 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Batch Gradient Descent Outperforms One-Pass SGD: Sample Complexity Separation in Single-Index Learning
Feb 02, 2026It is folklore that reusing training data more than once can improve the statistical efficiency of gradient-based learning. However, beyond linear regression, the theoretical advantage of full-batch gradient descent (GD, which always reuses all the data) over one-pass stochastic gradient descent (online SGD, which uses each data point only once) remains unclear. In this work, we consider learning a $d$-dimensional single-index model with a quadratic activation, for which it is known that one-pass SGD requires $n\gtrsim d\log d$ samples to achieve weak recovery. We first show that this $\log d$ factor in the sample complexity persists for full-batch spherical GD on the correlation loss; however, by simply truncating the activation, full-batch GD exhibits a favorable optimization landscape at $n \simeq d$ samples, thereby outperforming one-pass SGD (with the same activation) in statistical efficiency. We complement this result with a trajectory analysis of full-batch GD on the squared loss from small initialization, showing that $n \gtrsim d$ samples and $T \gtrsim\log d$ gradient steps suffice to achieve strong (exact) recovery.
Spectral Estimators for Structured Generalized Linear Models via Approximate Message Passing
Aug 28, 2023

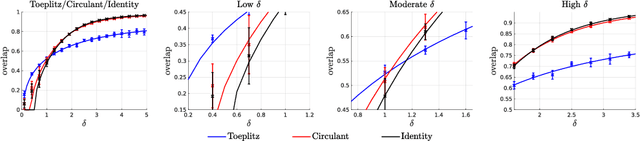

We consider the problem of parameter estimation from observations given by a generalized linear model. Spectral methods are a simple yet effective approach for estimation: they estimate the parameter via the principal eigenvector of a matrix obtained by suitably preprocessing the observations. Despite their wide use, a rigorous performance characterization of spectral estimators, as well as a principled way to preprocess the data, is available only for unstructured (i.e., i.i.d. Gaussian and Haar) designs. In contrast, real-world design matrices are highly structured and exhibit non-trivial correlations. To address this problem, we consider correlated Gaussian designs which capture the anisotropic nature of the measurements via a feature covariance matrix $\Sigma$. Our main result is a precise asymptotic characterization of the performance of spectral estimators in this setting. This then allows to identify the optimal preprocessing that minimizes the number of samples needed to meaningfully estimate the parameter. Remarkably, such an optimal spectral estimator depends on $\Sigma$ only through its normalized trace, which can be consistently estimated from the data. Numerical results demonstrate the advantage of our principled approach over previous heuristic methods. Existing analyses of spectral estimators crucially rely on the rotational invariance of the design matrix. This key assumption does not hold for correlated Gaussian designs. To circumvent this difficulty, we develop a novel strategy based on designing and analyzing an approximate message passing algorithm whose fixed point coincides with the desired spectral estimator. Our methodology is general, and opens the way to the precise characterization of spiked matrices and of the corresponding spectral methods in a variety of settings.