 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDAN: Convolutional Dense Attention-guided Network for Low-light Image Enhancement
Aug 26, 2023Low-light images, characterized by inadequate illumination, pose challenges of diminished clarity, muted colors, and reduced details. Low-light image enhancement, an essential task in computer vision, aims to rectify these issues by improving brightness, contrast, and overall perceptual quality, thereby facilitating accurate analysis and interpretation. This paper introduces the Convolutional Dense Attention-guided Network (CDAN), a novel solution for enhancing low-light images. CDAN integrates an autoencoder-based architecture with convolutional and dense blocks, complemented by an attention mechanism and skip connections. This architecture ensures efficient information propagation and feature learning. Furthermore, a dedicated post-processing phase refines color balance and contrast. Our approach demonstrates notable progress compared to state-of-the-art results in low-light image enhancement, showcasing its robustness across a wide range of challenging scenarios. Our model performs remarkably on benchmark datasets, effectively mitigating under-exposure and proficiently restoring textures and colors in diverse low-light scenarios. This achievement underscores CDAN's potential for diverse computer vision tasks, notably enabling robust object detection and recognition in challenging low-light conditions.
Dual Branch Deep Learning Network for Detection and Stage Grading of Diabetic Retinopathy
Aug 19, 2023Diabetic retinopathy is a severe complication of diabetes that can lead to permanent blindness if not treated promptly. Early and accurate diagnosis of the disease is essential for successful treatment. This paper introduces a deep learning method for the detection and stage grading of diabetic retinopathy, using a single fundus retinal image. Our model utilizes transfer learning, employing two state-of-the-art pre-trained models as feature extractors and fine-tuning them on a new dataset. The proposed model is trained on a large multi-center dataset, including the APTOS 2019 dataset, obtained from publicly available sources. It achieves remarkable performance in diabetic retinopathy detection and stage classification on the APTOS 2019, outperforming the established literature. For binary classification, the proposed approach achieves an accuracy of 98.50%, a sensitivity of 99.46%, and a specificity of 97.51%. In stage grading, it achieves a quadratic weighted kappa of 93.00%, an accuracy of 89.60%, a sensitivity of 89.60%, and a specificity of 97.72%. The proposed approach serves as a reliable screening and stage grading tool for diabetic retinopathy, offering significant potential to enhance clinical decision-making and patient care.
An Empirical Study on Detecting COVID-19 in Chest X-ray Images Using Deep Learning Based Methods
Oct 10, 2020
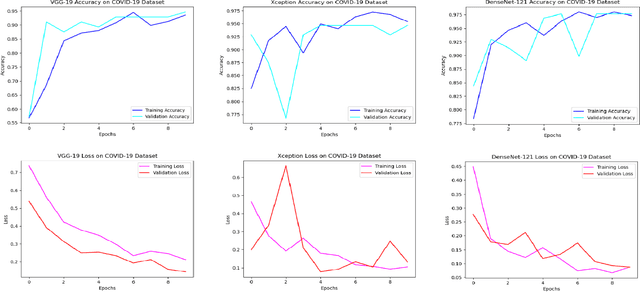
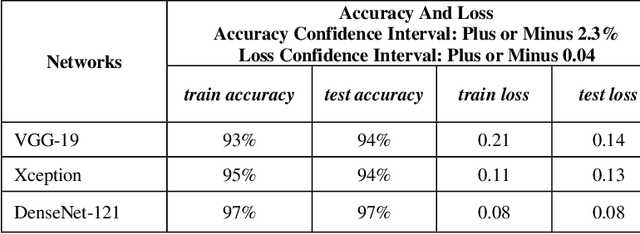
Spreading of COVID-19 virus has increased the efforts to provide testing kits. Not only the preparation of these kits had been hard, rare, and expensive but also using them is another issue. Results have shown that these kits take some crucial time to recognize the virus, in addition to the fact that they encounter with 30% loss. In this paper, we have studied the usage of x-ray pictures which are ubiquitous, for the classification of COVID-19 chest Xray images, by the existing convolutional neural networks (CNNs). We intend to train chest x-rays of infected and not infected ones with different CNNs architectures including VGG19, Densnet-121, and Xception. Training these architectures resulted in different accuracies which were much faster and more precise than usual ways of testing.
An Efficient Approach for Using Expectation Maximization Algorithm in Capsule Networks
Dec 22, 2019
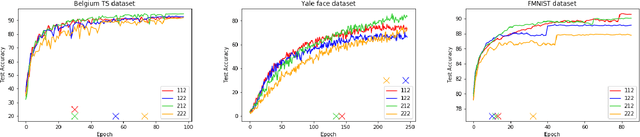

