 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKANDINSKYPatterns -- An experimental exploration environment for Pattern Analysis and Machine Intelligence
Feb 28, 2021Machine intelligence is very successful at standard recognition tasks when having high-quality training data. There is still a significant gap between machine-level pattern recognition and human-level concept learning. Humans can learn under uncertainty from only a few examples and generalize these concepts to solve new problems. The growing interest in explainable machine intelligence, requires experimental environments and diagnostic tests to analyze weaknesses in existing approaches to drive progress in the field. In this paper, we discuss existing diagnostic tests and test data sets such as CLEVR, CLEVERER, CLOSURE, CURI, Bongard-LOGO, V-PROM, and present our own experimental environment: The KANDINSKYPatterns, named after the Russian artist Wassily Kandinksy, who made theoretical contributions to compositivity, i.e. that all perceptions consist of geometrically elementary individual components. This was experimentally proven by Hubel &Wiesel in the 1960s and became the basis for machine learning approaches such as the Neocognitron and the even later Deep Learning. While KANDINSKYPatterns have computationally controllable properties on the one hand, bringing ground truth, they are also easily distinguishable by human observers, i.e., controlled patterns can be described by both humans and algorithms, making them another important contribution to international research in machine intelligence.
Kandinsky Patterns
Jun 03, 2019

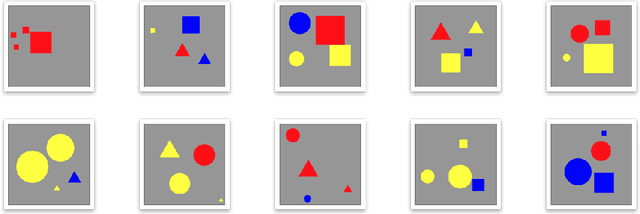
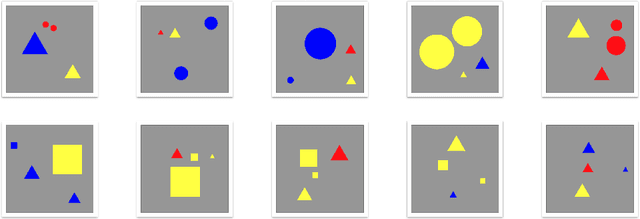
Kandinsky Figures and Kandinsky Patterns are mathematically describable, simple self-contained hence controllable test data sets for the development, validation and training of explainability in artificial intelligence. Whilst Kandinsky Patterns have these computationally manageable properties, they are at the same time easily distinguishable from human observers. Consequently, controlled patterns can be described by both humans and computers. We define a Kandinsky Pattern as a set of Kandinsky Figures, where for each figure an "infallible authority" defines that the figure belongs to the Kandinsky Pattern. With this simple principle we build training and validation data sets for automatic interpretability and context learning. In this paper we describe the basic idea and some underlying principles of Kandinsky Patterns and provide a Github repository to invite the international machine learning research community to a challenge to experiment with our Kandinsky Patterns to expand and thus make progress in the field of explainable AI and to contribute to the upcoming field of explainability and causability.