 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyTrack: Tracking with Bounding Polygons
Nov 02, 2021

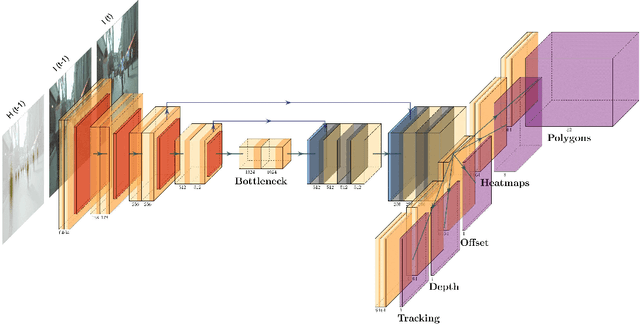
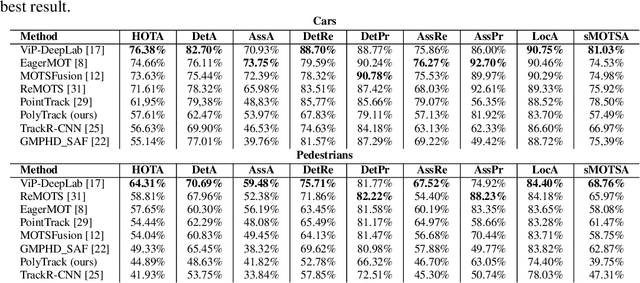
In this paper, we present a novel method called PolyTrack for fast multi-object tracking and segmentation using bounding polygons. Polytrack detects objects by producing heatmaps of their center keypoint. For each of them, a rough segmentation is done by computing a bounding polygon over each instance instead of the traditional bounding box. Tracking is done by taking two consecutive frames as input and computing a center offset for each object detected in the first frame to predict its location in the second frame. A Kalman filter is also applied to reduce the number of ID switches. Since our target application is automated driving systems, we apply our method on urban environment videos. We trained and evaluated PolyTrack on the MOTS and KITTIMOTS datasets. Results show that tracking polygons can be a good alternative to bounding box and mask tracking. The code of PolyTrack is available at https://github.com/gafaua/PolyTrack.
FFAVOD: Feature Fusion Architecture for Video Object Detection
Sep 15, 2021
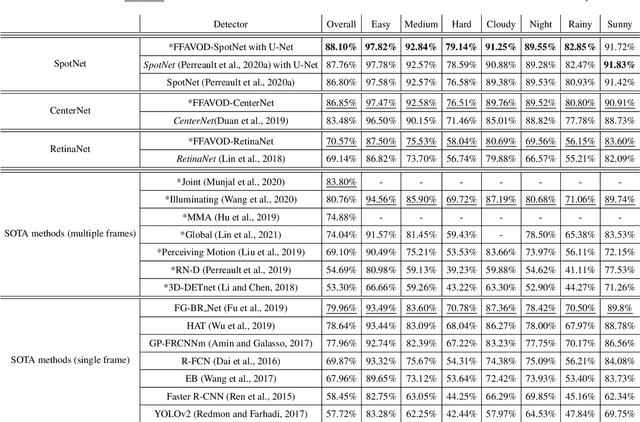
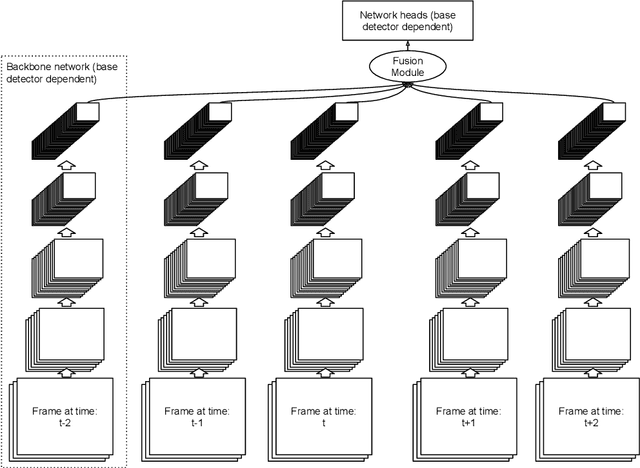
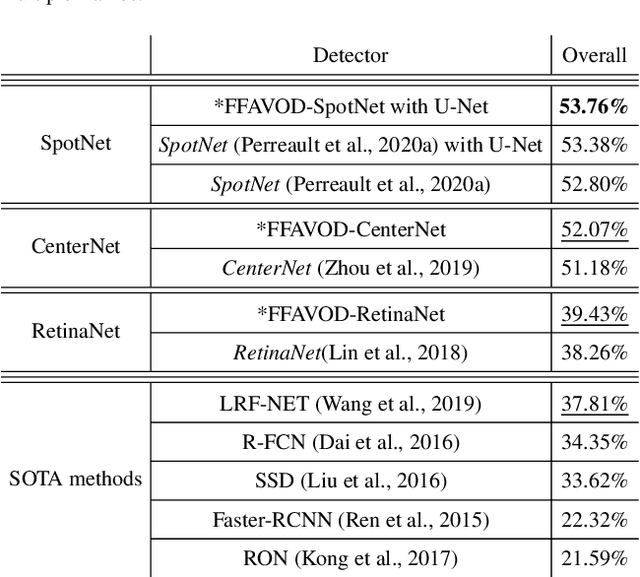
A significant amount of redundancy exists between consecutive frames of a video. Object detectors typically produce detections for one image at a time, without any capabilities for taking advantage of this redundancy. Meanwhile, many applications for object detection work with videos, including intelligent transportation systems, advanced driver assistance systems and video surveillance. Our work aims at taking advantage of the similarity between video frames to produce better detections. We propose FFAVOD, standing for feature fusion architecture for video object detection. We first introduce a novel video object detection architecture that allows a network to share feature maps between nearby frames. Second, we propose a feature fusion module that learns to merge feature maps to enhance them. We show that using the proposed architecture and the fusion module can improve the performance of three base object detectors on two object detection benchmarks containing sequences of moving road users. Additionally, to further increase performance, we propose an improvement to the SpotNet attention module. Using our architecture on the improved SpotNet detector, we obtain the state-of-the-art performance on the UA-DETRAC public benchmark as well as on the UAVDT dataset. Code is available at https://github.com/hu64/FFAVOD.
CenterPoly: real-time instance segmentation using bounding polygons
Aug 19, 2021
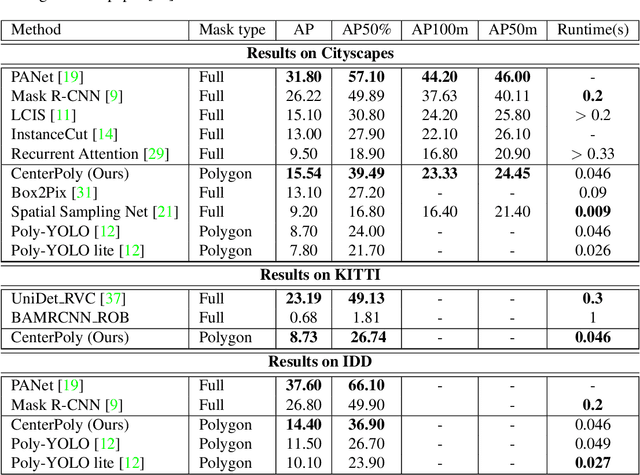


