 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLCBART: Multilabel Classification with Bayesian Additive Regression Trees
Jan 13, 2026Multilabel Classification (MLC) deals with the simultaneous classification of multiple binary labels. The task is challenging because, not only may there be arbitrarily different and complex relationships between predictor variables and each label, but associations among labels may exist even after accounting for effects of predictor variables. In this paper, we present a Bayesian additive regression tree (BART) framework to model the problem. BART is a nonparametric and flexible model structure capable of uncovering complex relationships within the data. Our adaptation, MLCBART, assumes that labels arise from thresholding an underlying numeric scale, where a multivariate normal model allows explicit estimation of the correlation structure among labels. This enables the discovery of complicated relationships in various forms and improves MLC predictive performance. Our Bayesian framework not only enables uncertainty quantification for each predicted label, but our MCMC draws produce an estimated conditional probability distribution of label combinations for any predictor values. Simulation experiments demonstrate the effectiveness of the proposed model by comparing its performance with a set of models, including the oracle model with the correct functional form. Results show that our model predicts vectors of labels more accurately than other contenders and its performance is close to the oracle model. An example highlights how the method's ability to produce measures of uncertainty on predictions provides nuanced understanding of classification results.
A new Bayesian ensemble of trees classifier for identifying multi-class labels in satellite images
May 31, 2013



Classification of satellite images is a key component of many remote sensing applications. One of the most important products of a raw satellite image is the classified map which labels the image pixels into meaningful classes. Though several parametric and non-parametric classifiers have been developed thus far, accurate labeling of the pixels still remains a challenge. In this paper, we propose a new reliable multiclass-classifier for identifying class labels of a satellite image in remote sensing applications. The proposed multiclass-classifier is a generalization of a binary classifier based on the flexible ensemble of regression trees model called Bayesian Additive Regression Trees (BART). We used three small areas from the LANDSAT 5 TM image, acquired on August 15, 2009 (path/row: 08/29, L1T product, UTM map projection) over Kings County, Nova Scotia, Canada to classify the land-use. Several prediction accuracy and uncertainty measures have been used to compare the reliability of the proposed classifier with the state-of-the-art classifiers in remote sensing.
A Short Note on Gaussian Process Modeling for Large Datasets using Graphics Processing Units
Jul 21, 2012


The graphics processing unit (GPU) has emerged as a powerful and cost effective processor for general performance computing. GPUs are capable of an order of magnitude more floating-point operations per second as compared to modern central processing units (CPUs), and thus provide a great deal of promise for computationally intensive statistical applications. Fitting complex statistical models with a large number of parameters and/or for large datasets is often very computationally expensive. In this study, we focus on Gaussian process (GP) models -- statistical models commonly used for emulating expensive computer simulators. We demonstrate that the computational cost of implementing GP models can be significantly reduced by using a CPU+GPU heterogeneous computing system over an analogous implementation on a traditional computing system with no GPU acceleration. Our small study suggests that GP models are fertile ground for further implementation on CPU+GPU systems.
Sequential Design for Computer Experiments with a Flexible Bayesian Additive Model
Jul 01, 2012
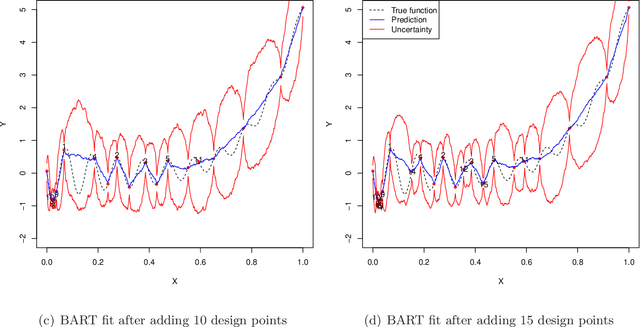
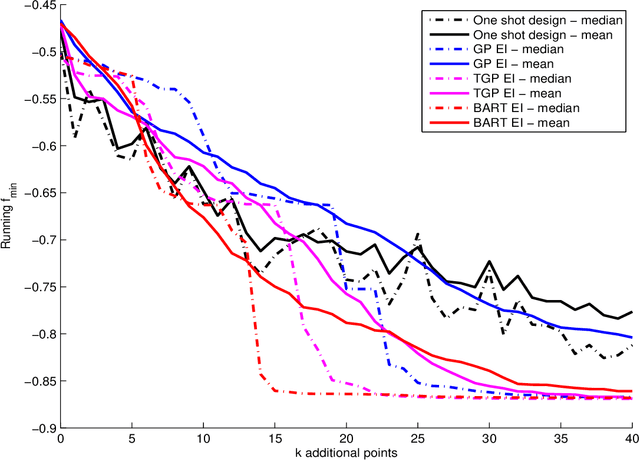
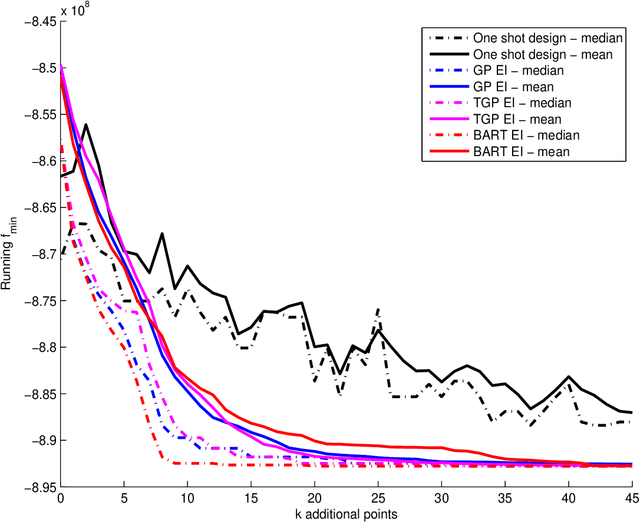
In computer experiments, a mathematical model implemented on a computer is used to represent complex physical phenomena. These models, known as computer simulators, enable experimental study of a virtual representation of the complex phenomena. Simulators can be thought of as complex functions that take many inputs and provide an output. Often these simulators are themselves expensive to compute, and may be approximated by "surrogate models" such as statistical regression models. In this paper we consider a new kind of surrogate model, a Bayesian ensemble of trees (Chipman et al. 2010), with the specific goal of learning enough about the simulator that a particular feature of the simulator can be estimated. We focus on identifying the simulator's global minimum. Utilizing the Bayesian version of the Expected Improvement criterion (Jones et al. 1998), we show that this ensemble is particularly effective when the simulator is ill-behaved, exhibiting nonstationarity or abrupt changes in the response. A number of illustrations of the approach are given, including a tidal power application.
Mixed-Membership Stochastic Block-Models for Transactional Networks
Oct 07, 2010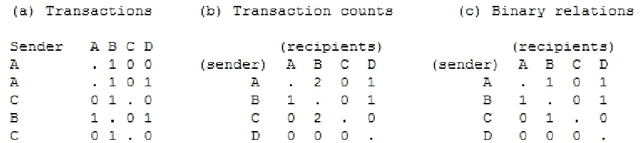
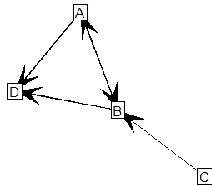


