 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction Loss Guided Decision-Focused Learning
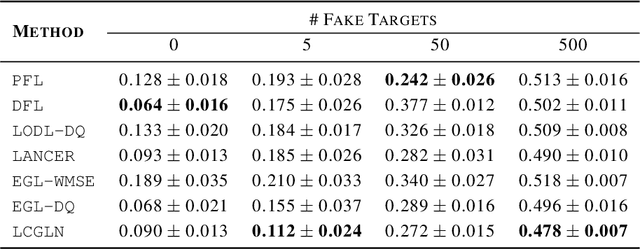
Sep 10, 2025Decision-making under uncertainty is often considered in two stages: predicting the unknown parameters, and then optimizing decisions based on predictions. While traditional prediction-focused learning (PFL) treats these two stages separately, decision-focused learning (DFL) trains the predictive model by directly optimizing the decision quality in an end-to-end manner. However, despite using exact or well-approximated gradients, vanilla DFL often suffers from unstable convergence due to its flat-and-sharp loss landscapes. In contrast, PFL yields more stable optimization, but overlooks the downstream decision quality. To address this, we propose a simple yet effective approach: perturbing the decision loss gradient using the prediction loss gradient to construct an update direction. Our method requires no additional training and can be integrated with any DFL solvers. Using the sigmoid-like decaying parameter, we let the prediction loss gradient guide the decision loss gradient to train a predictive model that optimizes decision quality. Also, we provide a theoretical convergence guarantee to Pareto stationary point under mild assumptions. Empirically, we demonstrate our method across three stochastic optimization problems, showing promising results compared to other baselines. We validate that our approach achieves lower regret with more stable training, even in situations where either PFL or DFL struggles.
Transformer-based Stagewise Decomposition for Large-Scale Multistage Stochastic Optimization
Apr 03, 2024Solving large-scale multistage stochastic programming (MSP) problems poses a significant challenge as commonly used stagewise decomposition algorithms, including stochastic dual dynamic programming (SDDP), face growing time complexity as the subproblem size and problem count increase. Traditional approaches approximate the value functions as piecewise linear convex functions by incrementally accumulating subgradient cutting planes from the primal and dual solutions of stagewise subproblems. Recognizing these limitations, we introduce TranSDDP, a novel Transformer-based stagewise decomposition algorithm. This innovative approach leverages the structural advantages of the Transformer model, implementing a sequential method for integrating subgradient cutting planes to approximate the value function. Through our numerical experiments, we affirm TranSDDP's effectiveness in addressing MSP problems. It efficiently generates a piecewise linear approximation for the value function, significantly reducing computation time while preserving solution quality, thus marking a promising progression in the treatment of large-scale multistage stochastic programming problems.
ICLN: Input Convex Loss Network for Decision Focused Learning
Mar 04, 2024


In decision-making problem under uncertainty, predicting unknown parameters is often considered independent of the optimization part. Decision-focused Learning (DFL) is a task-oriented framework to integrate prediction and optimization by adapting predictive model to give better decision for the corresponding task. Here, an inevitable challenge arises when computing gradients of the optimal decision with respect to the parameters. Existing researches cope this issue by smoothly reforming surrogate optimization or construct surrogate loss function that mimic task loss. However, they are applied to restricted optimization domain or build functions in a local manner leading a large computational time. In this paper, we propose Input Convex Loss Network (ICLN), a novel global surrogate loss which can be implemented in a general DFL paradigm. ICLN learns task loss via Input Convex Neural Networks which is guaranteed to be convex for some inputs, while keeping the global structure for the other inputs. This enables ICLN to admit general DFL through only a single surrogate loss without any sense for choosing appropriate parametric forms. We confirm effectiveness and flexibility of ICLN by evaluating our proposed model with three stochastic decision-making problems.