 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Time Series Classification Algorithms Using Octave-Convolutional Layers
Sep 28, 2021


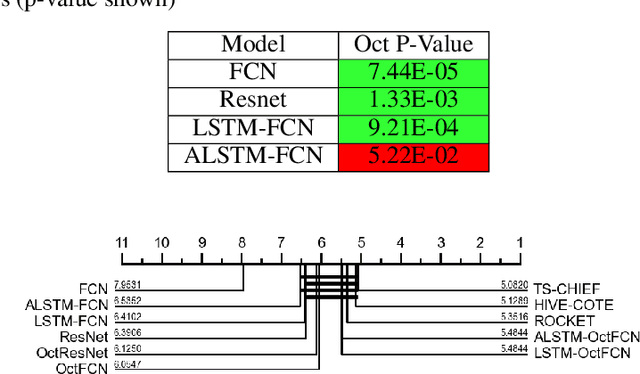
Deep learning models utilizing convolution layers have achieved state-of-the-art performance on univariate time series classification tasks. In this work, we propose improving CNN based time series classifiers by utilizing Octave Convolutions (OctConv) to outperform themselves. These network architectures include Fully Convolutional Networks (FCN), Residual Neural Networks (ResNets), LSTM-Fully Convolutional Networks (LSTM-FCN), and Attention LSTM-Fully Convolutional Networks (ALSTM-FCN). The proposed layers significantly improve each of these models with minimally increased network parameters. In this paper, we experimentally show that by substituting convolutions with OctConv, we significantly improve accuracy for time series classification tasks for most of the benchmark datasets. In addition, the updated ALSTM-OctFCN performs statistically the same as the top two time series classifers, TS-CHIEF and HIVE-COTE (both ensemble models). To further explore the impact of the OctConv layers, we perform ablation tests of the augmented model compared to their base model.
Process Mining Model to Predict Mortality in Paralytic Ileus Patients
Aug 03, 2021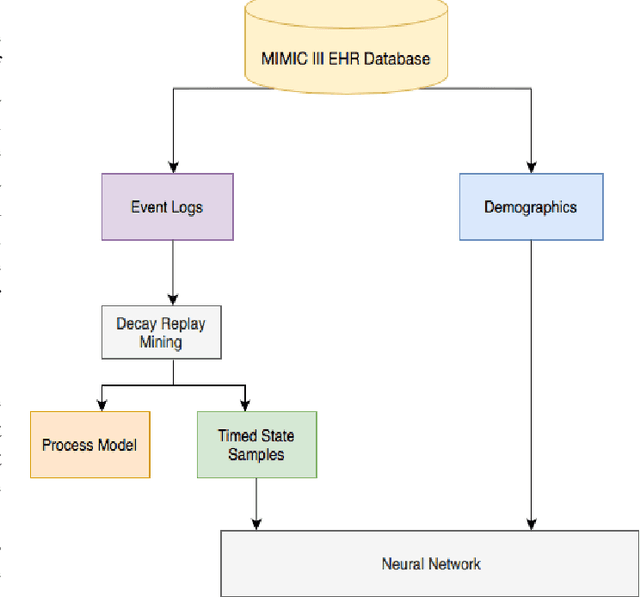
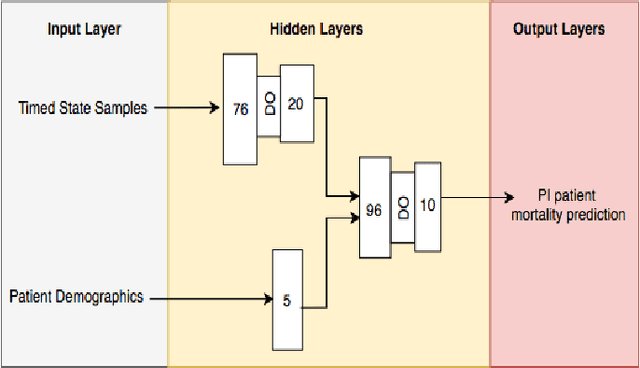
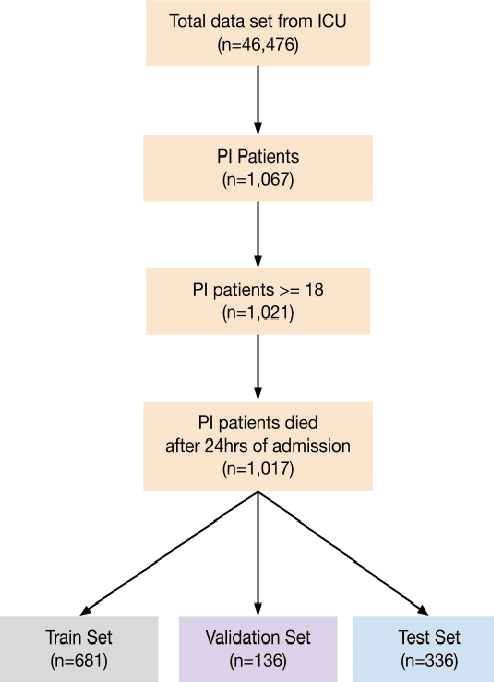
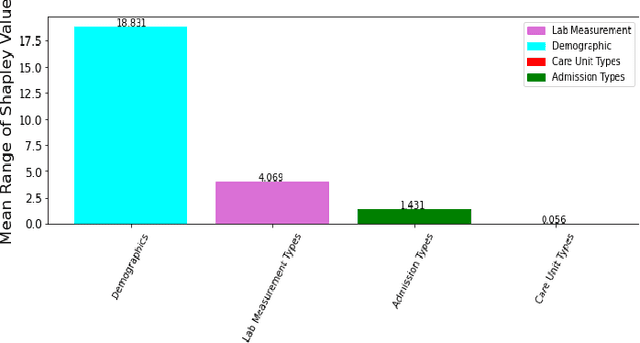
