 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonly Interesting Images
Sep 25, 2024Images tell stories, trigger emotions, and let us recall memories -- they make us think. Thus, they have the ability to attract and hold one's attention, which is the definition of being "interesting". Yet, the appeal of an image is highly subjective. Looking at the image of my son taking his first steps will always bring me back to this emotional moment, while it is just a blurry, quickly taken snapshot to most others. Preferences vary widely: some adore cats, others are dog enthusiasts, and a third group may not be fond of either. We argue that every image can be interesting to a particular observer under certain circumstances. This work particularly emphasizes subjective preferences. However, our analysis of 2.5k image collections from diverse users of the photo-sharing platform Flickr reveals that specific image characteristics make them commonly more interesting. For instance, images, including professionally taken landscapes, appeal broadly due to their aesthetic qualities. In contrast, subjectively interesting images, such as those depicting personal or niche community events, resonate on a more individual level, often evoking personal memories and emotions.
Learning to Ignore: Fair and Task Independent Representations
Jan 21, 2021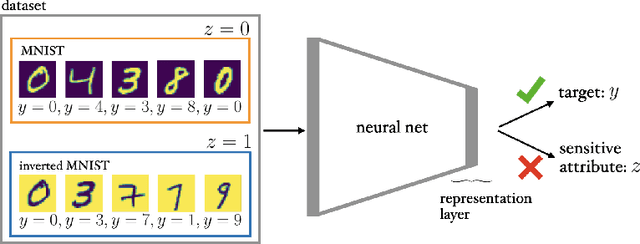
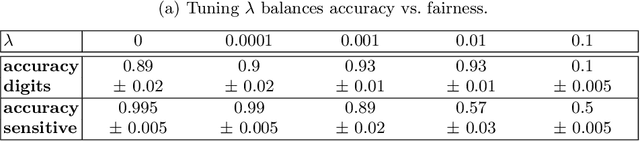
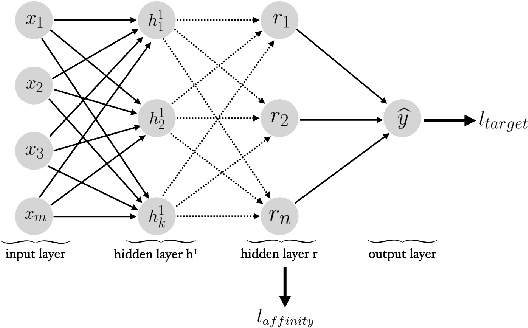
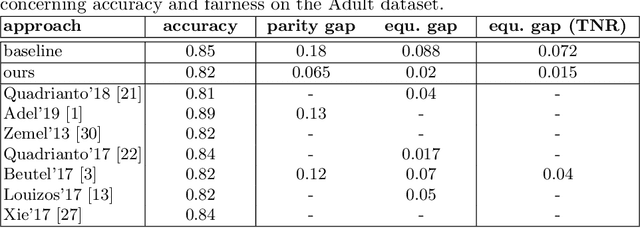
Training fair machine learning models, aiming for their interpretability and solving the problem of domain shift has gained a lot of interest in the last years. There is a vast amount of work addressing these topics, mostly in separation. In this work we show that they can be seen as a common framework of learning invariant representations. The representations should allow to predict the target while at the same time being invariant to sensitive attributes which split the dataset into subgroups. Our approach is based on the simple observation that it is impossible for any learning algorithm to differentiate samples if they have the same feature representation. This is formulated as an additional loss (regularizer) enforcing a common feature representation across subgroups. We apply it to learn fair models and interpret the influence of the sensitive attribute. Furthermore it can be used for domain adaptation, transferring knowledge and learning effectively from very few examples. In all applications it is essential not only to learn to predict the target, but also to learn what to ignore.
Lossy Image Compression with Recurrent Neural Networks: from Human Perceived Visual Quality to Classification Accuracy
Oct 08, 2019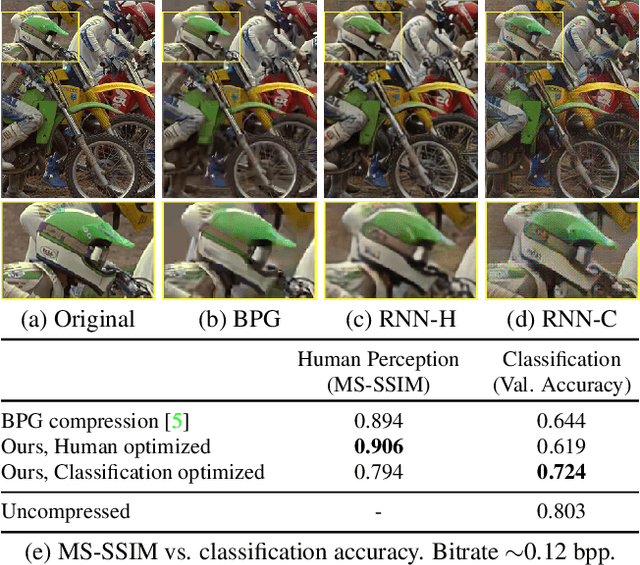


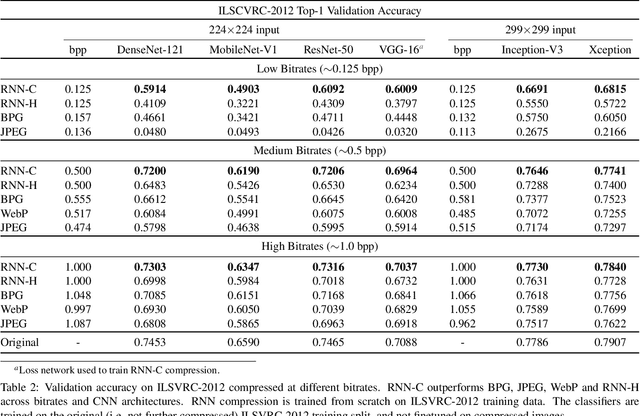
Deep neural networks have recently advanced the state-of-the-art in image compression and surpassed many traditional compression algorithms. The training of such networks involves carefully trading off entropy of the latent representation against reconstruction quality. The term quality crucially depends on the observer of the images which, in the vast majority of literature, is assumed to be human. In this paper, we go beyond this notion of quality and look at human visual perception and machine perception simultaneously. To that end, we propose a family of loss functions that allows to optimize deep image compression depending on the observer and to interpolate between human perceived visual quality and classification accuracy. Our experiments show that our proposed training objectives result in compression systems that, when trained with machine friendly loss, preserve accuracy much better than the traditional codecs BPG, WebP and JPEG, without requiring fine-tuning of inference algorithms on decoded images and independent of the classifier architecture. At the same time, when using the human friendly loss, we achieve competitive performance in terms of MS-SSIM.