 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Multiple Intent Detection and Slot Filling with Supervised Contrastive Learning and Self-Distillation
Aug 28, 2023Multiple intent detection and slot filling are two fundamental and crucial tasks in spoken language understanding. Motivated by the fact that the two tasks are closely related, joint models that can detect intents and extract slots simultaneously are preferred to individual models that perform each task independently. The accuracy of a joint model depends heavily on the ability of the model to transfer information between the two tasks so that the result of one task can correct the result of the other. In addition, since a joint model has multiple outputs, how to train the model effectively is also challenging. In this paper, we present a method for multiple intent detection and slot filling by addressing these challenges. First, we propose a bidirectional joint model that explicitly employs intent information to recognize slots and slot features to detect intents. Second, we introduce a novel method for training the proposed joint model using supervised contrastive learning and self-distillation. Experimental results on two benchmark datasets MixATIS and MixSNIPS show that our method outperforms state-of-the-art models in both tasks. The results also demonstrate the contributions of both bidirectional design and the training method to the accuracy improvement. Our source code is available at https://github.com/anhtunguyen98/BiSLU
Analyzing Vietnamese Legal Questions Using Deep Neural Networks with Biaffine Classifiers
Apr 27, 2023In this paper, we propose using deep neural networks to extract important information from Vietnamese legal questions, a fundamental task towards building a question answering system in the legal domain. Given a legal question in natural language, the goal is to extract all the segments that contain the needed information to answer the question. We introduce a deep model that solves the task in three stages. First, our model leverages recent advanced autoencoding language models to produce contextual word embeddings, which are then combined with character-level and POS-tag information to form word representations. Next, bidirectional long short-term memory networks are employed to capture the relations among words and generate sentence-level representations. At the third stage, borrowing ideas from graph-based dependency parsing methods which provide a global view on the input sentence, we use biaffine classifiers to estimate the probability of each pair of start-end words to be an important segment. Experimental results on a public Vietnamese legal dataset show that our model outperforms the previous work by a large margin, achieving 94.79% in the F1 score. The results also prove the effectiveness of using contextual features extracted from pre-trained language models combined with other types of features such as character-level and POS-tag features when training on a limited dataset.
Autoencoding Language Model Based Ensemble Learning for Commonsense Validation and Explanation
Apr 07, 2022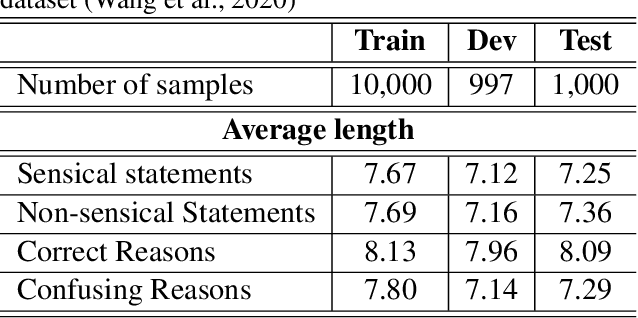
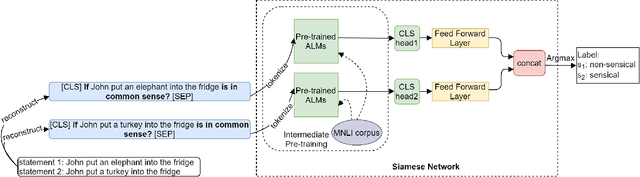
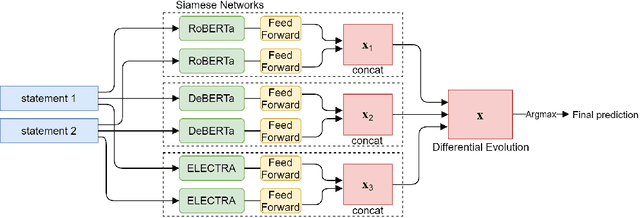
An ultimate goal of artificial intelligence is to build computer systems that can understand human languages. Understanding commonsense knowledge about the world expressed in text is one of the foundational and challenging problems to create such intelligent systems. As a step towards this goal, we present in this paper ALMEn, an Autoencoding Language Model based Ensemble learning method for commonsense validation and explanation. By ensembling several advanced pre-trained language models including RoBERTa, DeBERTa, and ELECTRA with Siamese neural networks, our method can distinguish natural language statements that are against commonsense (validation subtask) and correctly identify the reason for making against commonsense (explanation selection subtask). Experimental results on the benchmark dataset of SemEval-2020 Task 4 show that our method outperforms state-of-the-art models, reaching 97.9% and 95.4% accuracies on the validation and explanation selection subtasks, respectively.
Leveraging Foreign Language Labeled Data for Aspect-Based Opinion Mining
Mar 15, 2020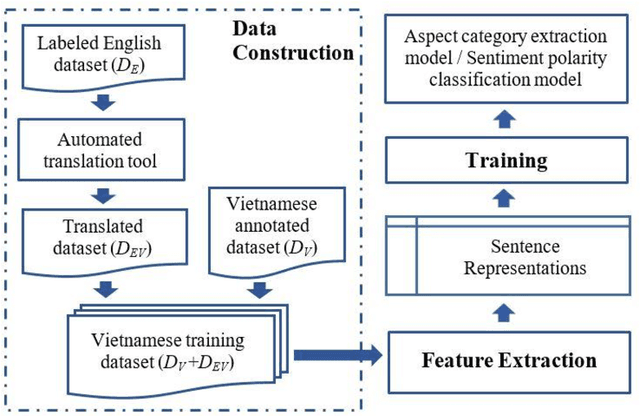

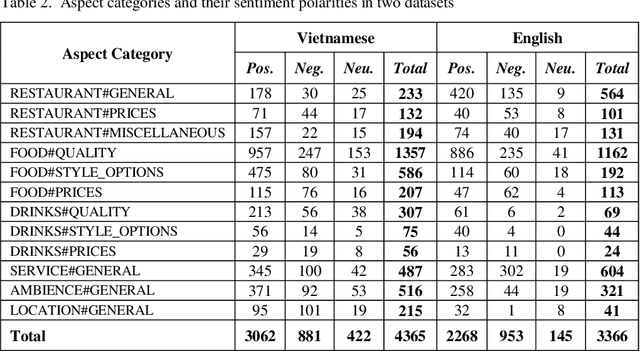
Aspect-based opinion mining is the task of identifying sentiment at the aspect level in opinionated text, which consists of two subtasks: aspect category extraction and sentiment polarity classification. While aspect category extraction aims to detect and categorize opinion targets such as product features, sentiment polarity classification assigns a sentiment label, i.e. positive, negative, or neutral, to each identified aspect. Supervised learning methods have been shown to deliver better accuracy for this task but they require labeled data, which is costly to obtain, especially for resource-poor languages like Vietnamese. To address this problem, we present a supervised aspect-based opinion mining method that utilizes labeled data from a foreign language (English in this case), which is translated to Vietnamese by an automated translation tool (Google Translate). Because aspects and opinions in different languages may be expressed by different words, we propose using word embeddings, in addition to other features, to reduce the vocabulary difference between the original and translated texts, thus improving the effectiveness of aspect category extraction and sentiment polarity classification processes. We also introduce an annotated corpus of aspect categories and sentiment polarities extracted from restaurant reviews in Vietnamese, and conduct a series of experiments on the corpus. Experimental results demonstrate the effectiveness of the proposed approach.