Paralytic Ileus (PI) patients are at high risk of death when admitted to the Intensive care unit (ICU), with mortality as high as 40\%. There is minimal research concerning PI patient mortality prediction. There is a need for more accurate prediction modeling for ICU patients diagnosed with PI. This paper demonstrates performance improvements in predicting the mortality of ICU patients diagnosed with PI after 24 hours of being admitted. The proposed framework, PMPI(Process Mining Model to predict mortality of PI patients), is a modification of the work used for prediction of in-hospital mortality for ICU patients with diabetes. PMPI demonstrates similar if not better performance with an Area under the ROC Curve (AUC) score of 0.82 compared to the best results of the existing literature. PMPI uses patient medical history, the time related to the events, and demographic information for prediction. The PMPI prediction framework has the potential to help medical teams in making better decisions for treatment and care for ICU patients with PI to increase their life expectancy.
Masking Neural Networks Using Reachability Graphs to Predict Process Events
Aug 01, 2021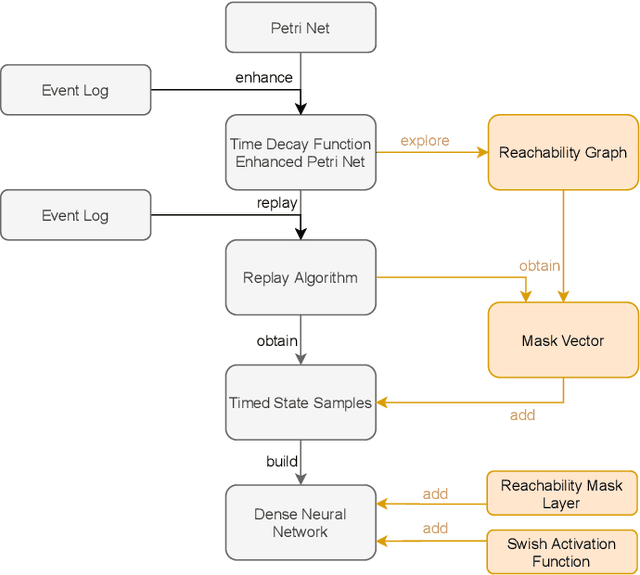
Decay Replay Mining is a deep learning method that utilizes process model notations to predict the next event. However, this method does not intertwine the neural network with the structure of the process model to its full extent. This paper proposes an approach to further interlock the process model of Decay Replay Mining with its neural network for next event prediction. The approach uses a masking layer which is initialized based on the reachability graph of the process model. Additionally, modifications to the neural network architecture are proposed to increase the predictive performance. Experimental results demonstrate the value of the approach and underscore the importance of discovering precise and generalized process models.
