 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Vectorization with Depth: convexified shape layers with depth ordering
Sep 10, 2024
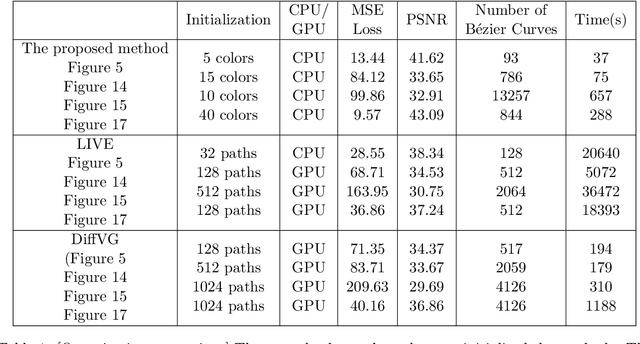
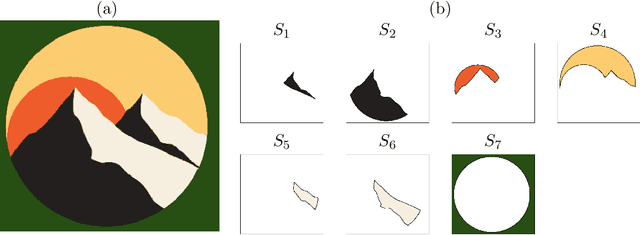
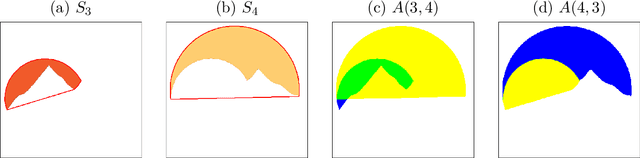
Image vectorization is a process to convert a raster image into a scalable vector graphic format. Objective is to effectively remove the pixelization effect while representing boundaries of image by scaleable parameterized curves. We propose new image vectorization with depth which considers depth ordering among shapes and use curvature-based inpainting for convexifying shapes in vectorization process.From a given color quantized raster image, we first define each connected component of the same color as a shape layer, and construct depth ordering among them using a newly proposed depth ordering energy. Global depth ordering among all shapes is described by a directed graph, and we propose an energy to remove cycle within the graph. After constructing depth ordering of shapes, we convexify occluded regions by Euler's elastica curvature-based variational inpainting, and leverage on the stability of Modica-Mortola double-well potential energy to inpaint large regions. This is following human vision perception that boundaries of shapes extend smoothly, and we assume shapes are likely to be convex. Finally, we fit B\'{e}zier curves to the boundaries and save vectorization as a SVG file which allows superposition of curvature-based inpainted shapes following the depth ordering. This is a new way to vectorize images, by decomposing an image into scalable shape layers with computed depth ordering. This approach makes editing shapes and images more natural and intuitive. We also consider grouping shape layers for semantic vectorization. We present various numerical results and comparisons against recent layer-based vectorization methods to validate the proposed model.
CNN-Driven Quasiconformal Model for Large Deformation Image Registration
Oct 30, 2020

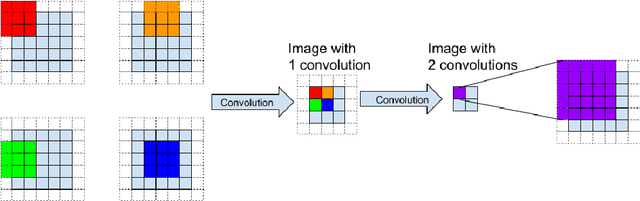

We present a novel way to perform image registration, which is not limited to a specific kind, between image pairs with very large deformation, while preserving Quasiconformal property without tedious manual landmark labeling that conventional mathematical registration methods require. Alongside the practical function of our algorithm, one just-as-important underlying message is that the integration between typical CNN and existing Mathematical model is successful as will be pointed out by our paper, meaning that machine learning and mathematical model could coexist, cover for each other and significantly improve registration result. This paper will demonstrate an unprecedented idea of making use of both robustness of CNNs and rigorousness of mathematical model to obtain meaningful registration maps between 2D images under the aforementioned strict constraints for the sake of well-posedness.
Decomposition of Longitudinal Deformations via Beltrami Descriptors
Aug 06, 2020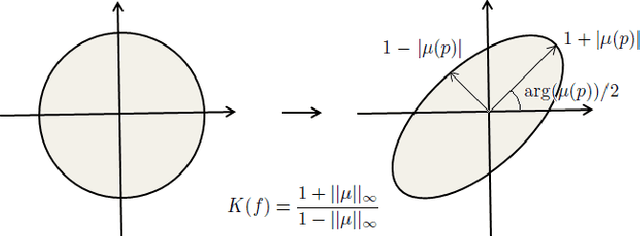

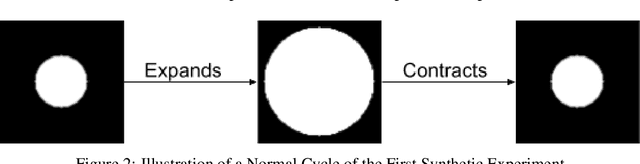

We present a mathematical model to decompose a longitudinal deformation into normal and abnormal components. The goal is to detect and extract subtle quivers from periodic motions in a video sequence. It has important applications in medical image analysis. To achieve this goal, we consider a representation of the longitudinal deformation, called the Beltrami descriptor, based on quasiconformal theories. The Beltrami descriptor is a complex-valued matrix. Each longitudinal deformation is associated to a Beltrami descriptor and vice versa. To decompose the longitudinal deformation, we propose to carry out the low rank and sparse decomposition of the Beltrami descriptor. The low rank component corresponds to the periodic motions, whereas the sparse part corresponds to the abnormal motions of a longitudinal deformation. Experiments have been carried out on both synthetic and real video sequences. Results demonstrate the efficacy of our proposed model to decompose a longitudinal deformation into regular and irregular components.