 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA VAE-based Framework for Learning Multi-Level Neural Granger-Causal Connectivity
Feb 25, 2024
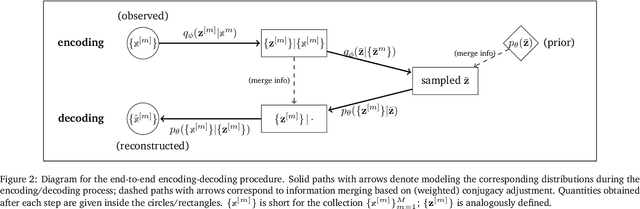
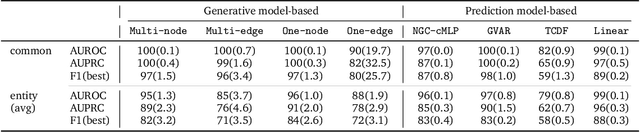
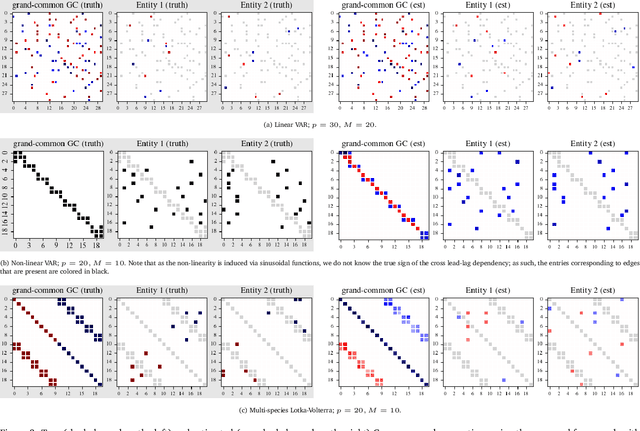
Granger causality has been widely used in various application domains to capture lead-lag relationships amongst the components of complex dynamical systems, and the focus in extant literature has been on a single dynamical system. In certain applications in macroeconomics and neuroscience, one has access to data from a collection of related such systems, wherein the modeling task of interest is to extract the shared common structure that is embedded across them, as well as to identify the idiosyncrasies within individual ones. This paper introduces a Variational Autoencoder (VAE) based framework that jointly learns Granger-causal relationships amongst components in a collection of related-yet-heterogeneous dynamical systems, and handles the aforementioned task in a principled way. The performance of the proposed framework is evaluated on several synthetic data settings and benchmarked against existing approaches designed for individual system learning. The method is further illustrated on a real dataset involving time series data from a neurophysiological experiment and produces interpretable results.
An Actor-Critic Contextual Bandit Algorithm for Personalized Mobile Health Interventions
Jun 28, 2017
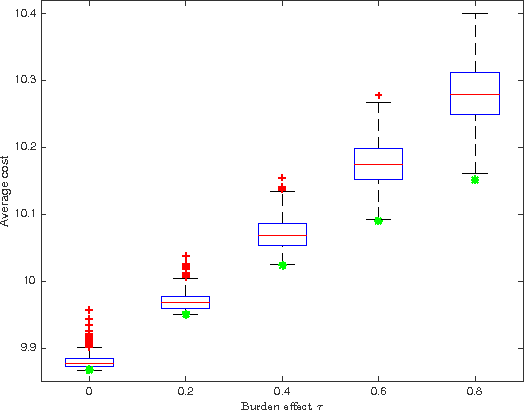
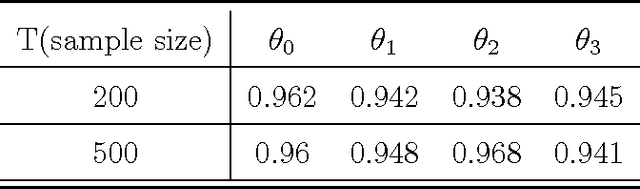
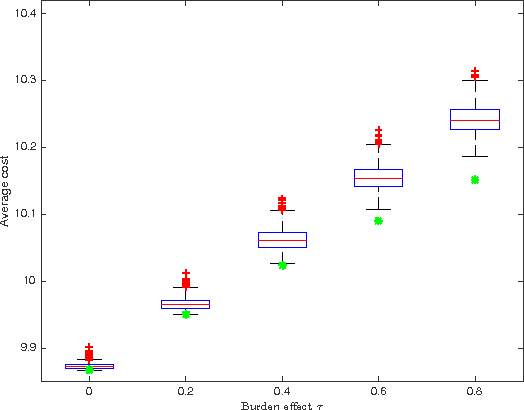
Increasing technological sophistication and widespread use of smartphones and wearable devices provide opportunities for innovative and highly personalized health interventions. A Just-In-Time Adaptive Intervention (JITAI) uses real-time data collection and communication capabilities of modern mobile devices to deliver interventions in real-time that are adapted to the in-the-moment needs of the user. The lack of methodological guidance in constructing data-based JITAIs remains a hurdle in advancing JITAI research despite the increasing popularity of JITAIs among clinical scientists. In this article, we make a first attempt to bridge this methodological gap by formulating the task of tailoring interventions in real-time as a contextual bandit problem. Interpretability requirements in the domain of mobile health lead us to formulate the problem differently from existing formulations intended for web applications such as ad or news article placement. Under the assumption of linear reward function, we choose the reward function (the "critic") parameterization separately from a lower dimensional parameterization of stochastic policies (the "actor"). We provide an online actor-critic algorithm that guides the construction and refinement of a JITAI. Asymptotic properties of the actor-critic algorithm are developed and backed up by numerical experiments. Additional numerical experiments are conducted to test the robustness of the algorithm when idealized assumptions used in the analysis of contextual bandit algorithm are breached.