 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Multiple Intent Detection and Slot Filling with Supervised Contrastive Learning and Self-Distillation
Aug 28, 2023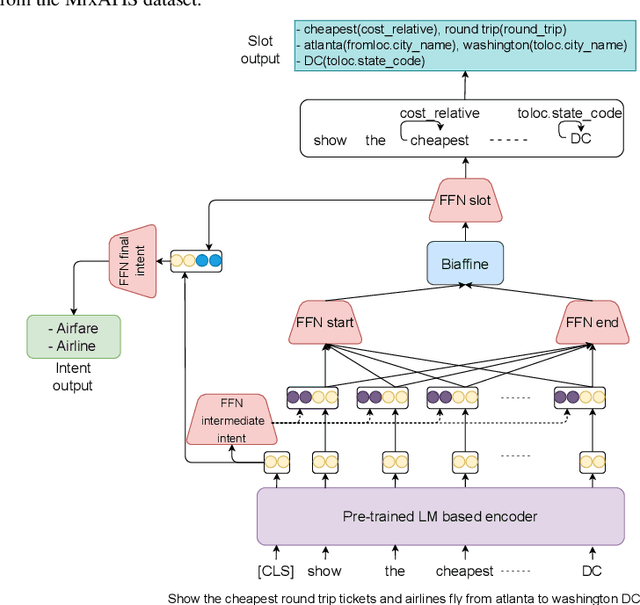
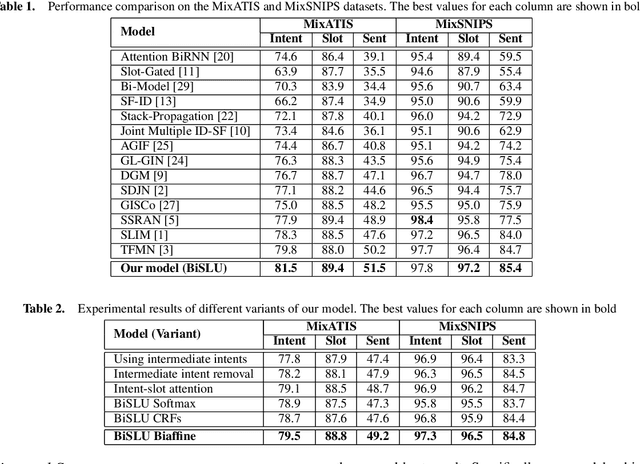
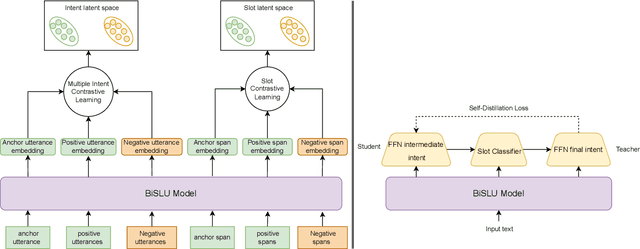
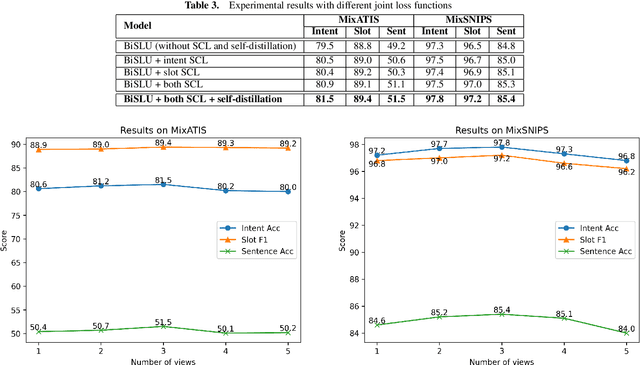
Multiple intent detection and slot filling are two fundamental and crucial tasks in spoken language understanding. Motivated by the fact that the two tasks are closely related, joint models that can detect intents and extract slots simultaneously are preferred to individual models that perform each task independently. The accuracy of a joint model depends heavily on the ability of the model to transfer information between the two tasks so that the result of one task can correct the result of the other. In addition, since a joint model has multiple outputs, how to train the model effectively is also challenging. In this paper, we present a method for multiple intent detection and slot filling by addressing these challenges. First, we propose a bidirectional joint model that explicitly employs intent information to recognize slots and slot features to detect intents. Second, we introduce a novel method for training the proposed joint model using supervised contrastive learning and self-distillation. Experimental results on two benchmark datasets MixATIS and MixSNIPS show that our method outperforms state-of-the-art models in both tasks. The results also demonstrate the contributions of both bidirectional design and the training method to the accuracy improvement. Our source code is available at https://github.com/anhtunguyen98/BiSLU
Analyzing Vietnamese Legal Questions Using Deep Neural Networks with Biaffine Classifiers
Apr 27, 2023In this paper, we propose using deep neural networks to extract important information from Vietnamese legal questions, a fundamental task towards building a question answering system in the legal domain. Given a legal question in natural language, the goal is to extract all the segments that contain the needed information to answer the question. We introduce a deep model that solves the task in three stages. First, our model leverages recent advanced autoencoding language models to produce contextual word embeddings, which are then combined with character-level and POS-tag information to form word representations. Next, bidirectional long short-term memory networks are employed to capture the relations among words and generate sentence-level representations. At the third stage, borrowing ideas from graph-based dependency parsing methods which provide a global view on the input sentence, we use biaffine classifiers to estimate the probability of each pair of start-end words to be an important segment. Experimental results on a public Vietnamese legal dataset show that our model outperforms the previous work by a large margin, achieving 94.79% in the F1 score. The results also prove the effectiveness of using contextual features extracted from pre-trained language models combined with other types of features such as character-level and POS-tag features when training on a limited dataset.
