 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Qualitative Insights: Leveraging LLMs to Market Predict
Nov 13, 2024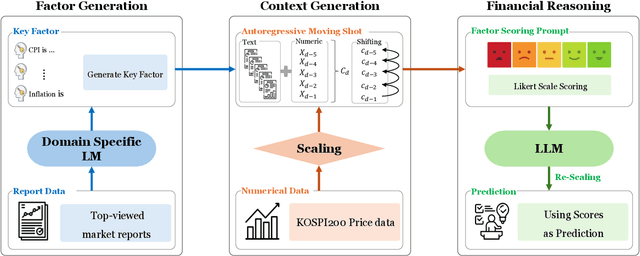



Recent advancements in Large Language Models (LLMs) have the potential to transform financial analytics by integrating numerical and textual data. However, challenges such as insufficient context when fusing multimodal information and the difficulty in measuring the utility of qualitative outputs, which LLMs generate as text, have limited their effectiveness in tasks such as financial forecasting. This study addresses these challenges by leveraging daily reports from securities firms to create high-quality contextual information. The reports are segmented into text-based key factors and combined with numerical data, such as price information, to form context sets. By dynamically updating few-shot examples based on the query time, the sets incorporate the latest information, forming a highly relevant set closely aligned with the query point. Additionally, a crafted prompt is designed to assign scores to the key factors, converting qualitative insights into quantitative results. The derived scores undergo a scaling process, transforming them into real-world values that are used for prediction. Our experiments demonstrate that LLMs outperform time-series models in market forecasting, though challenges such as imperfect reproducibility and limited explainability remain.