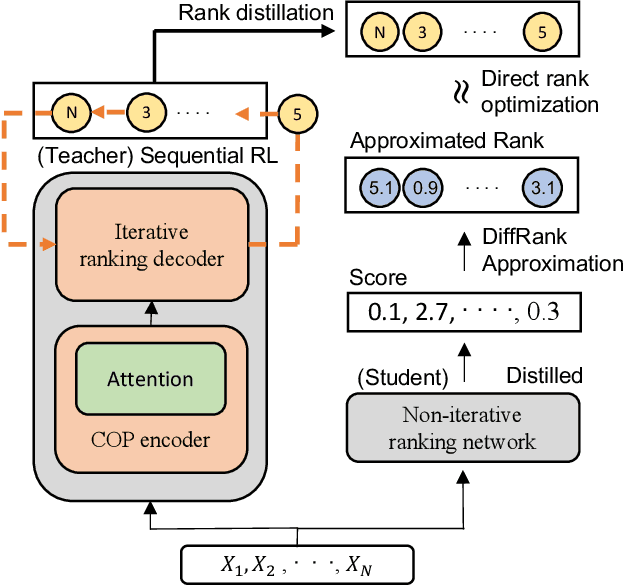
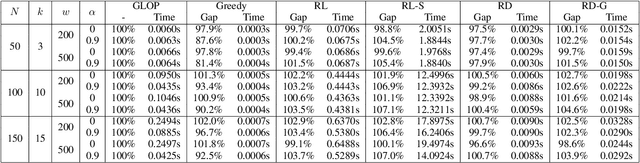
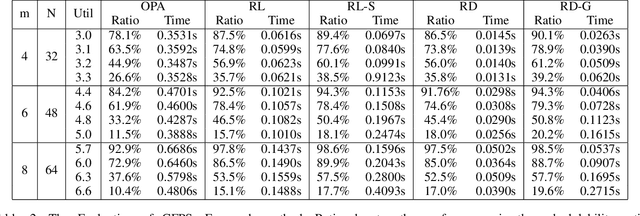
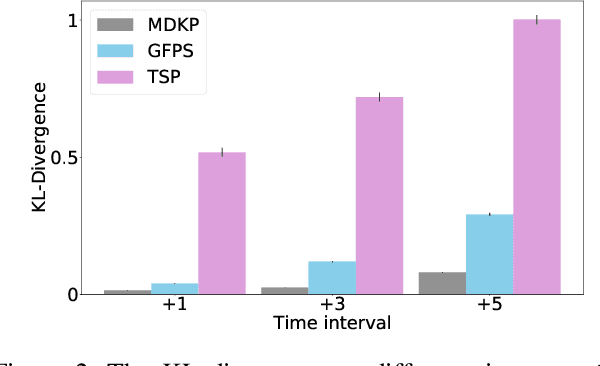
Recently, deep reinforcement learning (RL) has proven its feasibility in solving combinatorial optimization problems (COPs). The learning-to-rank techniques have been studied in the field of information retrieval. While several COPs can be formulated as the prioritization of input items, as is common in the information retrieval, it has not been fully explored how the learning-to-rank techniques can be incorporated into deep RL for COPs. In this paper, we present the learning-to-rank distillation-based COP framework, where a high-performance ranking policy obtained by RL for a COP can be distilled into a non-iterative, simple model, thereby achieving a low-latency COP solver. Specifically, we employ the approximated ranking distillation to render a score-based ranking model learnable via gradient descent. Furthermore, we use the efficient sequence sampling to improve the inference performance with a limited delay. With the framework, we demonstrate that a distilled model not only achieves comparable performance to its respective, high-performance RL, but also provides several times faster inferences. We evaluate the framework with several COPs such as priority-based task scheduling and multidimensional knapsack, demonstrating the benefits of the framework in terms of inference latency and performance.