We present a novel method, called CenterPoly, for real-time instance segmentation using bounding polygons. We apply it to detect road users in dense urban environments, making it suitable for applications in intelligent transportation systems like automated vehicles. CenterPoly detects objects by their center keypoint while predicting a fixed number of polygon vertices for each object, thus performing detection and segmentation in parallel. Most of the network parameters are shared by the network heads, making it fast and lightweight enough to run at real-time speed. To properly convert mask ground-truth to polygon ground-truth, we designed a vertex selection strategy to facilitate the learning of the polygons. Additionally, to better segment overlapping objects in dense urban scenes, we also train a relative depth branch to determine which instances are closer and which are further, using available weak annotations. We propose several models with different backbones to show the possible speed / accuracy trade-offs. The models were trained and evaluated on Cityscapes, KITTI and IDD and the results are reported on their public benchmark, which are state-of-the-art at real-time speeds. Code is available at https://github.com/hu64/CenterPoly
RN-VID: A Feature Fusion Architecture for Video Object Detection
Apr 02, 2020
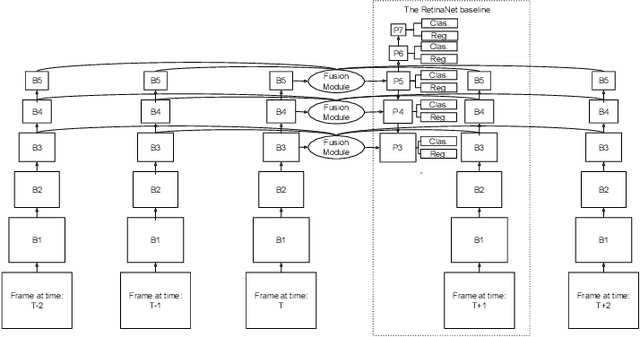
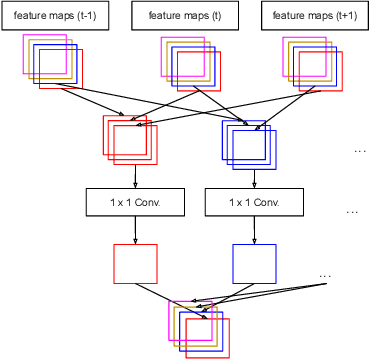