Transactional network data can be thought of as a list of one-to-many communications(e.g., email) between nodes in a social network. Most social network models convert this type of data into binary relations between pairs of nodes. We develop a latent mixed membership model capable of modeling richer forms of transactional network data, including relations between more than two nodes. The model can cluster nodes and predict transactions. The block-model nature of the model implies that groups can be characterized in very general ways. This flexible notion of group structure enables discovery of rich structure in transactional networks. Estimation and inference are accomplished via a variational EM algorithm. Simulations indicate that the learning algorithm can recover the correct generative model. Interesting structure is discovered in the Enron email dataset and another dataset extracted from the Reddit website. Analysis of the Reddit data is facilitated by a novel performance measure for comparing two soft clusterings. The new model is superior at discovering mixed membership in groups and in predicting transactions.
On the underestimation of model uncertainty by Bayesian K-nearest neighbors
Apr 08, 2008
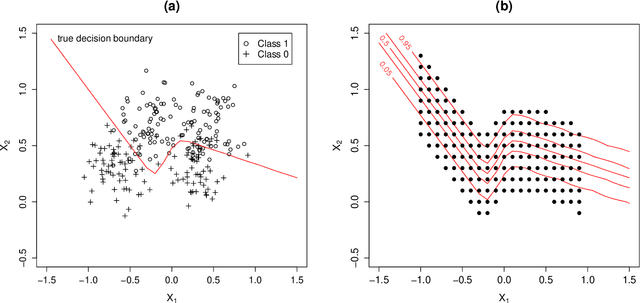
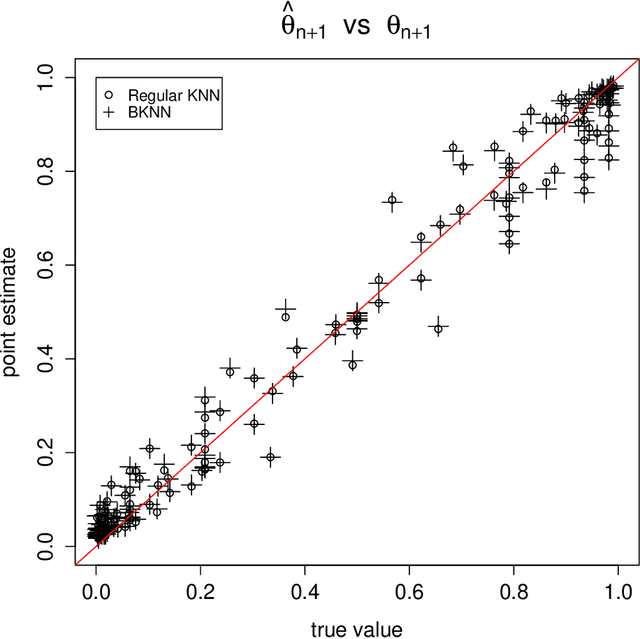
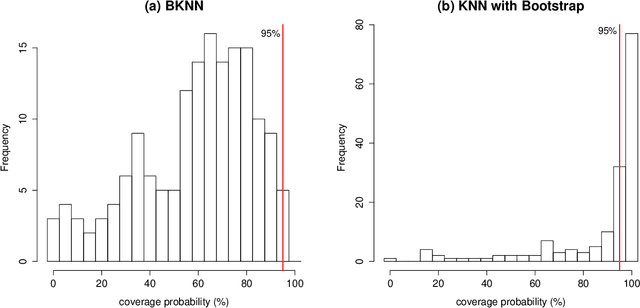
When using the K-nearest neighbors method, one often ignores uncertainty in the choice of K. To account for such uncertainty, Holmes and Adams (2002) proposed a Bayesian framework for K-nearest neighbors (KNN). Their Bayesian KNN (BKNN) approach uses a pseudo-likelihood function, and standard Markov chain Monte Carlo (MCMC) techniques to draw posterior samples. Holmes and Adams (2002) focused on the performance of BKNN in terms of misclassification error but did not assess its ability to quantify uncertainty. We present some evidence to show that BKNN still significantly underestimates model uncertainty.