Fixed Priority Global Scheduling from a Deep Learning Perspective
Dec 14, 2020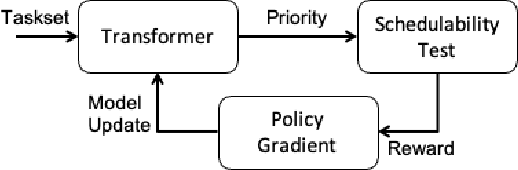
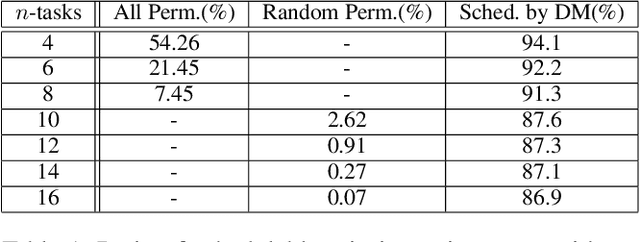
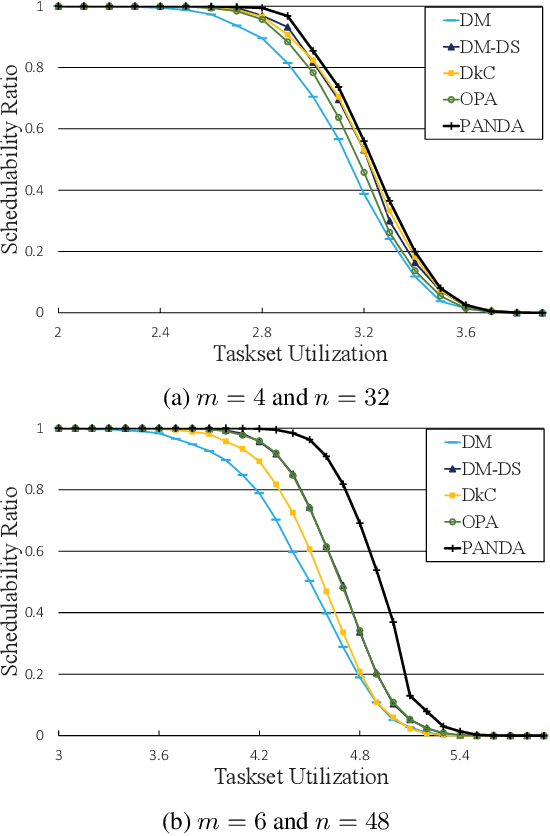
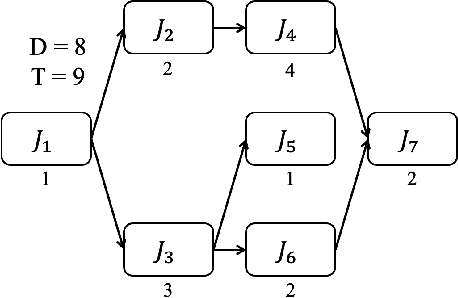
Deep Learning has been recently recognized as one of the feasible solutions to effectively address combinatorial optimization problems, which are often considered important yet challenging in various research domains. In this work, we first present how to adopt Deep Learning for real-time task scheduling through our preliminary work upon fixed priority global scheduling (FPGS) problems. We then briefly discuss possible generalizations of Deep Learning adoption for several realistic and complicated FPGS scenarios, e.g., scheduling tasks with dependency, mixed-criticality task scheduling. We believe that there are many opportunities for leveraging advanced Deep Learning technologies to improve the quality of scheduling in various system configurations and problem scenarios.
A Differentiable Ranking Metric Using Relaxed Sorting Opeartion for Top-K Recommender Systems
Sep 03, 2020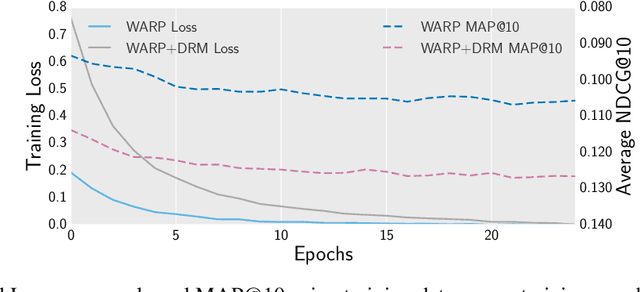
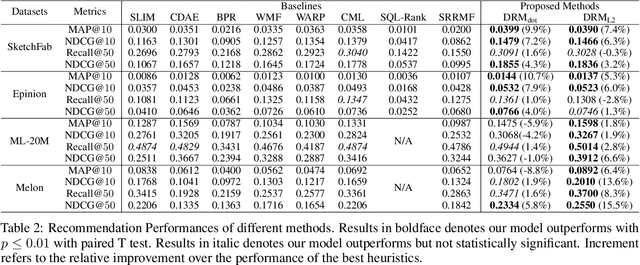
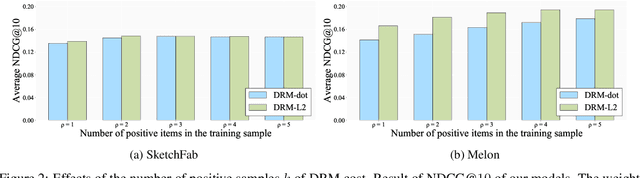
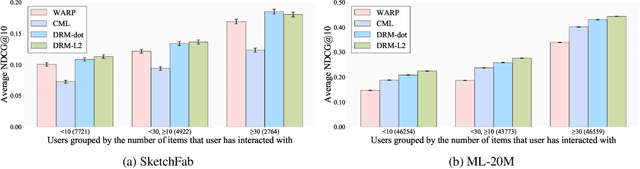
A recommender system generates personalized recommendations for a user by computing the preference score of items, sorting the items according to the score, and filtering the top-Kitemswith high scores. While sorting and ranking items are integral for this recommendation procedure,it is nontrivial to incorporate them in the process of end-to-end model training since sorting is non-differentiable and hard to optimize with gradient-based updates. This incurs the inconsistency issue between the existing learning objectives and ranking-based evaluation metrics of recommendation models. In this work, we present DRM (differentiable ranking metric) that mitigates the inconsistency and improves recommendation performance, by employing the differentiable relaxation of ranking-based evaluation metrics. Via experiments with several real-world datasets, we demonstrate that the joint learning of the DRM cost function upon existing factor based recommendation models significantly improves the quality of recommendations, in comparison with other state-of-the-art recommendation methods.
