 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCE-CoLLM: Efficient and Adaptive Large Language Models Through Cloud-Edge Collaboration
Nov 05, 2024Large Language Models (LLMs) have achieved remarkable success in serving end-users with human-like intelligence. However, LLMs demand high computational resources, making it challenging to deploy them to satisfy various performance objectives, such as meeting the resource constraints on edge devices close to end-users or achieving high accuracy with ample resources. In this paper, we introduce CE-CoLLM, a novel cloud-edge collaboration framework that supports efficient and adaptive LLM inference for end-users at the edge with two modes, (1) low-latency edge standalone inference and (2) highly accurate cloud-edge collaborative inference. First, we show that the inherent high communication costs for transmitting LLM contextual information between the edge and cloud dominate the overall latency, making it inefficient and costly to deploy LLMs using cloud-edge collaboration. Second, we propose several critical techniques to address this challenge, including early-exit mechanism, cloud context manager, and quantization in cloud-edge collaboration to enable not only low-latency standalone edge inference but also efficient and adaptive cloud-edge collaborative inference for LLMs. Third, we perform comprehensive experimental analysis, which demonstrates that CE-CoLLM significantly reduces inference time by up to 13.81% and cloud computation costs by up to 84.55% compared to the popular cloud-based LLM deployment, while maintaining comparable model accuracy. The proposed approach effectively shifts the computational load to the edge, reduces the communication overhead, scales efficiently with multiple edge clients, and provides reliable LLM deployment using cloud-edge collaboration.
Boosting Deep Ensembles with Learning Rate Tuning
Oct 10, 2024The Learning Rate (LR) has a high impact on deep learning training performance. A common practice is to train a Deep Neural Network (DNN) multiple times with different LR policies to find the optimal LR policy, which has been widely recognized as a daunting and costly task. Moreover, multiple times of DNN training has not been effectively utilized. In practice, often only the optimal LR is adopted, which misses the opportunities to further enhance the overall accuracy of the deep learning system and results in a huge waste of both computing resources and training time. This paper presents a novel framework, LREnsemble, to effectively leverage effective learning rate tuning to boost deep ensemble performance. We make three original contributions. First, we show that the LR tuning with different LR policies can produce highly diverse DNNs, which can be supplied as base models for deep ensembles. Second, we leverage different ensemble selection algorithms to identify high-quality deep ensembles from the large pool of base models with significant accuracy improvements over the best single base model. Third, we propose LREnsemble, a framework that utilizes the synergy of LR tuning and deep ensemble techniques to enhance deep learning performance. The experiments on multiple benchmark datasets have demonstrated the effectiveness of LREnsemble, generating up to 2.34% accuracy improvements over well-optimized baselines.
