 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKandinsky Patterns
Paper and Code


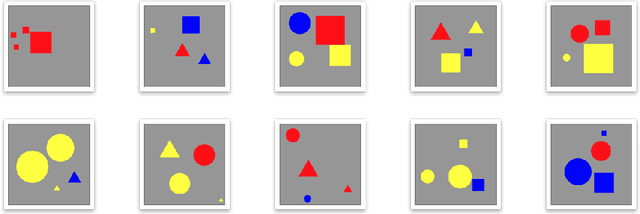
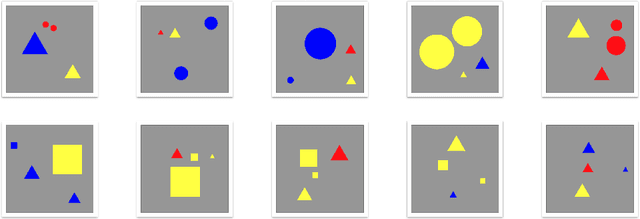
Kandinsky Figures and Kandinsky Patterns are mathematically describable, simple self-contained hence controllable test data sets for the development, validation and training of explainability in artificial intelligence. Whilst Kandinsky Patterns have these computationally manageable properties, they are at the same time easily distinguishable from human observers. Consequently, controlled patterns can be described by both humans and computers. We define a Kandinsky Pattern as a set of Kandinsky Figures, where for each figure an "infallible authority" defines that the figure belongs to the Kandinsky Pattern. With this simple principle we build training and validation data sets for automatic interpretability and context learning. In this paper we describe the basic idea and some underlying principles of Kandinsky Patterns and provide a Github repository to invite the international machine learning research community to a challenge to experiment with our Kandinsky Patterns to expand and thus make progress in the field of explainable AI and to contribute to the upcoming field of explainability and causability.