 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Sentiment Analysis with Bimodal Information-augmented Multi-Head Attention
Mar 09, 2021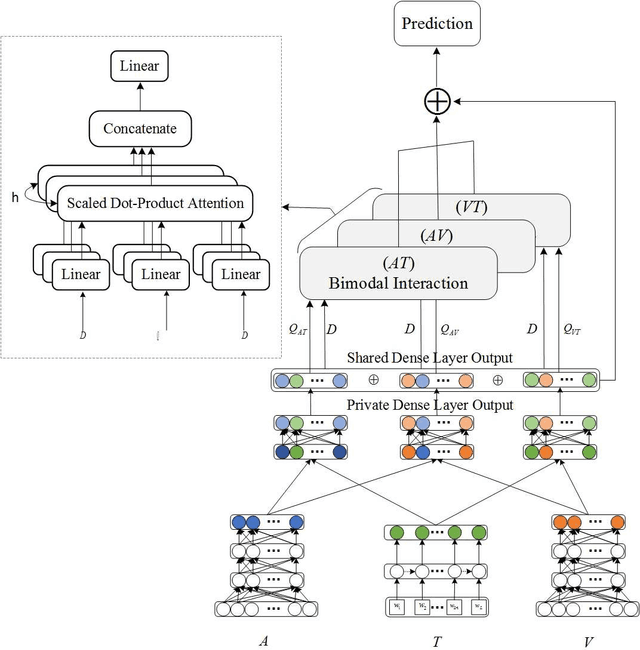
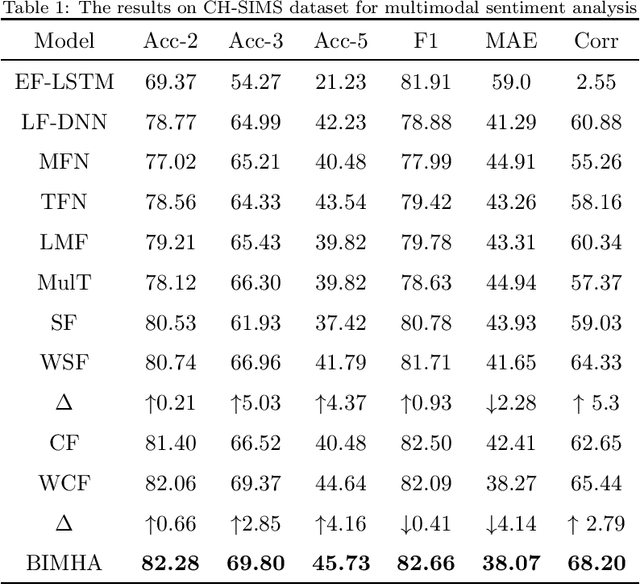
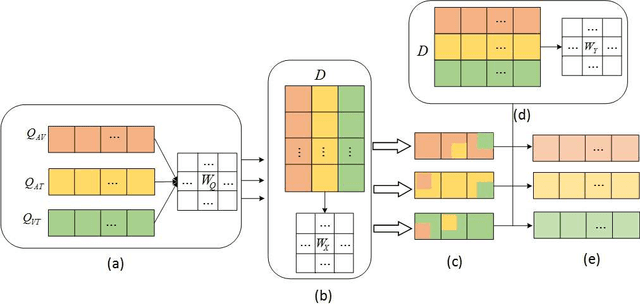
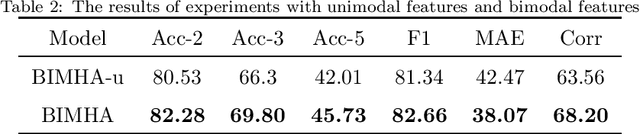
Sentiment analysis is the basis of intelligent human-computer interaction. As one of the frontier research directions of artificial intelligence, it can help computers better identify human intentions and emotional states so that provide more personalized services. However, as human present sentiments by spoken words, gestures, facial expressions and others which involve variable forms of data including text, audio, video, etc., it poses many challenges to this study. Due to the limitations of unimodal sentiment analysis, recent research has focused on the sentiment analysis of videos containing time series data of multiple modalities. When analyzing videos with multimodal data, the key problem is how to fuse these heterogeneous data. In consideration that the contribution of each modality is different, current fusion methods tend to extract the important information of single modality prior to fusion, which ignores the consistency and complementarity of bimodal interaction and has influences on the final decision. To solve this problem, a video sentiment analysis method using multi-head attention with bimodal information augmented is proposed. Based on bimodal interaction, more important bimodal features are assigned larger weights. In this way, different feature representations are adaptively assigned corresponding attention for effective multimodal fusion. Extensive experiments were conducted on both Chinese and English public datasets. The results show that our approach outperforms the existing methods and can give an insight into the contributions of bimodal interaction among three modalities.