On the Performance Analysis of the Adversarial System Variant Approximation Method to Quantify Process Model Generalization
Jul 13, 2021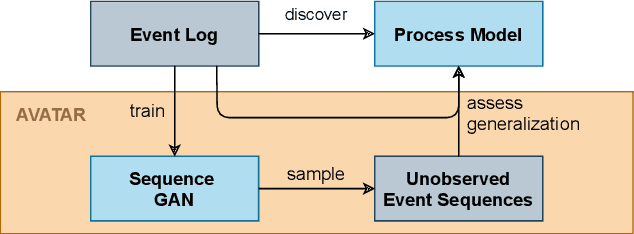

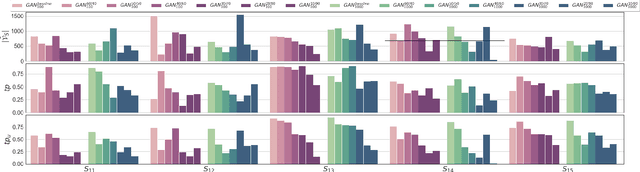
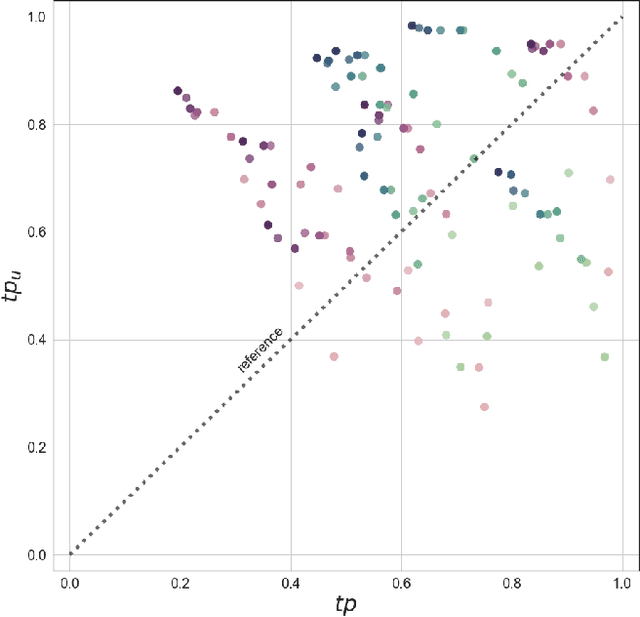
Process mining algorithms discover a process model from an event log. The resulting process model is supposed to describe all possible event sequences of the underlying system. Generalization is a process model quality dimension of interest. A generalization metric should quantify the extent to which a process model represents the observed event sequences contained in the event log and the unobserved event sequences of the system. Most of the available metrics in the literature cannot properly quantify the generalization of a process model. A recently published method [1] called Adversarial System Variant Approximation leverages Generative Adversarial Networks to approximate the underlying event sequence distribution of a system from an event log. While this method demonstrated performance gains over existing methods in measuring the generalization of process models, its experimental evaluations have been performed under ideal conditions. This paper experimentally investigates the performance of Adversarial System Variant Approximation under non-ideal conditions such as biased and limited event logs. Moreover, experiments are performed to investigate the originally proposed sampling hyperparameter value of the method on its performance to measure the generalization. The results confirm the need to raise awareness about the working conditions of the Adversarial System Variant Approximation method. The outcomes of this paper also serve to initiate future research directions. [1] Theis, Julian, and Houshang Darabi. "Adversarial System Variant Approximation to Quantify Process Model Generalization." IEEE Access 8 (2020): 194410-194427.