Vietnamese Capitalization and Punctuation Recovery Models
Jul 04, 2022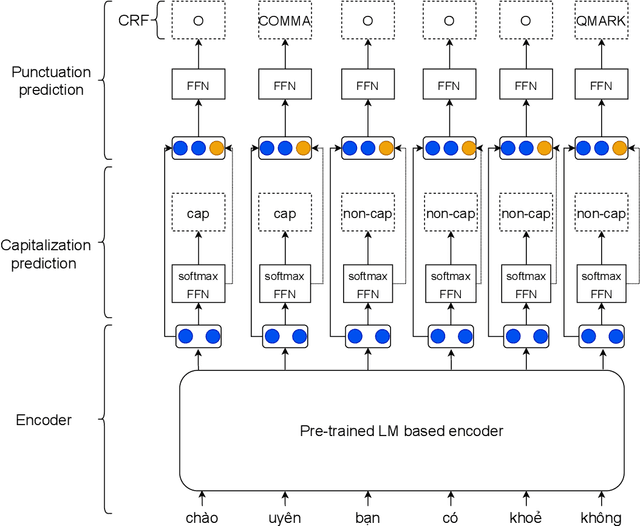
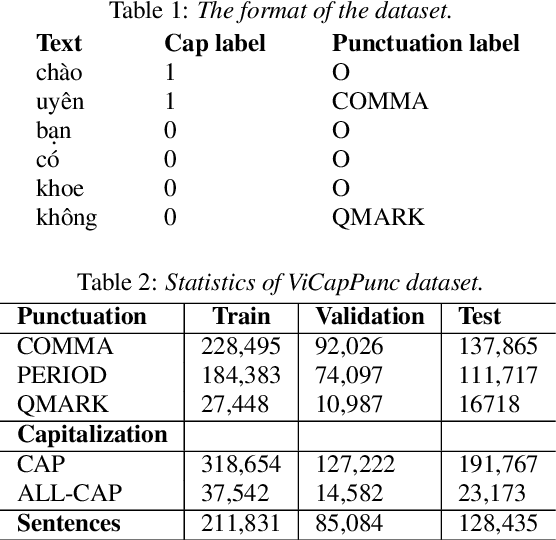
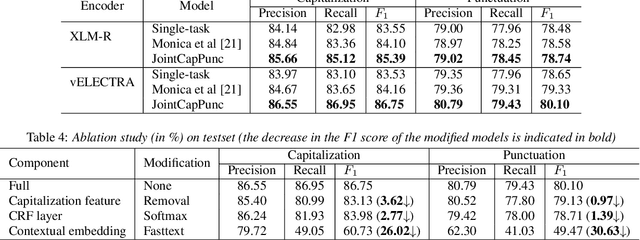
Despite the rise of recent performant methods in Automatic Speech Recognition (ASR), such methods do not ensure proper casing and punctuation for their outputs. This problem has a significant impact on the comprehension of both Natural Language Processing (NLP) algorithms and human to process. Capitalization and punctuation restoration is imperative in pre-processing pipelines for raw textual inputs. For low resource languages like Vietnamese, public datasets for this task are scarce. In this paper, we contribute a public dataset for capitalization and punctuation recovery for Vietnamese; and propose a joint model for both tasks named JointCapPunc. Experimental results on the Vietnamese dataset show the effectiveness of our joint model compare to single model and previous joint learning model. We publicly release our dataset and the implementation of our model at https://github.com/anhtunguyen98/JointCapPunc