 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Growth Schedules for Batch Size and Learning Rate in SGD that Reduce SFO Complexity
Aug 07, 2025
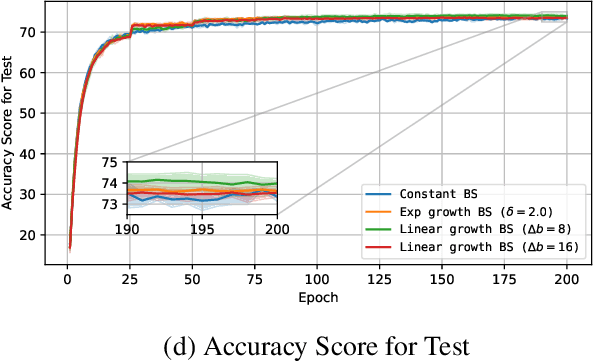
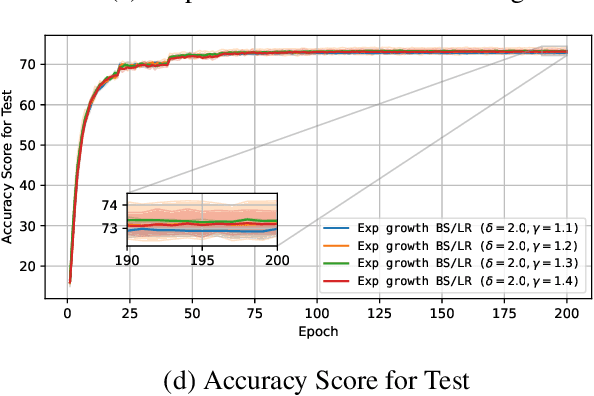
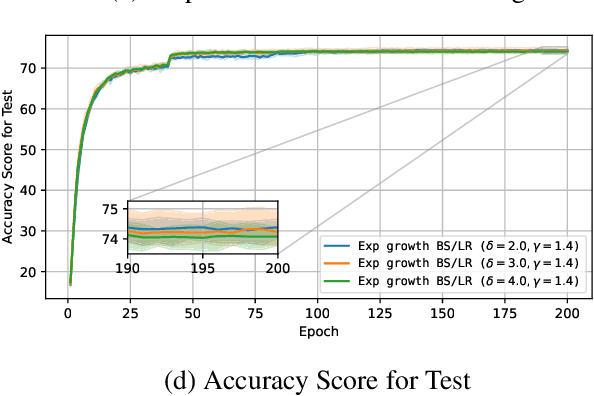
The unprecedented growth of deep learning models has enabled remarkable advances but introduced substantial computational bottlenecks. A key factor contributing to training efficiency is batch-size and learning-rate scheduling in stochastic gradient methods. However, naive scheduling of these hyperparameters can degrade optimization efficiency and compromise generalization. Motivated by recent theoretical insights, we investigated how the batch size and learning rate should be increased during training to balance efficiency and convergence. We analyzed this problem on the basis of stochastic first-order oracle (SFO) complexity, defined as the expected number of gradient evaluations needed to reach an $\epsilon$-approximate stationary point of the empirical loss. We theoretically derived optimal growth schedules for the batch size and learning rate that reduce SFO complexity and validated them through extensive experiments. Our results offer both theoretical insights and practical guidelines for scalable and efficient large-batch training in deep learning.
Adaptive Batch Size and Learning Rate Scheduler for Stochastic Gradient Descent Based on Minimization of Stochastic First-order Oracle Complexity
Aug 07, 2025The convergence behavior of mini-batch stochastic gradient descent (SGD) is highly sensitive to the batch size and learning rate settings. Recent theoretical studies have identified the existence of a critical batch size that minimizes stochastic first-order oracle (SFO) complexity, defined as the expected number of gradient evaluations required to reach a stationary point of the empirical loss function in a deep neural network. An adaptive scheduling strategy is introduced to accelerate SGD that leverages theoretical findings on the critical batch size. The batch size and learning rate are adjusted on the basis of the observed decay in the full gradient norm during training. Experiments using an adaptive joint scheduler based on this strategy demonstrated improved convergence speed compared with that of existing schedulers.
