 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Video Salient Object Ranking
Paper and Code
Mar 31, 2022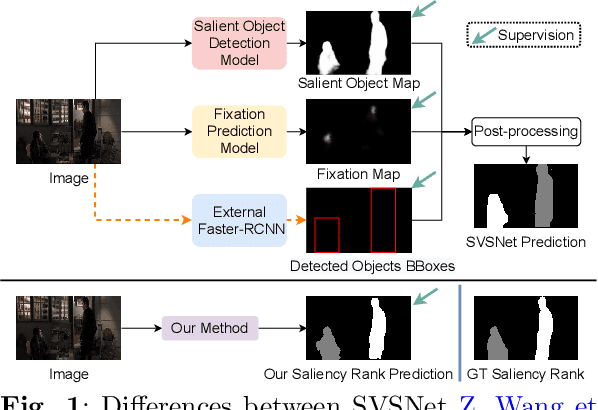


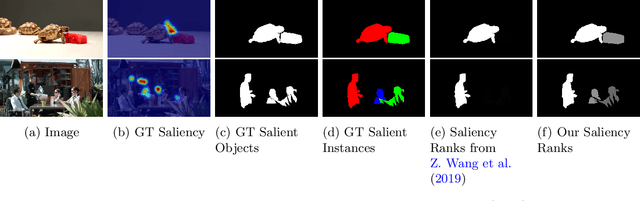
Salient Object Ranking (SOR) involves ranking the degree of saliency of multiple salient objects in an input image. Most recently, a method is proposed for ranking salient objects in an input video based on a predicted fixation map. It relies solely on the density of the fixations within the salient objects to infer their saliency ranks, which is incompatible with human perception of saliency ranking. In this work, we propose to explicitly learn the spatial and temporal relations between different salient objects to produce the saliency ranks. To this end, we propose an end-to-end method for video salient object ranking (VSOR), with two novel modules: an intra-frame adaptive relation (IAR) module to learn the spatial relation among the salient objects in the same frame locally and globally, and an inter-frame dynamic relation (IDR) module to model the temporal relation of saliency across different frames. In addition, to address the limited video types (just sports and movies) and scene diversity in the existing VSOR dataset, we propose a new dataset that covers different video types and diverse scenes on a large scale. Experimental results demonstrate that our method outperforms state-of-the-art methods in relevant fields. We will make the source code and our proposed dataset available.