 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Aware Task Offloading in Mobile Edge Computing
Mar 16, 2026Mobile Edge Computing (MEC) technology has been introduced to enable could computing at the edge of the network in order to help resource limited mobile devices with time sensitive data processing tasks. In this paradigm, mobile devices can offload their computationally heavy tasks to more efficient nearby MEC servers via wireless communication. Consequently, the main focus of researches on the subject has been on development of efficient offloading schemes, leaving the privacy of mobile user out. While the Blockchain technology is used as the trust mechanism for secured sharing of the data, the privacy issues induced from wireless communication, namely, usage pattern and location privacy are the centerpiece of this work. The effects of these privacy concerns on the task offloading Markov Decision Process (MDP) is addressed and the MDP is solved using a Deep Recurrent Q-Netwrok (DRQN). The Numerical simulations are presented to show the effectiveness of the proposed method.
Curing Miracle Steps in LLM Mathematical Reasoning with Rubric Rewards
Oct 09, 2025Large language models for mathematical reasoning are typically trained with outcome-based rewards, which credit only the final answer. In our experiments, we observe that this paradigm is highly susceptible to reward hacking, leading to a substantial overestimation of a model's reasoning ability. This is evidenced by a high incidence of false positives - solutions that reach the correct final answer through an unsound reasoning process. Through a systematic analysis with human verification, we establish a taxonomy of these failure modes, identifying patterns like Miracle Steps - abrupt jumps to a correct output without a valid preceding derivation. Probing experiments suggest a strong association between these Miracle Steps and memorization, where the model appears to recall the answer directly rather than deriving it. To mitigate this systemic issue, we introduce the Rubric Reward Model (RRM), a process-oriented reward function that evaluates the entire reasoning trajectory against problem-specific rubrics. The generative RRM provides fine-grained, calibrated rewards (0-1) that explicitly penalize logical flaws and encourage rigorous deduction. When integrated into a reinforcement learning pipeline, RRM-based training consistently outperforms outcome-only supervision across four math benchmarks. Notably, it boosts Verified Pass@1024 on AIME2024 from 26.7% to 62.6% and reduces the incidence of Miracle Steps by 71%. Our work demonstrates that rewarding the solution process is crucial for building models that are not only more accurate but also more reliable.
Machine Learning in/for Blockchain: Future and Challenges
Sep 12, 2019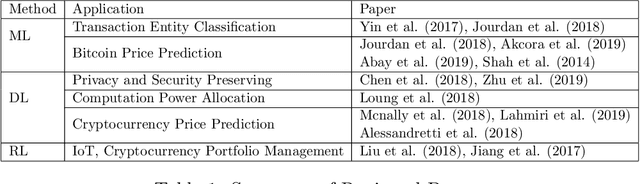
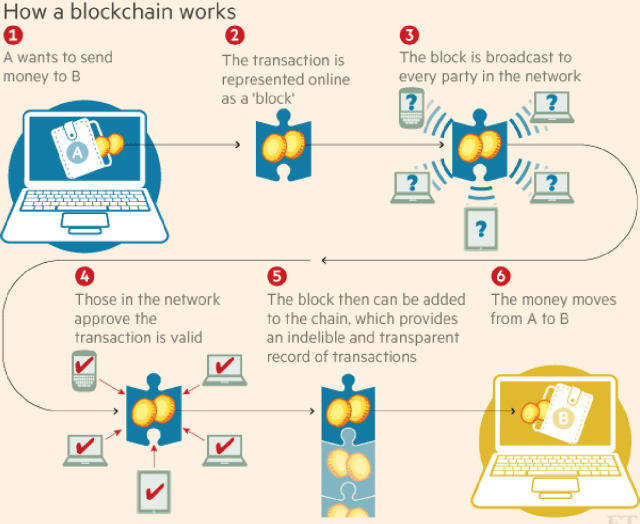
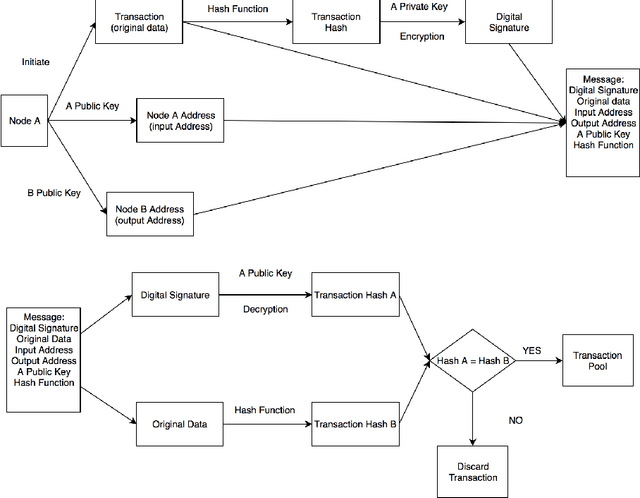
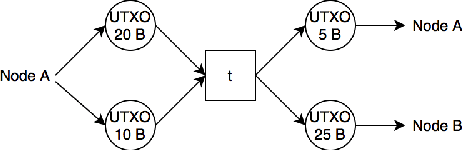
Machine learning (including deep and reinforcement learning) and blockchain are two of the most noticeable technologies in recent years. The first one is the foundation of artificial intelligence and big data, and the second one has significantly disrupted the financial industry. Both technologies are data-driven, and thus there are rapidly growing interests in integrating them for more secure and efficient data sharing and analysis. In this paper, we review the research on combining blockchain and machine learning technologies and demonstrate that they can collaborate efficiently and effectively. In the end, we point out some future directions and expect more researches on deeper integration of the two promising technologies.