 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurateRAG: A Framework for Building Accurate Retrieval-Augmented Question-Answering Applications
Oct 02, 2025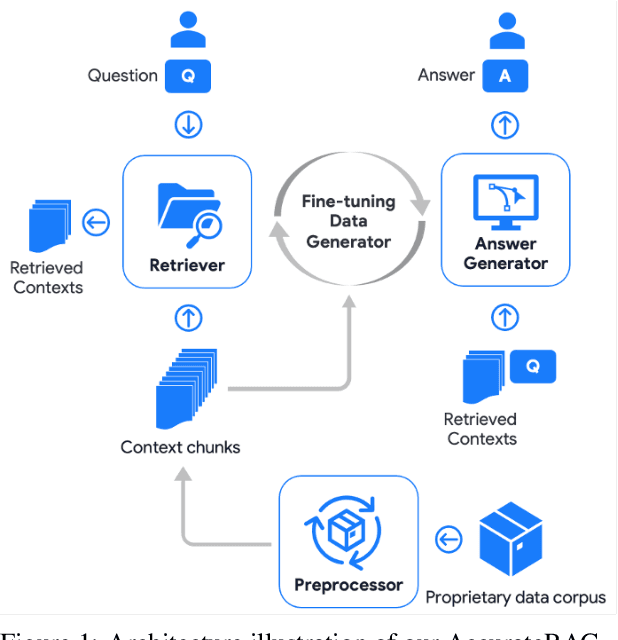

We introduce AccurateRAG -- a novel framework for constructing high-performance question-answering applications based on retrieval-augmented generation (RAG). Our framework offers a pipeline for development efficiency with tools for raw dataset processing, fine-tuning data generation, text embedding & LLM fine-tuning, output evaluation, and building RAG systems locally. Experimental results show that our framework outperforms previous strong baselines and obtains new state-of-the-art question-answering performance on benchmark datasets.
Improving Table Understanding with LLMs and Entity-Oriented Search
Aug 23, 2025Our work addresses the challenges of understanding tables. Existing methods often struggle with the unpredictable nature of table content, leading to a reliance on preprocessing and keyword matching. They also face limitations due to the lack of contextual information, which complicates the reasoning processes of large language models (LLMs). To overcome these challenges, we introduce an entity-oriented search method to improve table understanding with LLMs. This approach effectively leverages the semantic similarities between questions and table data, as well as the implicit relationships between table cells, minimizing the need for data preprocessing and keyword matching. Additionally, it focuses on table entities, ensuring that table cells are semantically tightly bound, thereby enhancing contextual clarity. Furthermore, we pioneer the use of a graph query language for table understanding, establishing a new research direction. Experiments show that our approach achieves new state-of-the-art performances on standard benchmarks WikiTableQuestions and TabFact.
Planning for Success: Exploring LLM Long-term Planning Capabilities in Table Understanding
Aug 23, 2025Table understanding is key to addressing challenging downstream tasks such as table-based question answering and fact verification. Recent works have focused on leveraging Chain-of-Thought and question decomposition to solve complex questions requiring multiple operations on tables. However, these methods often suffer from a lack of explicit long-term planning and weak inter-step connections, leading to miss constraints within questions. In this paper, we propose leveraging the long-term planning capabilities of large language models (LLMs) to enhance table understanding. Our approach enables the execution of a long-term plan, where the steps are tightly interconnected and serve the ultimate goal, an aspect that methods based on Chain-of-Thought and question decomposition lack. In addition, our method effectively minimizes the inclusion of unnecessary details in the process of solving the next short-term goals, a limitation of methods based on Chain-of-Thought. Extensive experiments demonstrate that our method outperforms strong baselines and achieves state-of-the-art performance on WikiTableQuestions and TabFact datasets.
Who's Who: Large Language Models Meet Knowledge Conflicts in Practice
Oct 21, 2024