Adversarial Attacks on Multivariate Time Series
Mar 31, 2020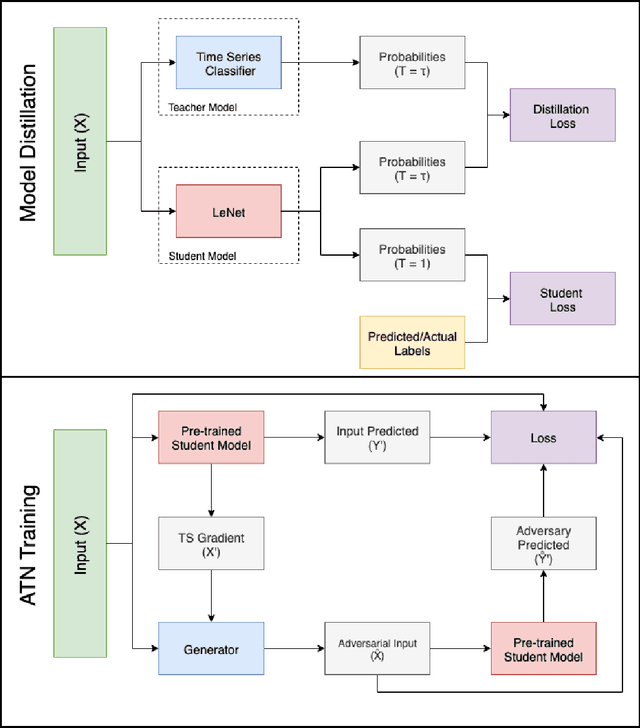
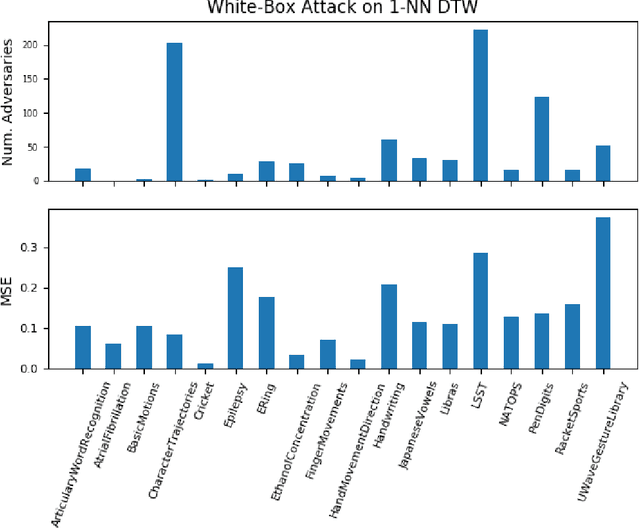
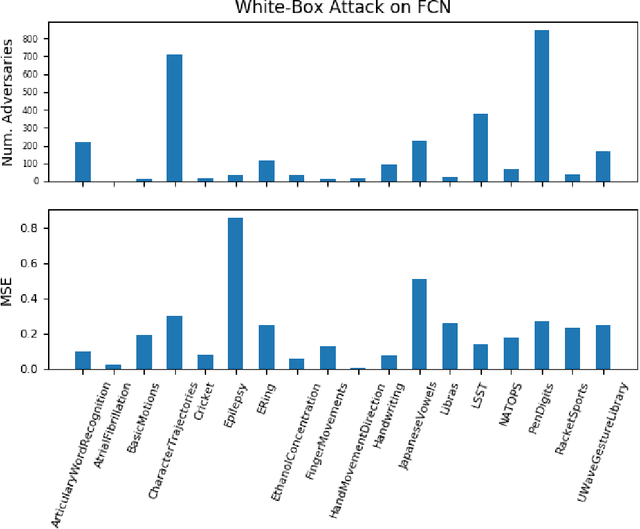
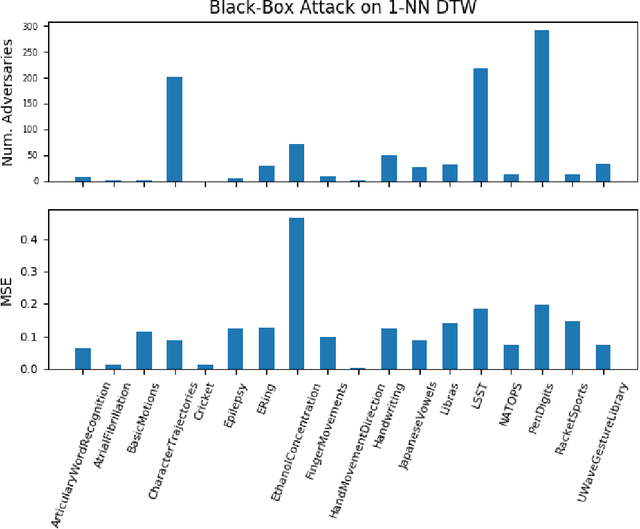
Classification models for the multivariate time series have gained significant importance in the research community, but not much research has been done on generating adversarial samples for these models. Such samples of adversaries could become a security concern. In this paper, we propose transforming the existing adversarial transformation network (ATN) on a distilled model to attack various multivariate time series classification models. The proposed attack on the classification model utilizes a distilled model as a surrogate that mimics the behavior of the attacked classical multivariate time series classification models. The proposed methodology is tested onto 1-Nearest Neighbor Dynamic Time Warping (1-NN DTW) and a Fully Convolutional Network (FCN), all of which are trained on 18 University of East Anglia (UEA) and University of California Riverside (UCR) datasets. We show both models were susceptible to attacks on all 18 datasets. To the best of our knowledge, adversarial attacks have only been conducted in the domain of univariate time series and have not been conducted on multivariate time series. such an attack on time series classification models has never been done before. Additionally, we recommend future researchers that develop time series classification models to incorporating adversarial data samples into their training data sets to improve resilience on adversarial samples and to consider model robustness as an evaluative metric.
