 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Approach for Using Expectation Maximization Algorithm in Capsule Networks
Paper and Code

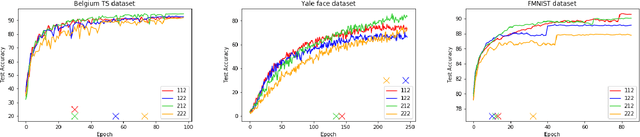

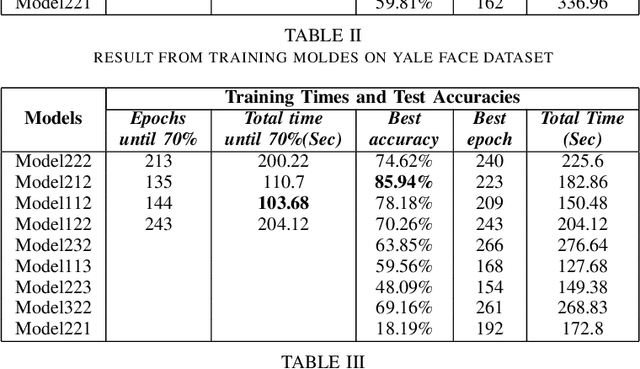
Capsule Networks (CapsNets) are brand-new architectures that have shown ground-breaking results in certain areas of Computer Vision (CV). In 2017, Hinton and his team introduced CapsNets with routing-by-agreement in "Sabour et al" and in a more recent paper "Matrix Capsules with EM Routing" they proposed a more complete architecture with Expectation-Maximization (EM) algorithm. Unlike the traditional convolutional neural networks (CNNs), this architecture is able to preserve the pose of the objects in the picture. Due to this characteristic, it has been able to beat the previous state-of-theart results on the smallNORB dataset, which includes samples with various view points. Also, this architecture is more robust to white box adversarial attacks. However, CapsNets have two major drawbacks. They can't perform as well as CNNs on complex datasets and, they need a huge amount of time for training. We try to mitigate these shortcomings by finding optimum settings of EM routing iterations for training CapsNets. Unlike the past studies, we use un-equal numbers of EM routing iterations for different stages of the CapsNet. For our research, we use three datasets: Yale face dataset, Belgium Traffic Sign dataset, and Fashion-MNIST dataset.