 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRN-VID: A Feature Fusion Architecture for Video Object Detection
Apr 02, 2020
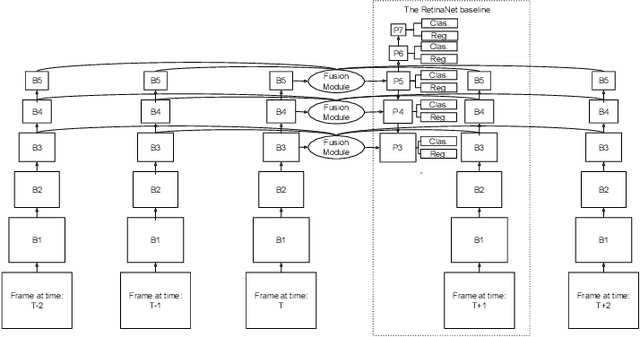
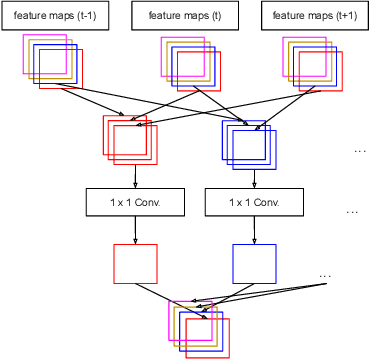

Consecutive frames in a video are highly redundant. Therefore, to perform the task of video object detection, executing single frame detectors on every frame without reusing any information is quite wasteful. It is with this idea in mind that we propose RN-VID (standing for RetinaNet-VIDeo), a novel approach to video object detection. Our contributions are twofold. First, we propose a new architecture that allows the usage of information from nearby frames to enhance feature maps. Second, we propose a novel module to merge feature maps of same dimensions using re-ordering of channels and 1 x 1 convolutions. We then demonstrate that RN-VID achieves better mean average precision (mAP) than corresponding single frame detectors with little additional cost during inference.
Road User Detection in Videos
Mar 28, 2019



Successive frames of a video are highly redundant, and the most popular object detection methods do not take advantage of this fact. Using multiple consecutive frames can improve detection of small objects or difficult examples and can improve speed and detection consistency in a video sequence, for instance by interpolating features between frames. In this work, a novel approach is introduced to perform online video object detection using two consecutive frames of video sequences involving road users. Two new models, RetinaNet-Double and RetinaNet-Flow, are proposed, based respectively on the concatenation of a target frame with a preceding frame, and the concatenation of the optical flow with the target frame. The models are trained and evaluated on three public datasets. Experiments show that using a preceding frame improves performance over single frame detectors, but using explicit optical flow usually does not.