Adversarial System Variant Approximation to Quantify Process Model Generalization
Mar 26, 2020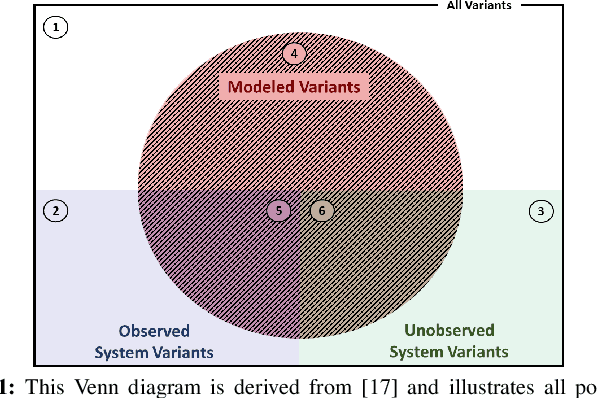
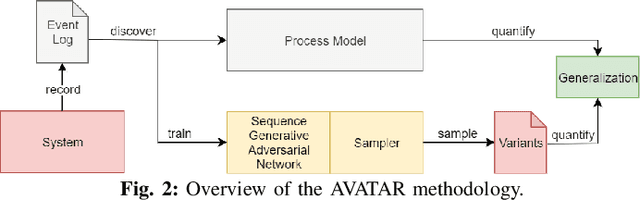
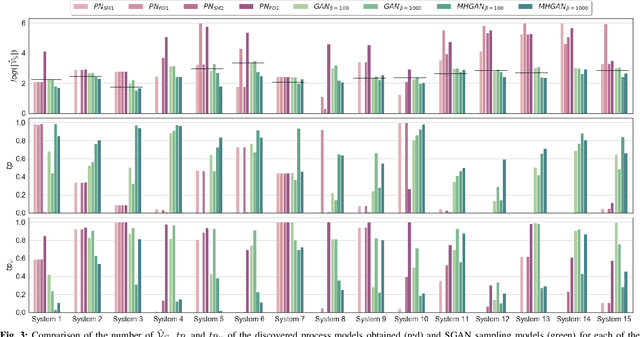
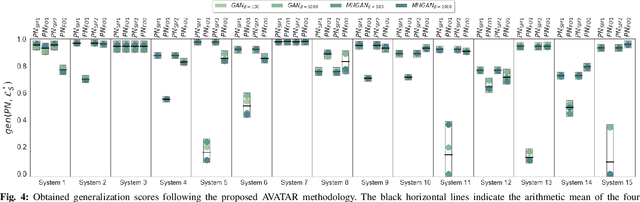
In process mining, process models are extracted from event logs using process discovery algorithms and are commonly assessed using multiple quality dimensions. While the metrics that measure the relationship of an extracted process model to its event log are well-studied, quantifying the level by which a process model can describe the unobserved behavior of its underlying system falls short in the literature. In this paper, a novel deep learning-based methodology called Adversarial System Variant Approximation (AVATAR) is proposed to overcome this issue. Sequence Generative Adversarial Networks are trained on the variants contained in an event log with the intention to approximate the underlying variant distribution of the system behavior. Unobserved realistic variants are sampled either directly from the Sequence Generative Adversarial Network or by leveraging the Metropolis-Hastings algorithm. The degree by which a process model relates to its underlying unknown system behavior is then quantified based on the realistic observed and estimated unobserved variants using established process model quality metrics. Significant performance improvements in revealing realistic unobserved variants are demonstrated in a controlled experiment on 15 ground truth systems. Additionally, the proposed methodology is experimentally tested and evaluated to quantify the generalization of 60 discovered process models with respect to their systems.
DREAM-NAP: Decay Replay Mining to Predict Next Process Activities
Mar 22, 2019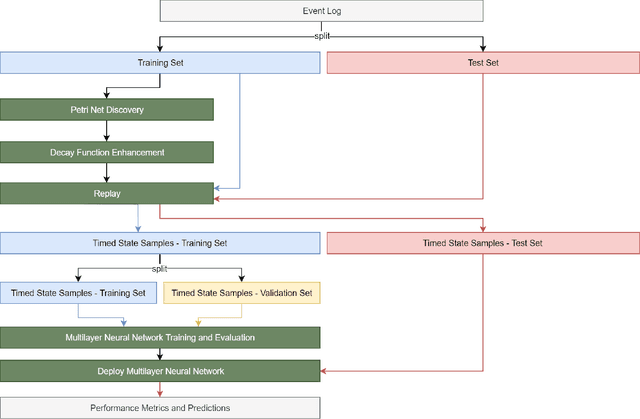



In complex processes, various events can happen in different sequences. The prediction of the next event activity given an a-priori process state is of importance in such processes. Recent methods leverage deep learning techniques such as recurrent neural networks to predict event activities from raw process logs. However, deep learning techniques cannot efficiently model logical behaviors of complex processes. In this paper, we take advantage of Petri nets as a powerful tool in modeling logical behaviors of complex processes. We propose an approach which first discovers Petri nets from event logs utilizing a recent process mining algorithm. In a second step, we enhance the obtained model with time decay functions to create timed process state samples. Finally, we use these samples in combination with token movement counters and Petri net markings to train a deep learning model that predicts the next event activity. We demonstrate significant performance improvements and outperform the state-of-the-art methods on eight out of nine real-world benchmark event logs in accuracy.