Intelligent Replication Management for HDFS Using Reinforcement Learning
Aug 19, 2020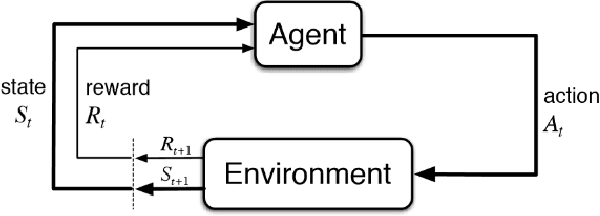
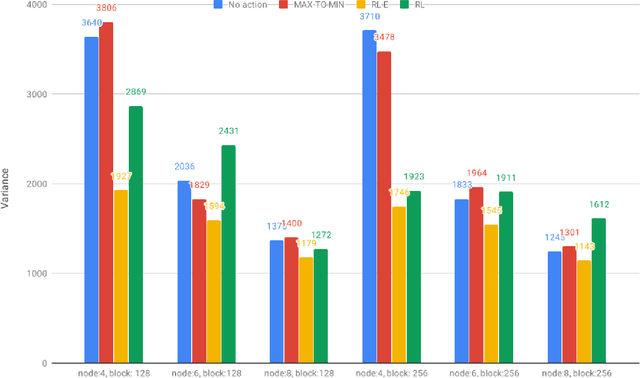
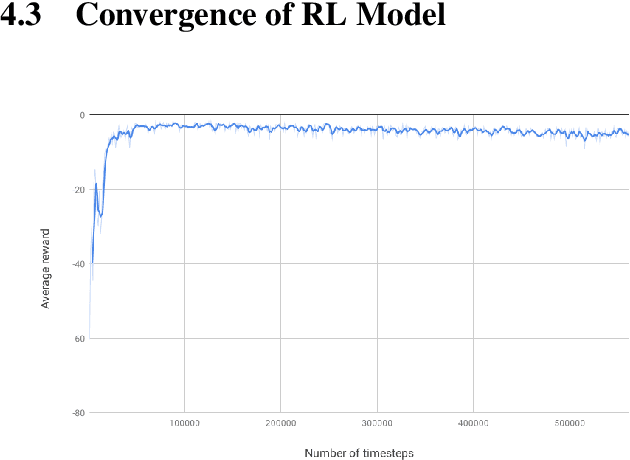
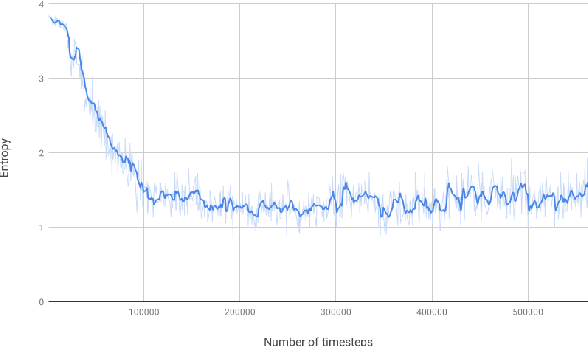
Storage systems for cloud computing merge a large number of commodity computers into a single large storage pool. It provides high-performance storage over an unreliable, and dynamic network at a lower cost than purchasing and maintaining large mainframe. In this paper, we examine whether it is feasible to apply Reinforcement Learning(RL) to system domain problems. Our experiments show that the RL model is comparable, even outperform other heuristics for block management problem. However, our experiments are limited in terms of scalability and fidelity. Even though our formulation is not very practical,applying Reinforcement Learning to system domain could offer good alternatives to existing heuristics.