 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConverging to a Lingua Franca: Evolution of Linguistic Regions and Semantics Alignment in Multilingual Large Language Models
Oct 15, 2024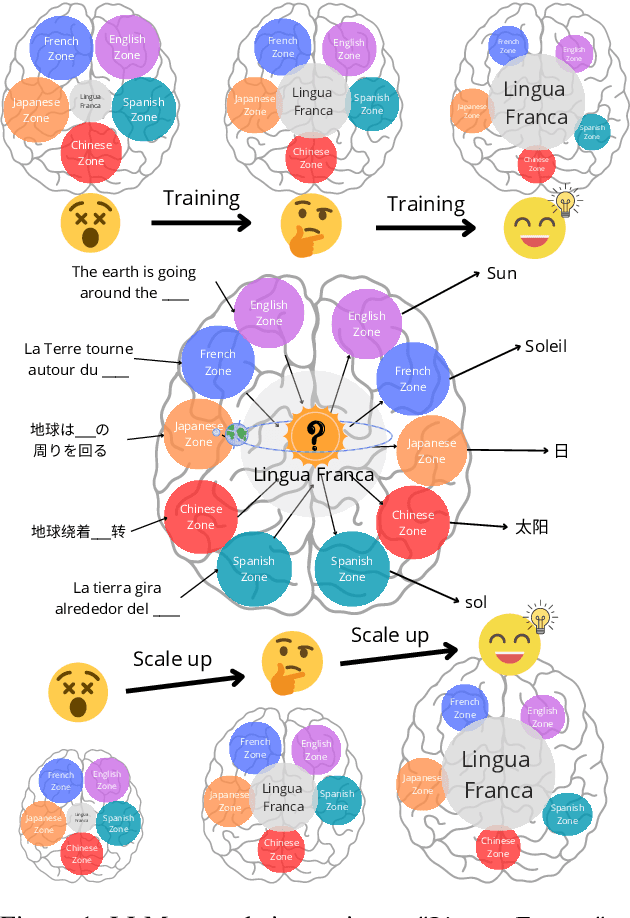


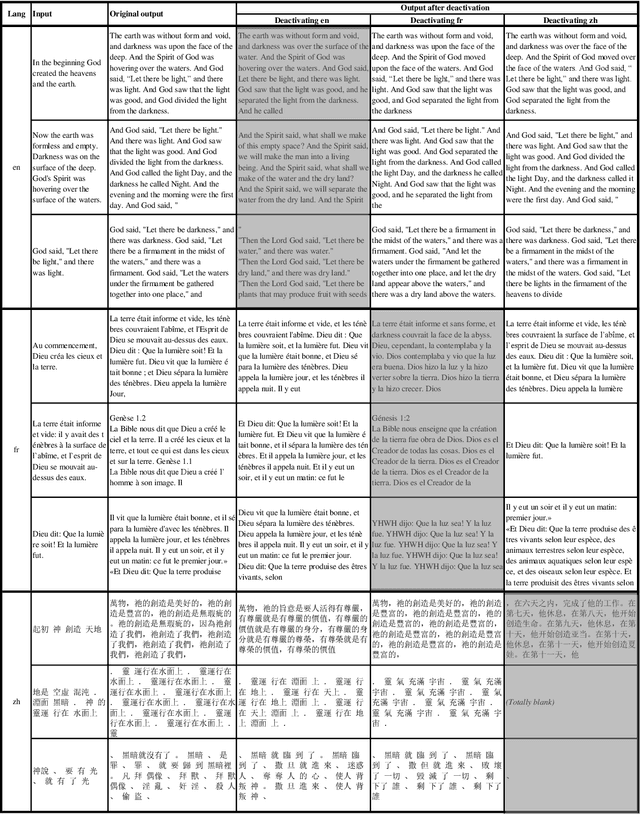
Large language models (LLMs) have demonstrated remarkable performance, particularly in multilingual contexts. While recent studies suggest that LLMs can transfer skills learned in one language to others, the internal mechanisms behind this ability remain unclear. We observed that the neuron activation patterns of LLMs exhibit similarities when processing the same language, revealing the existence and location of key linguistic regions. Additionally, we found that neuron activation patterns are similar when processing sentences with the same semantic meaning in different languages. This indicates that LLMs map semantically identical inputs from different languages into a "Lingua Franca", a common semantic latent space that allows for consistent processing across languages. This semantic alignment becomes more pronounced with training and increased model size, resulting in a more language-agnostic activation pattern. Moreover, we found that key linguistic neurons are concentrated in the first and last layers of LLMs, becoming denser in the first layers as training progresses. Experiments on BLOOM and LLaMA2 support these findings, highlighting the structural evolution of multilingual LLMs during training and scaling up. This paper provides insights into the internal workings of LLMs, offering a foundation for future improvements in their cross-lingual capabilities.
Multilingual Brain Surgeon: Large Language Models Can be Compressed Leaving No Language Behind
Apr 06, 2024



Large Language Models (LLMs) have ushered in a new era in Natural Language Processing, but their massive size demands effective compression techniques for practicality. Although numerous model compression techniques have been investigated, they typically rely on a calibration set that overlooks the multilingual context and results in significant accuracy degradation for low-resource languages. This paper introduces Multilingual Brain Surgeon (MBS), a novel calibration data sampling method for multilingual LLMs compression. MBS overcomes the English-centric limitations of existing methods by sampling calibration data from various languages proportionally to the language distribution of the model training datasets. Our experiments, conducted on the BLOOM multilingual LLM, demonstrate that MBS improves the performance of existing English-centric compression methods, especially for low-resource languages. We also uncover the dynamics of language interaction during compression, revealing that the larger the proportion of a language in the training set and the more similar the language is to the calibration language, the better performance the language retains after compression. In conclusion, MBS presents an innovative approach to compressing multilingual LLMs, addressing the performance disparities and improving the language inclusivity of existing compression techniques.