 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHEME : Enhancing Thematic Investing with Semantic Stock Representations and Temporal Dynamics
Aug 23, 2025Thematic investing aims to construct portfolios aligned with structural trends, yet selecting relevant stocks remains challenging due to overlapping sector boundaries and evolving market dynamics. To address this challenge, we construct the Thematic Representation Set (TRS), an extended dataset that begins with real-world thematic ETFs and expands upon them by incorporating industry classifications and financial news to overcome their coverage limitations. The final dataset contains both the explicit mapping of themes to their constituent stocks and the rich textual profiles for each. Building on this dataset, we introduce \textsc{THEME}, a hierarchical contrastive learning framework. By representing the textual profiles of themes and stocks as embeddings, \textsc{THEME} first leverages their hierarchical relationship to achieve semantic alignment. Subsequently, it refines these semantic embeddings through a temporal refinement stage that incorporates individual stock returns. The final stock representations are designed for effective retrieval of thematically aligned assets with strong return potential. Empirical results show that \textsc{THEME} outperforms strong baselines across multiple retrieval metrics and significantly improves performance in portfolio construction. By jointly modeling thematic relationships from text and market dynamics from returns, \textsc{THEME} provides a scalable and adaptive solution for navigating complex investment themes.
Your AI, Not Your View: The Bias of LLMs in Investment Analysis
Jul 28, 2025In finance, Large Language Models (LLMs) face frequent knowledge conflicts due to discrepancies between pre-trained parametric knowledge and real-time market data. These conflicts become particularly problematic when LLMs are deployed in real-world investment services, where misalignment between a model's embedded preferences and those of the financial institution can lead to unreliable recommendations. Yet little research has examined what investment views LLMs actually hold. We propose an experimental framework to investigate such conflicts, offering the first quantitative analysis of confirmation bias in LLM-based investment analysis. Using hypothetical scenarios with balanced and imbalanced arguments, we extract models' latent preferences and measure their persistence. Focusing on sector, size, and momentum, our analysis reveals distinct, model-specific tendencies. In particular, we observe a consistent preference for large-cap stocks and contrarian strategies across most models. These preferences often harden into confirmation bias, with models clinging to initial judgments despite counter-evidence.
Quantifying Qualitative Insights: Leveraging LLMs to Market Predict
Nov 13, 2024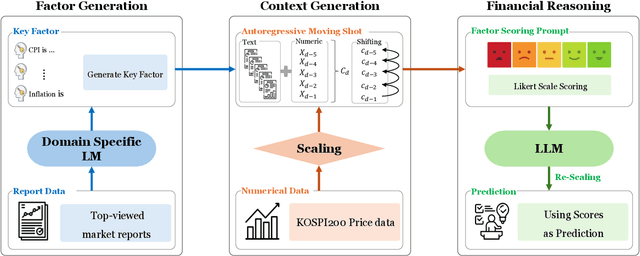



Recent advancements in Large Language Models (LLMs) have the potential to transform financial analytics by integrating numerical and textual data. However, challenges such as insufficient context when fusing multimodal information and the difficulty in measuring the utility of qualitative outputs, which LLMs generate as text, have limited their effectiveness in tasks such as financial forecasting. This study addresses these challenges by leveraging daily reports from securities firms to create high-quality contextual information. The reports are segmented into text-based key factors and combined with numerical data, such as price information, to form context sets. By dynamically updating few-shot examples based on the query time, the sets incorporate the latest information, forming a highly relevant set closely aligned with the query point. Additionally, a crafted prompt is designed to assign scores to the key factors, converting qualitative insights into quantitative results. The derived scores undergo a scaling process, transforming them into real-world values that are used for prediction. Our experiments demonstrate that LLMs outperform time-series models in market forecasting, though challenges such as imperfect reproducibility and limited explainability remain.
LLM-as-a-Judge & Reward Model: What They Can and Cannot Do
Sep 17, 2024LLM-as-a-Judge and reward models are widely used alternatives of multiple-choice questions or human annotators for large language model (LLM) evaluation. Their efficacy shines in evaluating long-form responses, serving a critical role as evaluators of leaderboards and as proxies to align LLMs via reinforcement learning. However, despite their popularity, their effectiveness outside of English remains largely unexplored. In this paper, we conduct a comprehensive analysis on automated evaluators, reporting key findings on their behavior in a non-English environment. First, we discover that English evaluation capabilities significantly influence language-specific capabilities, often more than the language proficiency itself, enabling evaluators trained in English to easily transfer their skills to other languages. Second, we identify critical shortcomings, where LLMs fail to detect and penalize errors, such as factual inaccuracies, cultural misrepresentations, and the presence of unwanted language. Finally, we release Kudge, the first non-English meta-evaluation dataset containing 5,012 human annotations in Korean.