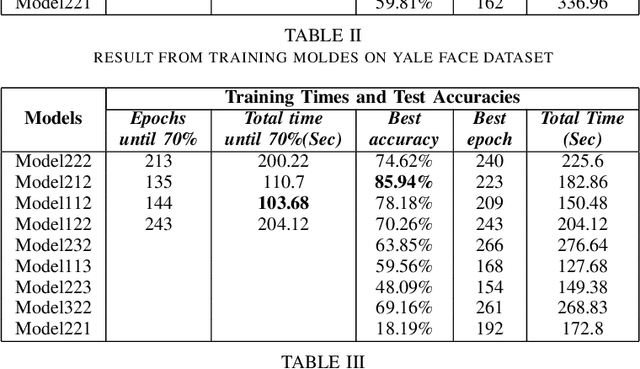
Capsule Networks (CapsNets) are brand-new architectures that have shown ground-breaking results in certain areas of Computer Vision (CV). In 2017, Hinton and his team introduced CapsNets with routing-by-agreement in "Sabour et al" and in a more recent paper "Matrix Capsules with EM Routing" they proposed a more complete architecture with Expectation-Maximization (EM) algorithm. Unlike the traditional convolutional neural networks (CNNs), this architecture is able to preserve the pose of the objects in the picture. Due to this characteristic, it has been able to beat the previous state-of-theart results on the smallNORB dataset, which includes samples with various view points. Also, this architecture is more robust to white box adversarial attacks. However, CapsNets have two major drawbacks. They can't perform as well as CNNs on complex datasets and, they need a huge amount of time for training. We try to mitigate these shortcomings by finding optimum settings of EM routing iterations for training CapsNets. Unlike the past studies, we use un-equal numbers of EM routing iterations for different stages of the CapsNet. For our research, we use three datasets: Yale face dataset, Belgium Traffic Sign dataset, and Fashion-MNIST dataset.
An Empirical Study on Position of the Batch Normalization Layer in Convolutional Neural Networks
Dec 12, 2019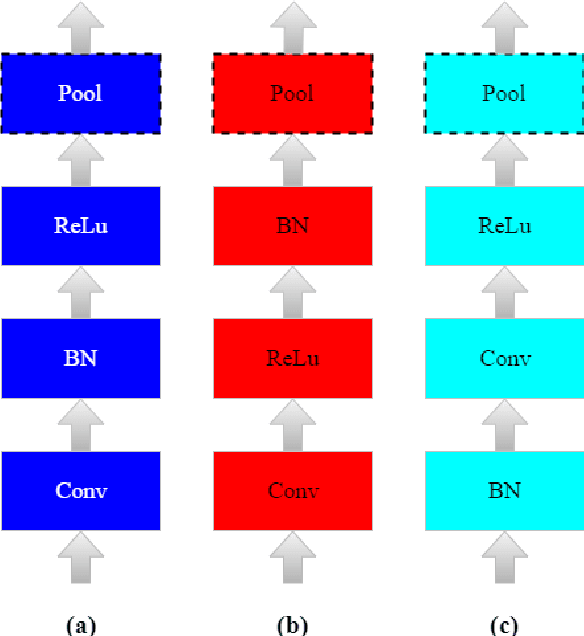

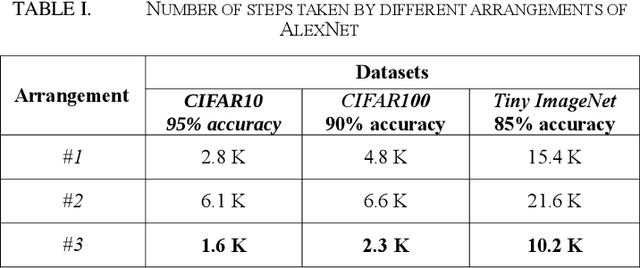
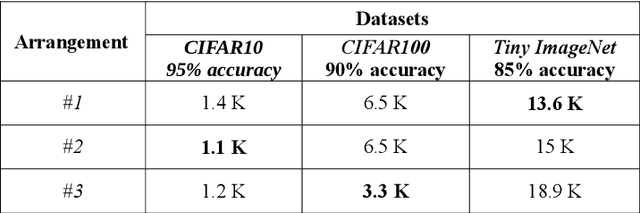
In this paper, we have studied how the training of the convolutional neural networks (CNNs) can be affected by changing the position of the batch normalization (BN) layer. Three different convolutional neural networks have been chosen for our experiments. These networks are AlexNet, VGG-16, and ResNet- 20. We show that the speed up in training provided by the BN algorithm can be improved by using other positions for the BN layer than the one suggested by its original paper. Also, we discuss how the BN layer in a certain position can aid the training of one network but not the other. Three different positions for the BN layer have been studied in this research. These positions are: the BN layer between the convolution layer and the non-linear activation function, the BN layer after the non-linear activation function and finally, the BN layer before each of the convolutional layers.
An Objective Evaluation Metric for image fusion based on Del Operator
May 25, 2019


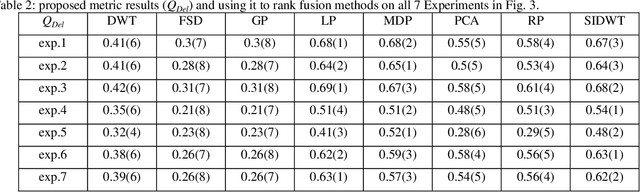
In this paper, a novel objective evaluation metric for image fusion is presented. Remarkable and attractive points of the proposed metric are that it has no parameter, the result is probability in the range of [0, 1] and it is free from illumination dependence. This metric is easy to implement and the result is computed in four steps: (1) Smoothing the images using Gaussian filter. (2) Transforming images to a vector field using Del operator. (3) Computing the normal distribution function ({\mu},{\sigma}) for each corresponding pixel, and converting to the standard normal distribution function. (4) Computing the probability of being well-behaved fusion method as the result. To judge the quality of the proposed metric, it is compared to thirteen well-known non-reference objective evaluation metrics, where eight fusion methods are employed on seven experiments of multimodal medical images. The experimental results and statistical comparisons show that in contrast to the previously objective evaluation metrics the proposed one performs better in terms of both agreeing with human visual perception and evaluating fusion methods that are not performed at the same level.