 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClozeMath: Improving Mathematical Reasoning in Language Models by Learning to Fill Equations
Jun 04, 2025The capabilities of large language models (LLMs) have been enhanced by training on data that reflects human thought processes, such as the Chain-of-Thought format. However, evidence suggests that the conventional scheme of next-word prediction may not fully capture how humans learn to think. Inspired by how humans generalize mathematical reasoning, we propose a new approach named ClozeMath to fine-tune LLMs for mathematical reasoning. Our ClozeMath involves a text-infilling task that predicts masked equations from a given solution, analogous to cloze exercises used in human learning. Experiments on GSM8K, MATH, and GSM-Symbolic show that ClozeMath surpasses the strong baseline Masked Thought in performance and robustness, with two test-time scaling decoding algorithms, Beam Search and Chain-of-Thought decoding. Additionally, we conduct an ablation study to analyze the effects of various architectural and implementation choices on our approach.
Who's Who: Large Language Models Meet Knowledge Conflicts in Practice
Oct 21, 2024

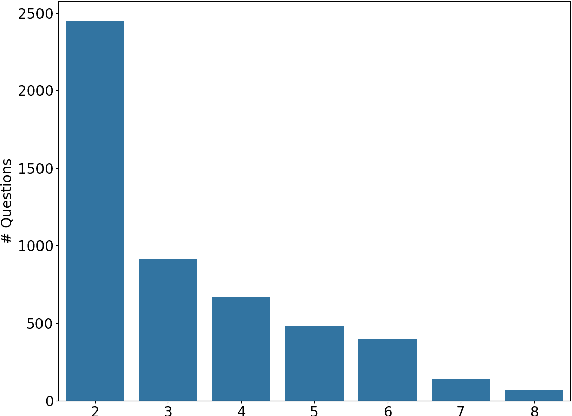
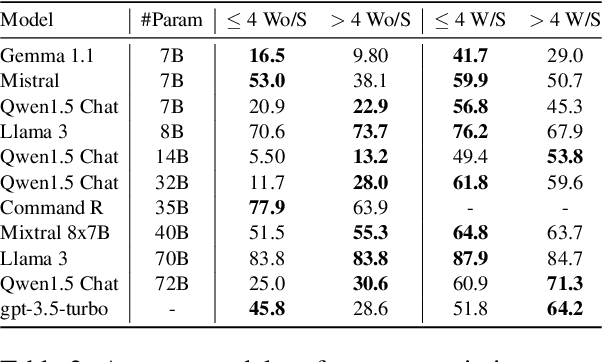
Retrieval-augmented generation (RAG) methods are viable solutions for addressing the static memory limits of pre-trained language models. Nevertheless, encountering conflicting sources of information within the retrieval context is an inevitable practical challenge. In such situations, the language models are recommended to transparently inform users about the conflicts rather than autonomously deciding what to present based on their inherent biases. To analyze how current large language models (LLMs) align with our recommendation, we introduce WhoQA, a public benchmark dataset to examine model's behavior in knowledge conflict situations. We induce conflicts by asking about a common property among entities having the same name, resulting in questions with up to 8 distinctive answers. WhoQA evaluation set includes 5K questions across 13 Wikidata property types and 150K Wikipedia entities. Our experiments show that despite the simplicity of WhoQA questions, knowledge conflicts significantly degrades LLMs' performance in RAG settings.