Increasing Both Batch Size and Learning Rate Accelerates Stochastic Gradient Descent
Sep 13, 2024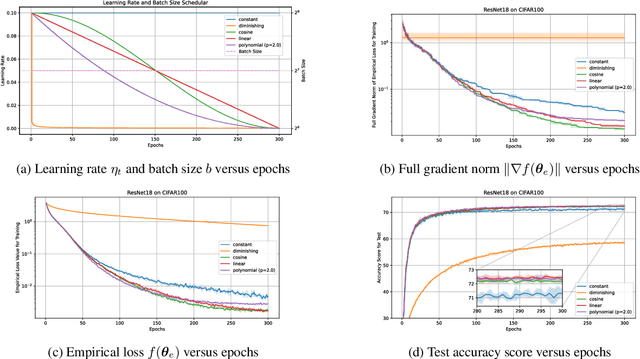
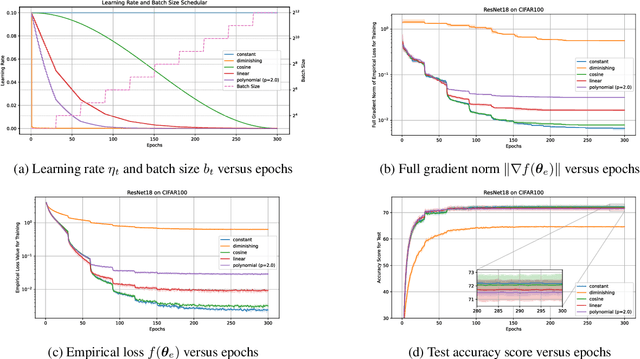
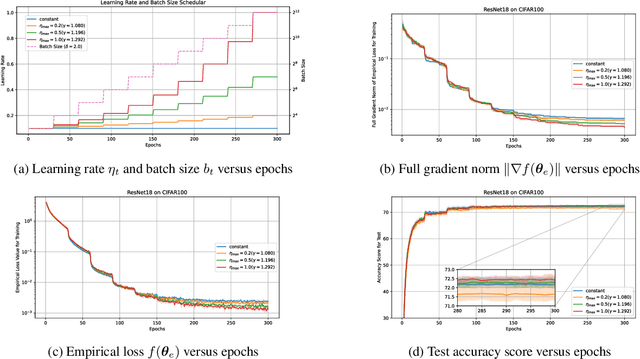
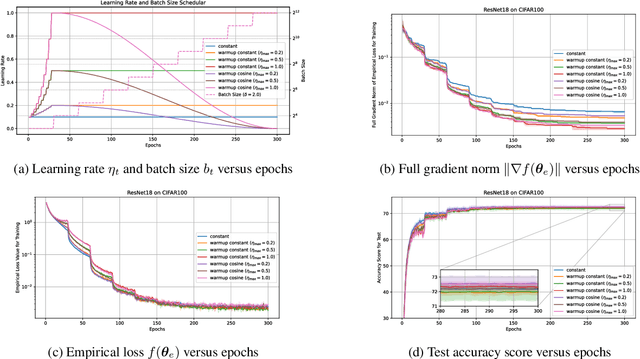
The performance of mini-batch stochastic gradient descent (SGD) strongly depends on setting the batch size and learning rate to minimize the empirical loss in training the deep neural network. In this paper, we present theoretical analyses of mini-batch SGD with four schedulers: (i) constant batch size and decaying learning rate scheduler, (ii) increasing batch size and decaying learning rate scheduler, (iii) increasing batch size and increasing learning rate scheduler, and (iv) increasing batch size and warm-up decaying learning rate scheduler. We show that mini-batch SGD using scheduler (i) does not always minimize the expectation of the full gradient norm of the empirical loss, whereas it does using any of schedulers (ii), (iii), and (iv). Furthermore, schedulers (iii) and (iv) accelerate mini-batch SGD. The paper also provides numerical results of supporting analyses showing that using scheduler (iii) or (iv) minimizes the full gradient norm of the empirical loss faster than using scheduler (i) or (ii).