A Computer-Aided System for Determining the Application Range of a Warfarin Clinical Dosing Algorithm Using Support Vector Machines with a Polynomial Kernel Function
Mar 21, 2019
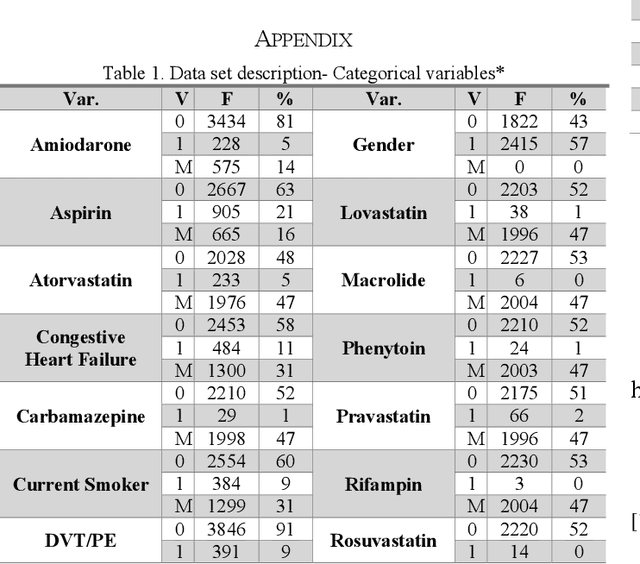

Determining the optimal initial dose for warfarin is a critically important task. Several factors have an impact on the therapeutic dose for individual patients, such as patients' physical attributes (Age, Height, etc.), medication profile, co-morbidities, and metabolic genotypes (CYP2C9 and VKORC1). These wide range factors influencing therapeutic dose, create a complex environment for clinicians to determine the optimal initial dose. Using a sample of 4,237 patients, we have proposed a companion classification model to one of the most popular dosing algorithms (International Warfarin Pharmacogenetics Consortium (IWPC) clinical model), which identifies the appropriate cohort of patients for applying this model. The proposed model functions as a clinical decision support system which assists clinicians in dosing. We have developed a classification model using Support Vector Machines, with a polynomial kernel function to determine if applying the dose prediction model is appropriate for a given patient. The IWPC clinical model will only be used if the patient is classified as "Safe for model". By using the proposed methodology, the dosing mode's prediction accuracy increases by 15 percent in terms of Root Mean Squared Error and 17 percent in terms of Mean Absolute Error in dose estimates of patients classified as "Safe for model".
