 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Benchmark for Large Language Models for Business Process Management Tasks
Oct 04, 2024An increasing number of organizations are deploying Large Language Models (LLMs) for a wide range of tasks. Despite their general utility, LLMs are prone to errors, ranging from inaccuracies to hallucinations. To objectively assess the capabilities of existing LLMs, performance benchmarks are conducted. However, these benchmarks often do not translate to more specific real-world tasks. This paper addresses the gap in benchmarking LLM performance in the Business Process Management (BPM) domain. Currently, no BPM-specific benchmarks exist, creating uncertainty about the suitability of different LLMs for BPM tasks. This paper systematically compares LLM performance on four BPM tasks focusing on small open-source models. The analysis aims to identify task-specific performance variations, compare the effectiveness of open-source versus commercial models, and assess the impact of model size on BPM task performance. This paper provides insights into the practical applications of LLMs in BPM, guiding organizations in selecting appropriate models for their specific needs.
xSemAD: Explainable Semantic Anomaly Detection in Event Logs Using Sequence-to-Sequence Models
Jun 28, 2024
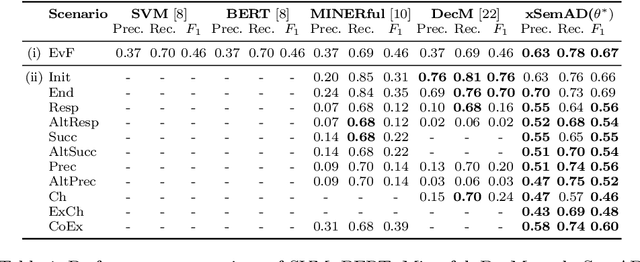
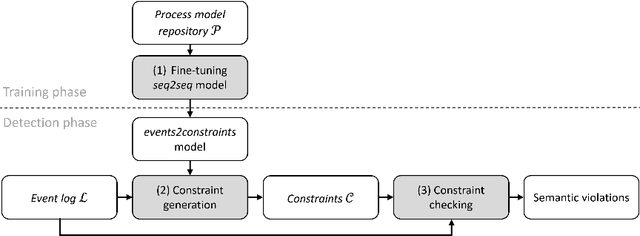
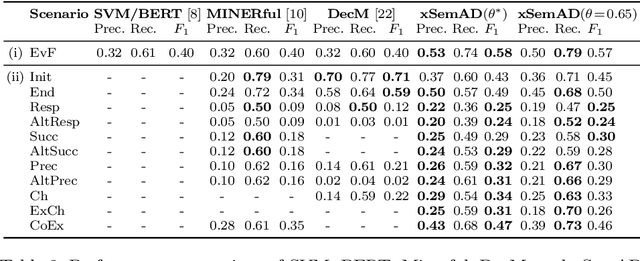
The identification of undesirable behavior in event logs is an important aspect of process mining that is often addressed by anomaly detection methods. Traditional anomaly detection methods tend to focus on statistically rare behavior and neglect the subtle difference between rarity and undesirability. The introduction of semantic anomaly detection has opened a promising avenue by identifying semantically deviant behavior. This work addresses a gap in semantic anomaly detection, which typically indicates the occurrence of an anomaly without explaining the nature of the anomaly. We propose xSemAD, an approach that uses a sequence-to-sequence model to go beyond pure identification and provides extended explanations. In essence, our approach learns constraints from a given process model repository and then checks whether these constraints hold in the considered event log. This approach not only helps understand the specifics of the undesired behavior, but also facilitates targeted corrective actions. Our experiments demonstrate that our approach outperforms existing state-of-the-art semantic anomaly detection methods.
Just Tell Me: Prompt Engineering in Business Process Management
Apr 14, 2023
GPT-3 and several other language models (LMs) can effectively address various natural language processing (NLP) tasks, including machine translation and text summarization. Recently, they have also been successfully employed in the business process management (BPM) domain, e.g., for predictive process monitoring and process extraction from text. This, however, typically requires fine-tuning the employed LM, which, among others, necessitates large amounts of suitable training data. A possible solution to this problem is the use of prompt engineering, which leverages pre-trained LMs without fine-tuning them. Recognizing this, we argue that prompt engineering can help bring the capabilities of LMs to BPM research. We use this position paper to develop a research agenda for the use of prompt engineering for BPM research by identifying the associated potentials and challenges.
Partial Order Resolution of Event Logs for Process Conformance Checking
Jul 05, 2020


While supporting the execution of business processes, information systems record event logs. Conformance checking relies on these logs to analyze whether the recorded behavior of a process conforms to the behavior of a normative specification. A key assumption of existing conformance checking techniques, however, is that all events are associated with timestamps that allow to infer a total order of events per process instance. Unfortunately, this assumption is often violated in practice. Due to synchronization issues, manual event recordings, or data corruption, events are only partially ordered. In this paper, we put forward the problem of partial order resolution of event logs to close this gap. It refers to the construction of a probability distribution over all possible total orders of events of an instance. To cope with the order uncertainty in real-world data, we present several estimators for this task, incorporating different notions of behavioral abstraction. Moreover, to reduce the runtime of conformance checking based on partial order resolution, we introduce an approximation method that comes with a bounded error in terms of accuracy. Our experiments with real-world and synthetic data reveal that our approach improves accuracy over the state-of-the-art considerably.