 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuon Converges under Heavy-Tailed Noise: Nonconvex Hölder-Smooth Empirical Risk Minimization
Mar 17, 2026Muon is a recently proposed optimizer that enforces orthogonality in parameter updates by projecting gradients onto the Stiefel manifold, leading to stable and efficient training in large-scale deep neural networks. Meanwhile, the previously reported results indicated that stochastic noise in practical machine learning may exhibit heavy-tailed behavior, violating the bounded-variance assumption. In this paper, we consider the problem of minimizing a nonconvex Hölder-smooth empirical risk that works well with the heavy-tailed stochastic noise. We then show that Muon converges to a stationary point of the empirical risk under the boundedness condition accounting for heavy-tailed stochastic noise. In addition, we show that Muon converges faster than mini-batch SGD.
Lipschitz Multiscale Deep Equilibrium Models: A Theoretically Guaranteed and Accelerated Approach
Feb 03, 2026Deep equilibrium models (DEQs) achieve infinitely deep network representations without stacking layers by exploring fixed points of layer transformations in neural networks. Such models constitute an innovative approach that achieves performance comparable to state-of-the-art methods in many large-scale numerical experiments, despite requiring significantly less memory. However, DEQs face the challenge of requiring vastly more computational time for training and inference than conventional methods, as they repeatedly perform fixed-point iterations with no convergence guarantee upon each input. Therefore, this study explored an approach to improve fixed-point convergence and consequently reduce computational time by restructuring the model architecture to guarantee fixed-point convergence. Our proposed approach for image classification, Lipschitz multiscale DEQ, has theoretically guaranteed fixed-point convergence for both forward and backward passes by hyperparameter adjustment, achieving up to a 4.75$\times$ speed-up in numerical experiments on CIFAR-10 at the cost of a minor drop in accuracy.
Improved Convergence Rates of Muon Optimizer for Nonconvex Optimization
Jan 27, 2026The Muon optimizer has recently attracted attention due to its orthogonalized first-order updates, and a deeper theoretical understanding of its convergence behavior is essential for guiding practical applications; however, existing convergence guarantees are either coarse or obtained under restrictive analytical settings. In this work, we establish sharper convergence guarantees for the Muon optimizer through a direct and simplified analysis that does not rely on restrictive assumptions on the update rule. Our results improve upon existing bounds by achieving faster convergence rates while covering a broader class of problem settings. These findings provide a more accurate theoretical characterization of Muon and offer insights applicable to a broader class of orthogonalized first-order methods.
Convergence Analysis of SGD under Expected Smoothness
Oct 23, 2025Stochastic gradient descent (SGD) is the workhorse of large-scale learning, yet classical analyses rely on assumptions that can be either too strong (bounded variance) or too coarse (uniform noise). The expected smoothness (ES) condition has emerged as a flexible alternative that ties the second moment of stochastic gradients to the objective value and the full gradient. This paper presents a self-contained convergence analysis of SGD under ES. We (i) refine ES with interpretations and sampling-dependent constants; (ii) derive bounds of the expectation of squared full gradient norm; and (iii) prove $O(1/K)$ rates with explicit residual errors for various step-size schedules. All proofs are given in full detail in the appendix. Our treatment unifies and extends recent threads (Khaled and Richt\'arik, 2020; Umeda and Iiduka, 2025).
Adaptive Batch Size and Learning Rate Scheduler for Stochastic Gradient Descent Based on Minimization of Stochastic First-order Oracle Complexity
Aug 07, 2025The convergence behavior of mini-batch stochastic gradient descent (SGD) is highly sensitive to the batch size and learning rate settings. Recent theoretical studies have identified the existence of a critical batch size that minimizes stochastic first-order oracle (SFO) complexity, defined as the expected number of gradient evaluations required to reach a stationary point of the empirical loss function in a deep neural network. An adaptive scheduling strategy is introduced to accelerate SGD that leverages theoretical findings on the critical batch size. The batch size and learning rate are adjusted on the basis of the observed decay in the full gradient norm during training. Experiments using an adaptive joint scheduler based on this strategy demonstrated improved convergence speed compared with that of existing schedulers.
