 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-enhancement Multitask Framework for Unsupervised Aspect Category Detection
Nov 16, 2023Our work addresses the problem of unsupervised Aspect Category Detection using a small set of seed words. Recent works have focused on learning embedding spaces for seed words and sentences to establish similarities between sentences and aspects. However, aspect representations are limited by the quality of initial seed words, and model performances are compromised by noise. To mitigate this limitation, we propose a simple framework that automatically enhances the quality of initial seed words and selects high-quality sentences for training instead of using the entire dataset. Our main concepts are to add a number of seed words to the initial set and to treat the task of noise resolution as a task of augmenting data for a low-resource task. In addition, we jointly train Aspect Category Detection with Aspect Term Extraction and Aspect Term Polarity to further enhance performance. This approach facilitates shared representation learning, allowing Aspect Category Detection to benefit from the additional guidance offered by other tasks. Extensive experiments demonstrate that our framework surpasses strong baselines on standard datasets.
A practical method for occupational skills detection in Vietnamese job listings
Oct 26, 2022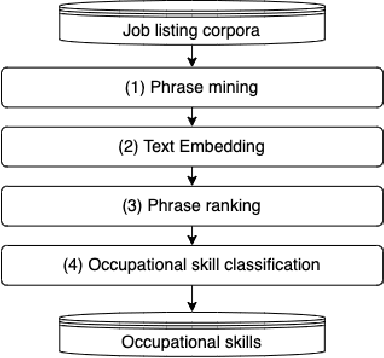
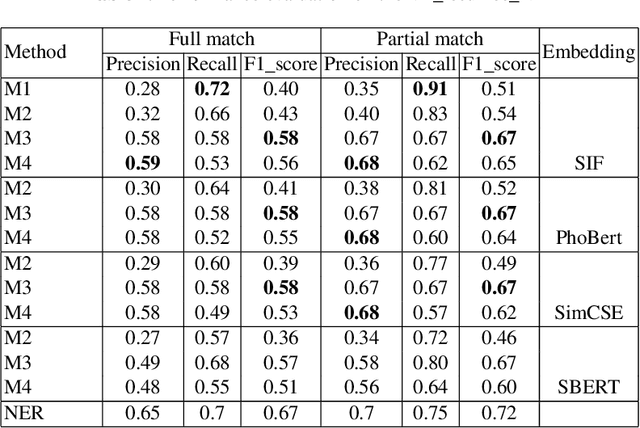
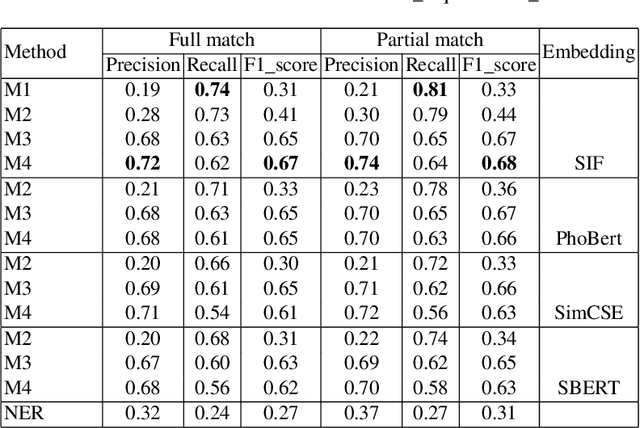
Vietnamese labor market has been under an imbalanced development. The number of university graduates is growing, but so is the unemployment rate. This situation is often caused by the lack of accurate and timely labor market information, which leads to skill miss-matches between worker supply and the actual market demands. To build a data monitoring and analytic platform for the labor market, one of the main challenges is to be able to automatically detect occupational skills from labor-related data, such as resumes and job listings. Traditional approaches rely on existing taxonomy and/or large annotated data to build Named Entity Recognition (NER) models. They are expensive and require huge manual efforts. In this paper, we propose a practical methodology for skill detection in Vietnamese job listings. Rather than viewing the task as a NER task, we consider the task as a ranking problem. We propose a pipeline in which phrases are first extracted and ranked in semantic similarity with the phrases' contexts. Then we employ a final classification to detect skill phrases. We collected three datasets and conducted extensive experiments. The results demonstrated that our methodology achieved better performance than a NER model in scarce datasets.