 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoStream: Benchmarking Real-World Streaming for Omnimodal Assistants in Mobile Scenarios
Jan 30, 2026Multimodal Large Language Models excel at offline audio-visual understanding, but their ability to serve as mobile assistants in continuous real-world streams remains underexplored. In daily phone use, mobile assistants must track streaming audio-visual inputs and respond at the right time, yet existing benchmarks are often restricted to multiple-choice questions or use shorter videos. In this paper, we introduce PhoStream, the first mobile-centric streaming benchmark that unifies on-screen and off-screen scenarios to evaluate video, audio, and temporal reasoning. PhoStream contains 5,572 open-ended QA pairs from 578 videos across 4 scenarios and 10 capabilities. We build it with an Automated Generative Pipeline backed by rigorous human verification, and evaluate models using a realistic Online Inference Pipeline and LLM-as-a-Judge evaluation for open-ended responses. Experiments reveal a temporal asymmetry in LLM-judged scores (0-100): models perform well on Instant and Backward tasks (Gemini 3 Pro exceeds 80), but drop sharply on Forward tasks (16.40), largely due to early responses before the required visual and audio cues appear. This highlights a fundamental limitation: current MLLMs struggle to decide when to speak, not just what to say. Code and datasets used in this work will be made publicly accessible at https://github.com/Lucky-Lance/PhoStream.
Delving into Dark Regions for Robust Shadow Detection
Feb 21, 2024



Shadow detection is a challenging task as it requires a comprehensive understanding of shadow characteristics and global/local illumination conditions. We observe from our experiment that state-of-the-art deep methods tend to have higher error rates in differentiating shadow pixels from non-shadow pixels in dark regions (ie, regions with low-intensity values). Our key insight to this problem is that existing methods typically learn discriminative shadow features from the whole image globally, covering the full range of intensity values, and may not learn the subtle differences between shadow and non-shadow pixels in dark regions. Hence, if we can design a model to focus on a narrower range of low-intensity regions, it may be able to learn better discriminative features for shadow detection. Inspired by this insight, we propose a novel shadow detection approach that first learns global contextual cues over the entire image and then zooms into the dark regions to learn local shadow representations. To this end, we formulate an effective dark-region recommendation (DRR) module to recommend regions of low-intensity values, and a novel dark-aware shadow analysis (DASA) module to learn dark-aware shadow features from the recommended dark regions. Extensive experiments show that the proposed method outperforms the state-of-the-art methods on three popular shadow detection datasets. Code is available at https://github.com/guanhuankang/ShadowDetection2021.git.
Rethinking Video Salient Object Ranking
Mar 31, 2022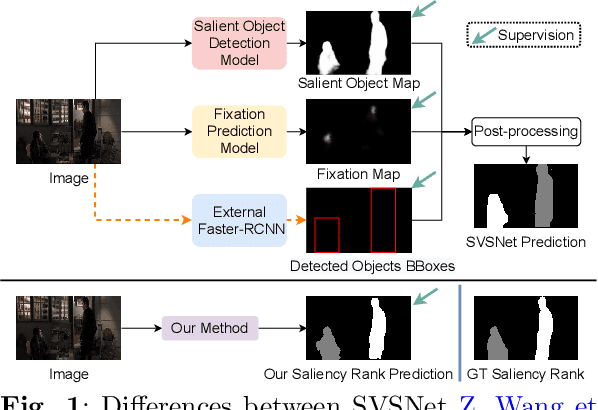


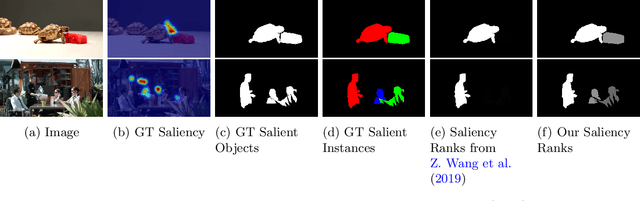
Salient Object Ranking (SOR) involves ranking the degree of saliency of multiple salient objects in an input image. Most recently, a method is proposed for ranking salient objects in an input video based on a predicted fixation map. It relies solely on the density of the fixations within the salient objects to infer their saliency ranks, which is incompatible with human perception of saliency ranking. In this work, we propose to explicitly learn the spatial and temporal relations between different salient objects to produce the saliency ranks. To this end, we propose an end-to-end method for video salient object ranking (VSOR), with two novel modules: an intra-frame adaptive relation (IAR) module to learn the spatial relation among the salient objects in the same frame locally and globally, and an inter-frame dynamic relation (IDR) module to model the temporal relation of saliency across different frames. In addition, to address the limited video types (just sports and movies) and scene diversity in the existing VSOR dataset, we propose a new dataset that covers different video types and diverse scenes on a large scale. Experimental results demonstrate that our method outperforms state-of-the-art methods in relevant fields. We will make the source code and our proposed dataset available.