 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerMedCQA: Benchmarking Large Language Models on Medical Consumer Question Answering in Persian Language
May 23, 2025Medical consumer question answering (CQA) is crucial for empowering patients by providing personalized and reliable health information. Despite recent advances in large language models (LLMs) for medical QA, consumer-oriented and multilingual resources, particularly in low-resource languages like Persian, remain sparse. To bridge this gap, we present PerMedCQA, the first Persian-language benchmark for evaluating LLMs on real-world, consumer-generated medical questions. Curated from a large medical QA forum, PerMedCQA contains 68,138 question-answer pairs, refined through careful data cleaning from an initial set of 87,780 raw entries. We evaluate several state-of-the-art multilingual and instruction-tuned LLMs, utilizing MedJudge, a novel rubric-based evaluation framework driven by an LLM grader, validated against expert human annotators. Our results highlight key challenges in multilingual medical QA and provide valuable insights for developing more accurate and context-aware medical assistance systems. The data is publicly available on https://huggingface.co/datasets/NaghmehAI/PerMedCQA
Enhancing Few-Shot Transfer Learning with Optimized Multi-Task Prompt Tuning through Modular Prompt Composition
Aug 23, 2024In recent years, multi-task prompt tuning has garnered considerable attention for its inherent modularity and potential to enhance parameter-efficient transfer learning across diverse tasks. This paper aims to analyze and improve the performance of multiple tasks by facilitating the transfer of knowledge between their corresponding prompts in a multi-task setting. Our proposed approach decomposes the prompt for each target task into a combination of shared prompts (source prompts) and a task-specific prompt (private prompt). During training, the source prompts undergo fine-tuning and are integrated with the private prompt to drive the target prompt for each task. We present and compare multiple methods for combining source prompts to construct the target prompt, analyzing the roles of both source and private prompts within each method. We investigate their contributions to task performance and offer flexible, adjustable configurations based on these insights to optimize performance. Our empirical findings clearly showcase improvements in accuracy and robustness compared to the conventional practice of prompt tuning and related works. Notably, our results substantially outperform other methods in the field in few-shot settings, demonstrating superior performance in various tasks across GLUE benchmark, among other tasks. This achievement is attained with a significantly reduced amount of training data, making our method a promising one for few-shot settings.
PerCQA: Persian Community Question Answering Dataset
Dec 25, 2021



Community Question Answering (CQA) forums provide answers for many real-life questions. Thanks to the large size, these forums are very popular among machine learning researchers. Automatic answer selection, answer ranking, question retrieval, expert finding, and fact-checking are example learning tasks performed using CQA data. In this paper, we present PerCQA, the first Persian dataset for CQA. This dataset contains the questions and answers crawled from the most well-known Persian forum. After data acquisition, we provide rigorous annotation guidelines in an iterative process, and then the annotation of question-answer pairs in SemEvalCQA format. PerCQA contains 989 questions and 21,915 annotated answers. We make PerCQA publicly available to encourage more research in Persian CQA. We also build strong benchmarks for the task of answer selection in PerCQA by using mono- and multi-lingual pre-trained language models
Using BERT Encoding and Sentence-Level Language Model for Sentence Ordering
Aug 24, 2021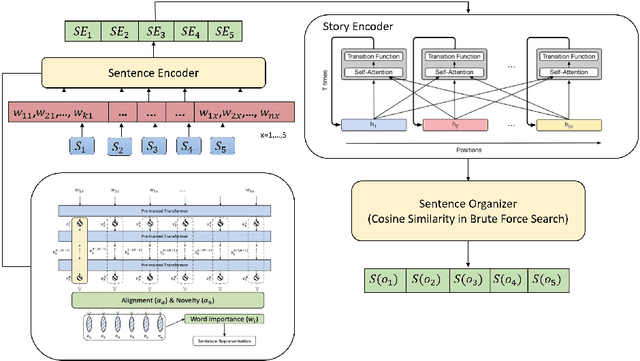


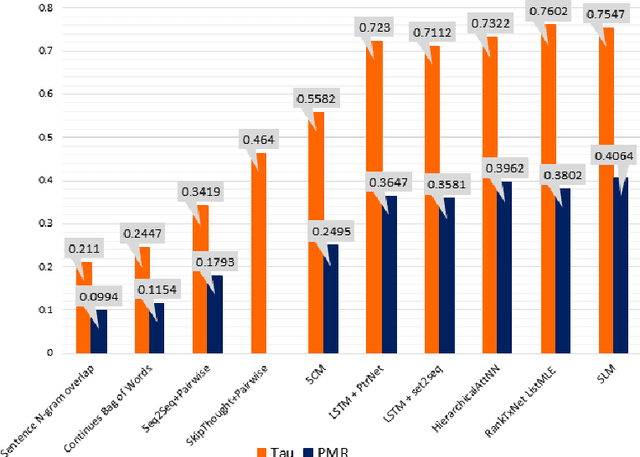
Discovering the logical sequence of events is one of the cornerstones in Natural Language Understanding. One approach to learn the sequence of events is to study the order of sentences in a coherent text. Sentence ordering can be applied in various tasks such as retrieval-based Question Answering, document summarization, storytelling, text generation, and dialogue systems. Furthermore, we can learn to model text coherence by learning how to order a set of shuffled sentences. Previous research has relied on RNN, LSTM, and BiLSTM architecture for learning text language models. However, these networks have performed poorly due to the lack of attention mechanisms. We propose an algorithm for sentence ordering in a corpus of short stories. Our proposed method uses a language model based on Universal Transformers (UT) that captures sentences' dependencies by employing an attention mechanism. Our method improves the previous state-of-the-art in terms of Perfect Match Ratio (PMR) score in the ROCStories dataset, a corpus of nearly 100K short human-made stories. The proposed model includes three components: Sentence Encoder, Language Model, and Sentence Arrangement with Brute Force Search. The first component generates sentence embeddings using SBERT-WK pre-trained model fine-tuned on the ROCStories data. Then a Universal Transformer network generates a sentence-level language model. For decoding, the network generates a candidate sentence as the following sentence of the current sentence. We use cosine similarity as a scoring function to assign scores to the candidate embedding and the embeddings of other sentences in the shuffled set. Then a Brute Force Search is employed to maximize the sum of similarities between pairs of consecutive sentences.