 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA practical method for occupational skills detection in Vietnamese job listings
Paper and Code
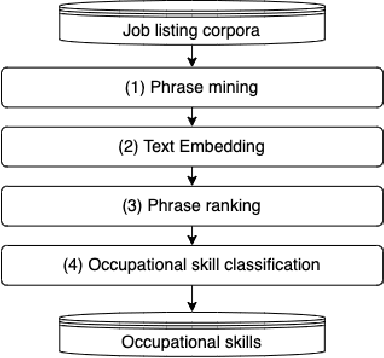
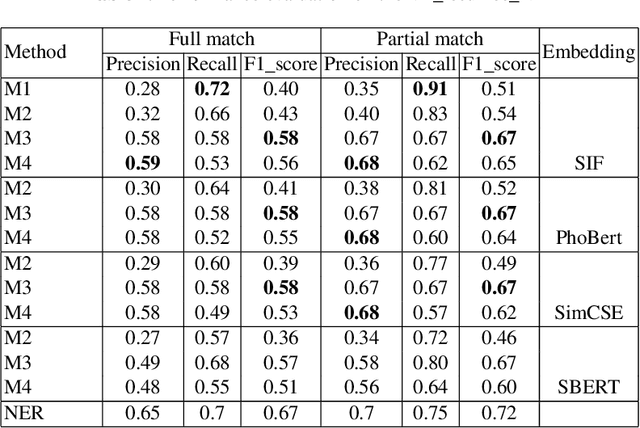
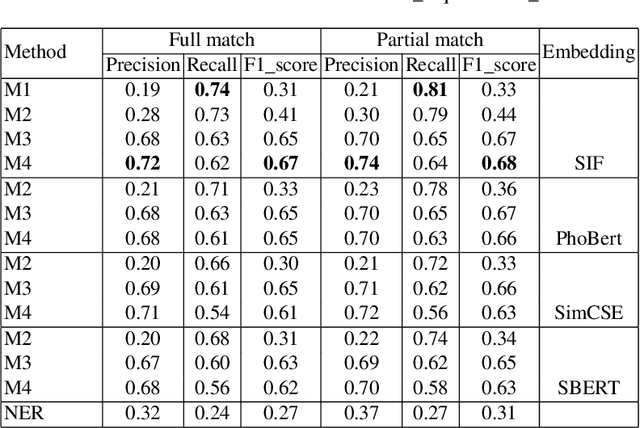
Vietnamese labor market has been under an imbalanced development. The number of university graduates is growing, but so is the unemployment rate. This situation is often caused by the lack of accurate and timely labor market information, which leads to skill miss-matches between worker supply and the actual market demands. To build a data monitoring and analytic platform for the labor market, one of the main challenges is to be able to automatically detect occupational skills from labor-related data, such as resumes and job listings. Traditional approaches rely on existing taxonomy and/or large annotated data to build Named Entity Recognition (NER) models. They are expensive and require huge manual efforts. In this paper, we propose a practical methodology for skill detection in Vietnamese job listings. Rather than viewing the task as a NER task, we consider the task as a ranking problem. We propose a pipeline in which phrases are first extracted and ranked in semantic similarity with the phrases' contexts. Then we employ a final classification to detect skill phrases. We collected three datasets and conducted extensive experiments. The results demonstrated that our methodology achieved better performance than a NER model in scarce datasets.