Insights into LSTM Fully Convolutional Networks for Time Series Classification
Mar 01, 2019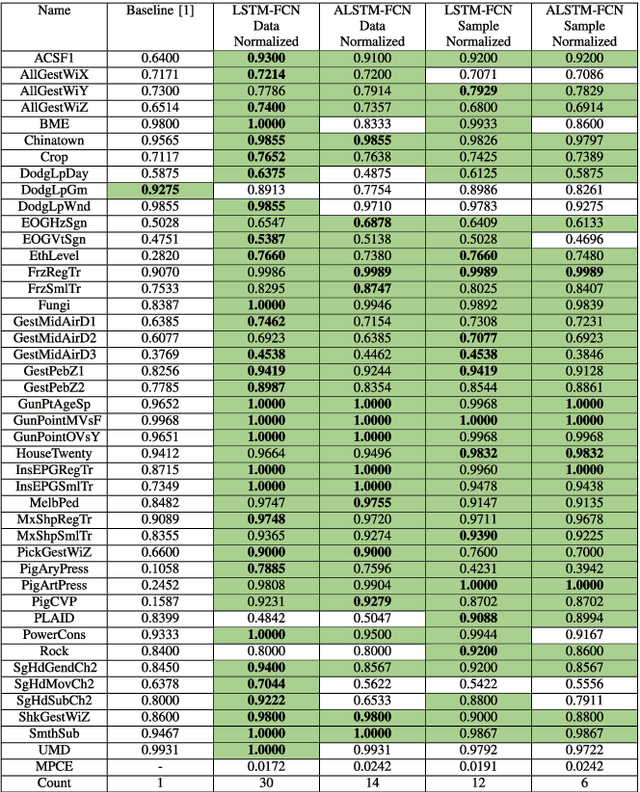
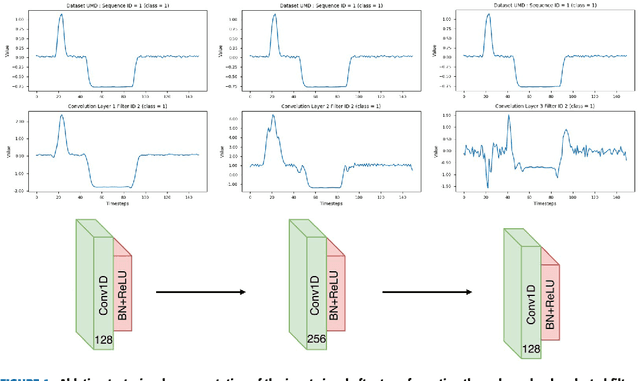
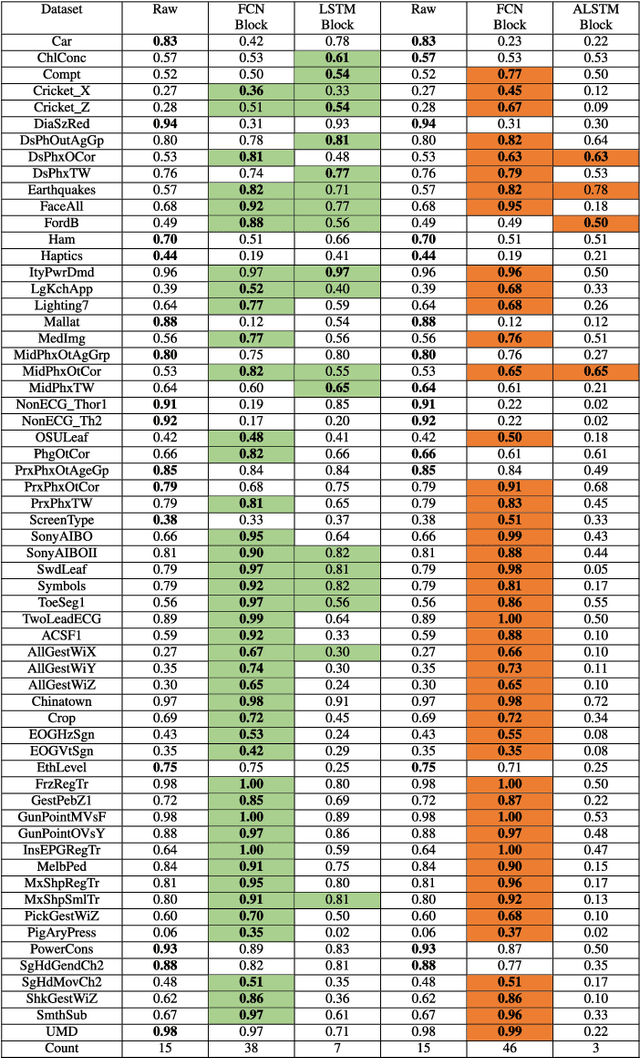
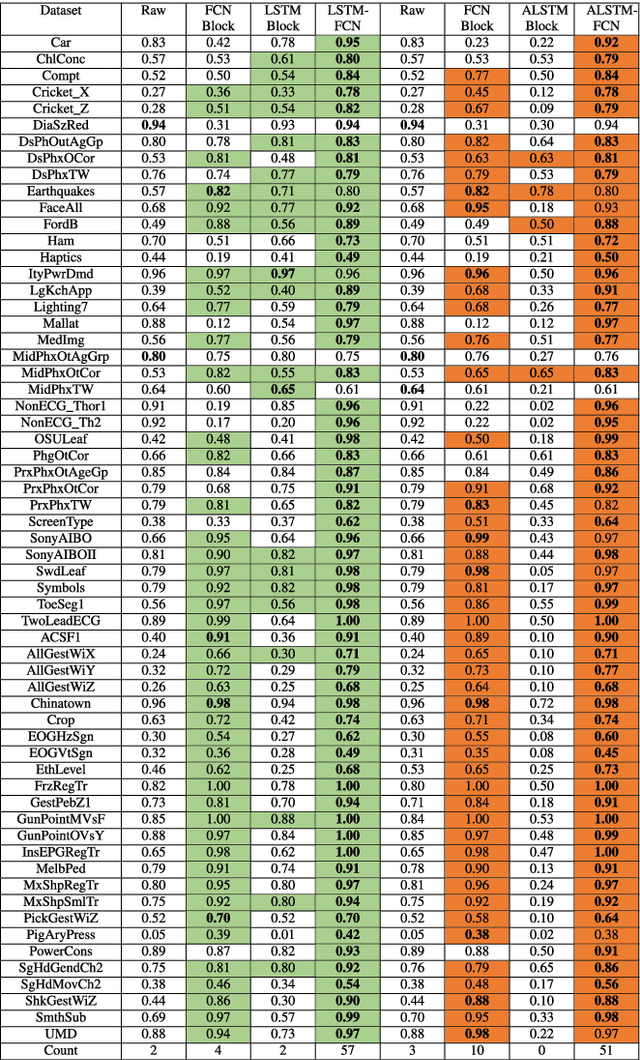
Long Short Term Memory Fully Convolutional Neural Networks (LSTM-FCN) and Attention LSTM-FCN (ALSTM-FCN) have shown to achieve state-of-the-art performance on the task of classifying time series signals on the old University of California-Riverside (UCR) time series repository. However, there has been no study on why LSTM-FCN and ALSTM-FCN perform well. In this paper, we perform a series of ablation tests (3627 experiments) on LSTM-FCN and ALSTM-FCN to provide a better understanding of the model and each of its sub-module. Results from the ablation tests on ALSTM-FCN and LSTM-FCN show that the these blocks perform better when applied in a conjoined manner. Two z-normalizing techniques, z-normalizing each sample independently and z-normalizing the whole dataset, are compared using a Wilcoxson signed-rank test to show a statistical difference in performance. In addition, we provide an understanding of the impact dimension shuffle has on LSTM-FCN by comparing its performance with LSTM-FCN when no dimension shuffle is applied. Finally, we demonstrate the performance of the LSTM-FCN when the LSTM block is replaced by a GRU, basic RNN, and Dense Block.