Optimal Growth Schedules for Batch Size and Learning Rate in SGD that Reduce SFO Complexity
Aug 07, 2025
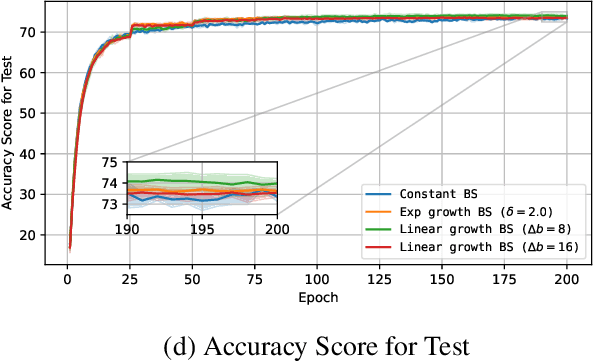
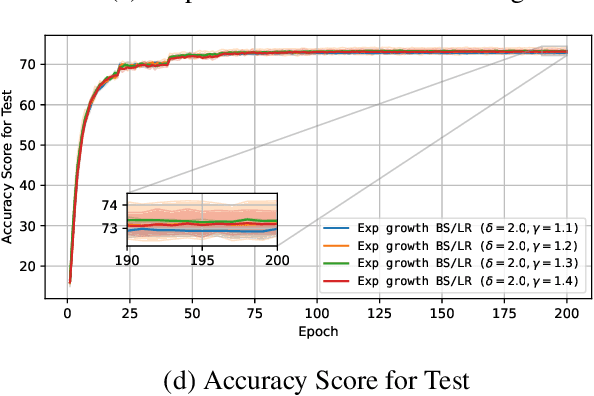
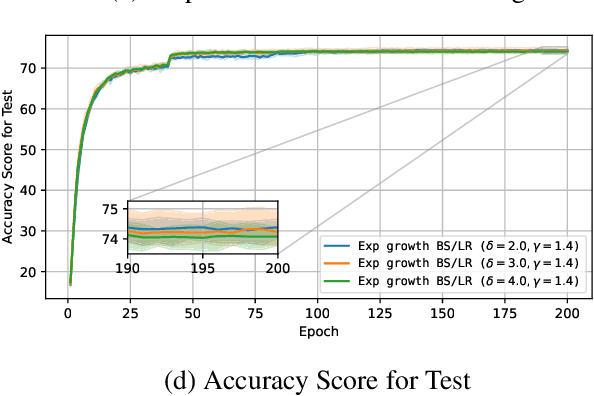
The unprecedented growth of deep learning models has enabled remarkable advances but introduced substantial computational bottlenecks. A key factor contributing to training efficiency is batch-size and learning-rate scheduling in stochastic gradient methods. However, naive scheduling of these hyperparameters can degrade optimization efficiency and compromise generalization. Motivated by recent theoretical insights, we investigated how the batch size and learning rate should be increased during training to balance efficiency and convergence. We analyzed this problem on the basis of stochastic first-order oracle (SFO) complexity, defined as the expected number of gradient evaluations needed to reach an $\epsilon$-approximate stationary point of the empirical loss. We theoretically derived optimal growth schedules for the batch size and learning rate that reduce SFO complexity and validated them through extensive experiments. Our results offer both theoretical insights and practical guidelines for scalable and efficient large-batch training in deep learning.
Analysis of Muon's Convergence and Critical Batch Size
Jul 02, 2025This paper presents a theoretical analysis of Muon, a new optimizer that leverages the inherent matrix structure of neural network parameters. We provide convergence proofs for four practical variants of Muon: with and without Nesterov momentum, and with and without weight decay. We then show that adding weight decay leads to strictly tighter bounds on both the parameter and gradient norms, and we clarify the relationship between the weight decay coefficient and the learning rate. Finally, we derive Muon's critical batch size minimizing the stochastic first-order oracle (SFO) complexity, which is the stochastic computational cost, and validate our theoretical findings with experiments.
Faster Convergence of Riemannian Stochastic Gradient Descent with Increasing Batch Size
Jan 30, 2025



Many models used in machine learning have become so large that even computer computation of the full gradient of the loss function is impractical. This has made it necessary to efficiently train models using limited available information, such as batch size and learning rate. We have theoretically analyzed the use of Riemannian stochastic gradient descent (RSGD) and found that using an increasing batch size leads to faster RSGD convergence than using a constant batch size not only with a constant learning rate but also with a decaying learning rate, such as cosine annealing decay and polynomial decay. In particular, RSGD has a better convergence rate $O(\frac{1}{\sqrt{T}})$ than the existing rate $O(\frac{\sqrt{\log T}}{\sqrt[4]{T}})$ with a diminishing learning rate, where $T$ is the number of iterations. The results of experiments on principal component analysis and low-rank matrix completion problems confirmed that, except for the MovieLens dataset and a constant learning rate, using a polynomial growth batch size or an exponential growth batch size results in better performance than using a constant batch size.
Increasing Batch Size Improves Convergence of Stochastic Gradient Descent with Momentum
Jan 15, 2025



Stochastic gradient descent with momentum (SGDM), which is defined by adding a momentum term to SGD, has been well studied in both theory and practice. Theoretically investigated results showed that the settings of the learning rate and momentum weight affect the convergence of SGDM. Meanwhile, practical results showed that the setting of batch size strongly depends on the performance of SGDM. In this paper, we focus on mini-batch SGDM with constant learning rate and constant momentum weight, which is frequently used to train deep neural networks in practice. The contribution of this paper is showing theoretically that using a constant batch size does not always minimize the expectation of the full gradient norm of the empirical loss in training a deep neural network, whereas using an increasing batch size definitely minimizes it, that is, increasing batch size improves convergence of mini-batch SGDM. We also provide numerical results supporting our analyses, indicating specifically that mini-batch SGDM with an increasing batch size converges to stationary points faster than with a constant batch size. Python implementations of the optimizers used in the numerical experiments are available at https://anonymous.4open.science/r/momentum-increasing-batch-size-888C/.
Scaled Conjugate Gradient Method for Nonconvex Optimization in Deep Neural Networks
Dec 16, 2024A scaled conjugate gradient method that accelerates existing adaptive methods utilizing stochastic gradients is proposed for solving nonconvex optimization problems with deep neural networks. It is shown theoretically that, whether with constant or diminishing learning rates, the proposed method can obtain a stationary point of the problem. Additionally, its rate of convergence with diminishing learning rates is verified to be superior to that of the conjugate gradient method. The proposed method is shown to minimize training loss functions faster than the existing adaptive methods in practical applications of image and text classification. Furthermore, in the training of generative adversarial networks, one version of the proposed method achieved the lowest Frechet inception distance score among those of the adaptive methods.