Consecutive frames in a video are highly redundant. Therefore, to perform the task of video object detection, executing single frame detectors on every frame without reusing any information is quite wasteful. It is with this idea in mind that we propose RN-VID (standing for RetinaNet-VIDeo), a novel approach to video object detection. Our contributions are twofold. First, we propose a new architecture that allows the usage of information from nearby frames to enhance feature maps. Second, we propose a novel module to merge feature maps of same dimensions using re-ordering of channels and 1 x 1 convolutions. We then demonstrate that RN-VID achieves better mean average precision (mAP) than corresponding single frame detectors with little additional cost during inference.
SpotNet: Self-Attention Multi-Task Network for Object Detection
Feb 13, 2020
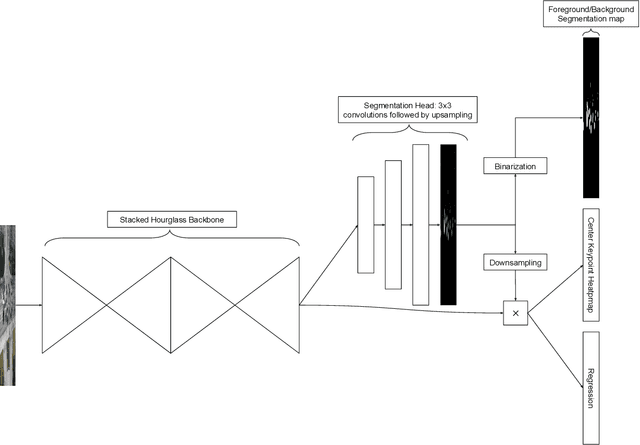


Humans are very good at directing their visual attention toward relevant areas when they search for different types of objects. For instance, when we search for cars, we will look at the streets, not at the top of buildings. The motivation of this paper is to train a network to do the same via a multi-task learning approach. To train visual attention, we produce foreground/background segmentation labels in a semi-supervised way, using background subtraction or optical flow. Using these labels, we train an object detection model to produce foreground/background segmentation maps as well as bounding boxes while sharing most model parameters. We use those segmentation maps inside the network as a self-attention mechanism to weight the feature map used to produce the bounding boxes, decreasing the signal of non-relevant areas. We show that by using this method, we obtain a significant mAP improvement on two traffic surveillance datasets, with state-of-the-art results on both UA-DETRAC and UAVDT.
Road User Detection in Videos
Mar 28, 2019



Successive frames of a video are highly redundant, and the most popular object detection methods do not take advantage of this fact. Using multiple consecutive frames can improve detection of small objects or difficult examples and can improve speed and detection consistency in a video sequence, for instance by interpolating features between frames. In this work, a novel approach is introduced to perform online video object detection using two consecutive frames of video sequences involving road users. Two new models, RetinaNet-Double and RetinaNet-Flow, are proposed, based respectively on the concatenation of a target frame with a preceding frame, and the concatenation of the optical flow with the target frame. The models are trained and evaluated on three public datasets. Experiments show that using a preceding frame improves performance over single frame detectors, but using explicit optical flow usually does not.