Adversarial Attacks on Time Series
Mar 01, 2019

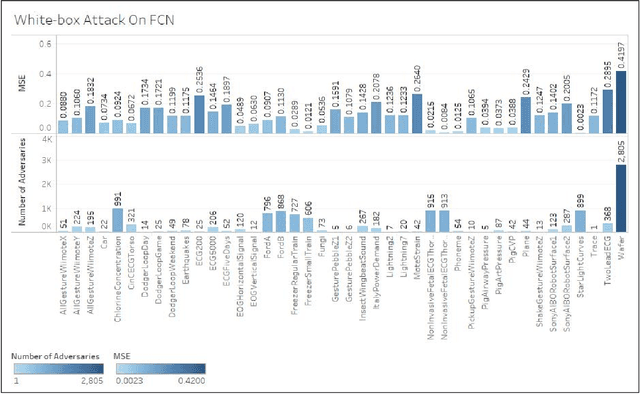
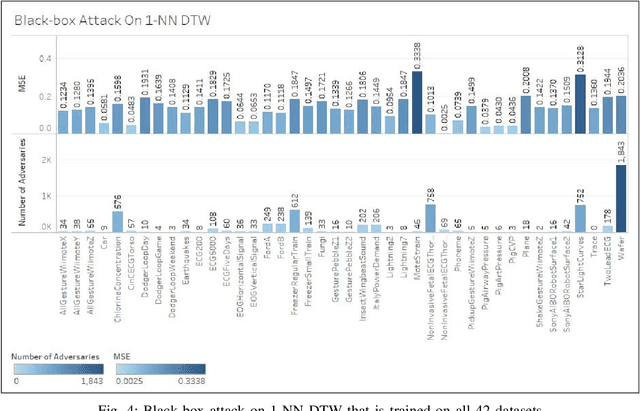
Time series classification models have been garnering significant importance in the research community. However, not much research has been done on generating adversarial samples for these models. These adversarial samples can become a security concern. In this paper, we propose utilizing an adversarial transformation network (ATN) on a distilled model to attack various time series classification models. The proposed attack on the classification model utilizes a distilled model as a surrogate that mimics the behavior of the attacked classical time series classification models. Our proposed methodology is applied onto 1-Nearest Neighbor Dynamic Time Warping (1-NN ) DTW, a Fully Connected Network and a Fully Convolutional Network (FCN), all of which are trained on 42 University of California Riverside (UCR) datasets. In this paper, we show both models were susceptible to attacks on all 42 datasets. To the best of our knowledge, such an attack on time series classification models has never been done before. Finally, we recommend future researchers that develop time series classification models to incorporating adversarial data samples into their training data sets to improve resilience on adversarial samples and to consider model robustness as an evaluative metric.