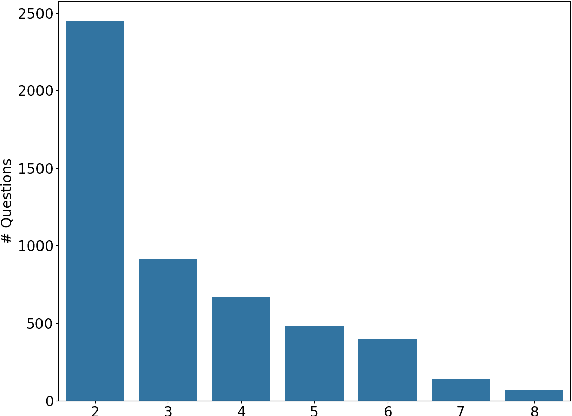
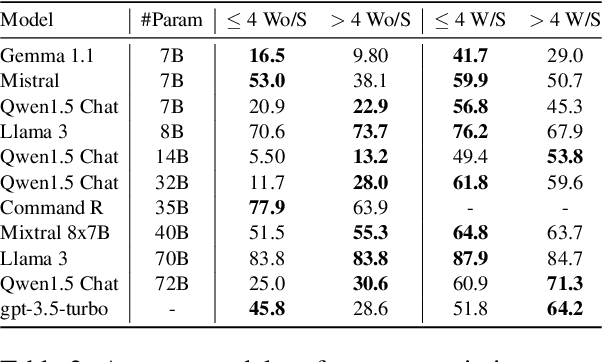
Retrieval-augmented generation (RAG) methods are viable solutions for addressing the static memory limits of pre-trained language models. Nevertheless, encountering conflicting sources of information within the retrieval context is an inevitable practical challenge. In such situations, the language models are recommended to transparently inform users about the conflicts rather than autonomously deciding what to present based on their inherent biases. To analyze how current large language models (LLMs) align with our recommendation, we introduce WhoQA, a public benchmark dataset to examine model's behavior in knowledge conflict situations. We induce conflicts by asking about a common property among entities having the same name, resulting in questions with up to 8 distinctive answers. WhoQA evaluation set includes 5K questions across 13 Wikidata property types and 150K Wikipedia entities. Our experiments show that despite the simplicity of WhoQA questions, knowledge conflicts significantly degrades LLMs' performance in RAG settings.
RecGPT: Generative Pre-training for Text-based Recommendation
May 21, 2024



We present the first domain-adapted and fully-trained large language model, RecGPT-7B, and its instruction-following variant, RecGPT-7B-Instruct, for text-based recommendation. Experimental results on rating prediction and sequential recommendation tasks show that our model, RecGPT-7B-Instruct, outperforms previous strong baselines. We are releasing our RecGPT models as well as their pre-training and fine-tuning datasets to facilitate future research and downstream applications in text-based recommendation. Public "huggingface" links to our RecGPT models and datasets are available at: https://github.com/VinAIResearch/RecGPT
A Self-enhancement Multitask Framework for Unsupervised Aspect Category Detection
Nov 16, 2023Our work addresses the problem of unsupervised Aspect Category Detection using a small set of seed words. Recent works have focused on learning embedding spaces for seed words and sentences to establish similarities between sentences and aspects. However, aspect representations are limited by the quality of initial seed words, and model performances are compromised by noise. To mitigate this limitation, we propose a simple framework that automatically enhances the quality of initial seed words and selects high-quality sentences for training instead of using the entire dataset. Our main concepts are to add a number of seed words to the initial set and to treat the task of noise resolution as a task of augmenting data for a low-resource task. In addition, we jointly train Aspect Category Detection with Aspect Term Extraction and Aspect Term Polarity to further enhance performance. This approach facilitates shared representation learning, allowing Aspect Category Detection to benefit from the additional guidance offered by other tasks. Extensive experiments demonstrate that our framework surpasses strong baselines on standard datasets.