 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle image depth estimation by dilated deep residual convolutional neural network and soft-weight-sum inference
Apr 27, 2017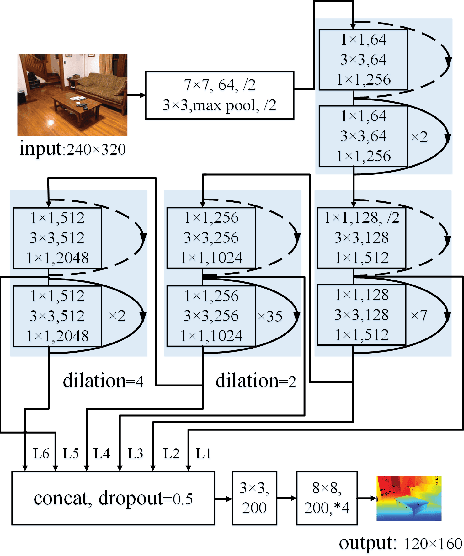
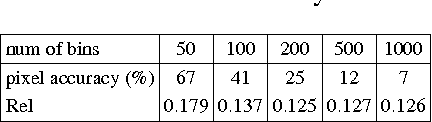
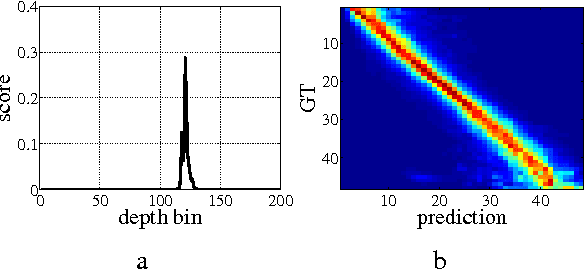
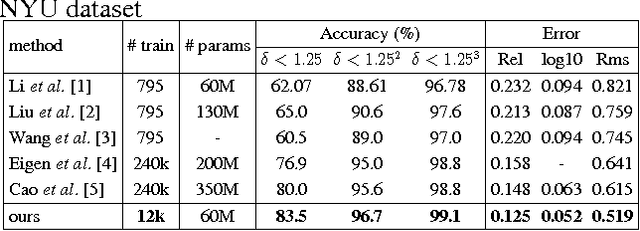
This paper proposes a new residual convolutional neural network (CNN) architecture for single image depth estimation. Compared with existing deep CNN based methods, our method achieves much better results with fewer training examples and model parameters. The advantages of our method come from the usage of dilated convolution, skip connection architecture and soft-weight-sum inference. Experimental evaluation on the NYU Depth V2 dataset shows that our method outperforms other state-of-the-art methods by a margin.
Skeleton Boxes: Solving skeleton based action detection with a single deep convolutional neural network
Apr 19, 2017



Action recognition from well-segmented 3D skeleton video has been intensively studied. However, due to the difficulty in representing the 3D skeleton video and the lack of training data, action detection from streaming 3D skeleton video still lags far behind its recognition counterpart and image based object detection. In this paper, we propose a novel approach for this problem, which leverages both effective skeleton video encoding and deep regression based object detection from images. Our framework consists of two parts: skeleton-based video image mapping, which encodes a skeleton video to a color image in a temporal preserving way, and an end-to-end trainable fast skeleton action detector (Skeleton Boxes) based on image detection. Experimental results on the latest and largest PKU-MMD benchmark dataset demonstrate that our method outperforms the state-of-the-art methods with a large margin. We believe our idea would inspire and benefit future research in this important area.
* 4 pages,3 figures, icmew 2017