DA-MoE: Towards Dynamic Expert Allocation for Mixture-of-Experts Models
Sep 10, 2024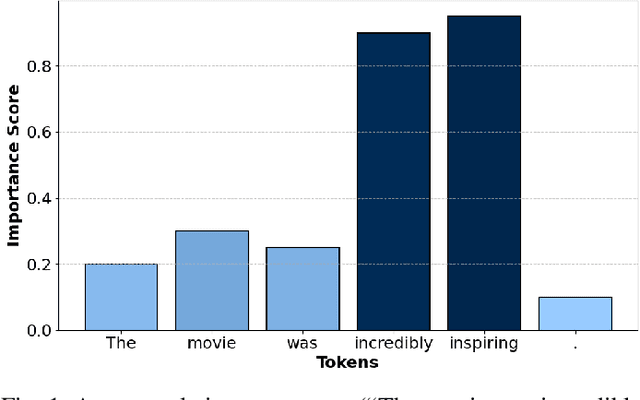
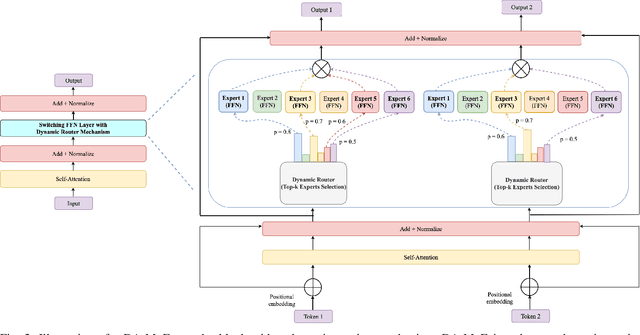
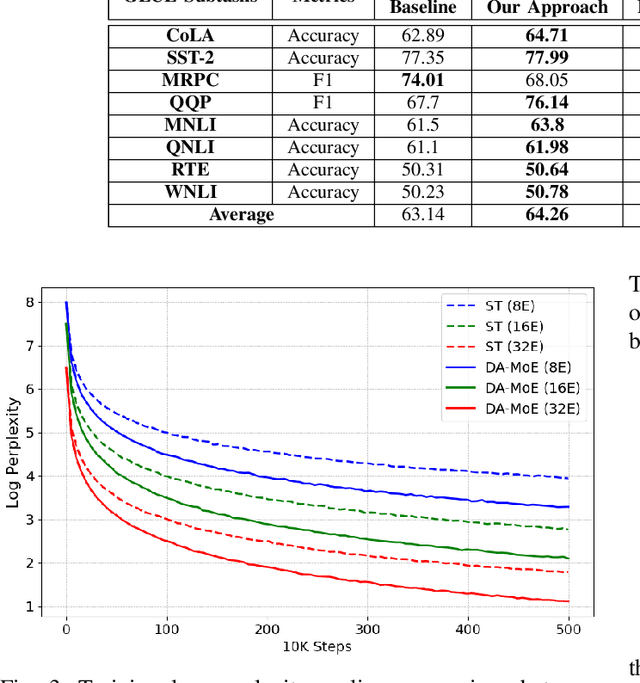
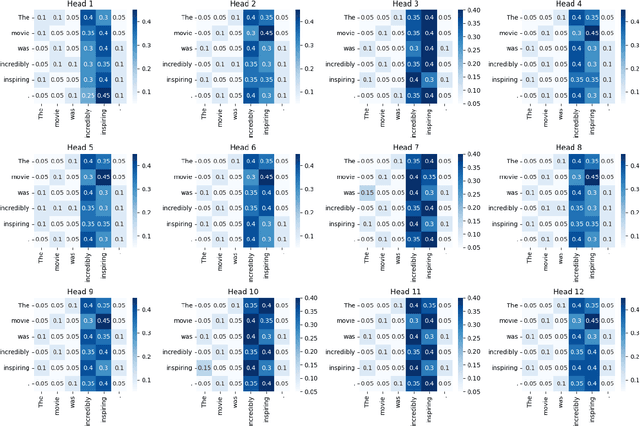
Transformer-based Mixture-of-Experts (MoE) models have been driving several recent technological advancements in Natural Language Processing (NLP). These MoE models adopt a router mechanism to determine which experts to activate for routing input tokens. However, existing router mechanisms allocate a fixed number of experts to each token, which neglects the varying importance of different input tokens. In this study, we propose a novel dynamic router mechanism that Dynamically Allocates a variable number of experts for Mixture-of-Experts (DA-MoE) models based on an effective token importance measure. First, we show that the Transformer attention mechanism provides a natural and effective way of calculating token importance. Second, we propose a dynamic router mechanism that effectively decides the optimal number of experts (K) and allocates the top-K experts for each input token. Third, comprehensive experiments on several benchmark datasets demonstrate that our DA-MoE approach consistently outperforms the state-of-the-art Transformer based MoE model on the popular GLUE benchmark.
Rethinking Learning Rate Tuning in the Era of Large Language Models
Sep 16, 2023



Large Language Models (LLMs) represent the recent success of deep learning in achieving remarkable human-like predictive performance. It has become a mainstream strategy to leverage fine-tuning to adapt LLMs for various real-world applications due to the prohibitive expenses associated with LLM training. The learning rate is one of the most important hyperparameters in LLM fine-tuning with direct impacts on both fine-tuning efficiency and fine-tuned LLM quality. Existing learning rate policies are primarily designed for training traditional deep neural networks (DNNs), which may not work well for LLM fine-tuning. We reassess the research challenges and opportunities of learning rate tuning in the coming era of Large Language Models. This paper makes three original contributions. First, we revisit existing learning rate policies to analyze the critical challenges of learning rate tuning in the era of LLMs. Second, we present LRBench++ to benchmark learning rate policies and facilitate learning rate tuning for both traditional DNNs and LLMs. Third, our experimental analysis with LRBench++ demonstrates the key differences between LLM fine-tuning and traditional DNN training and validates our analysis.