 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMLBench: A Comprehensive Experimental Evaluation of Automated Machine Learning Frameworks
Apr 18, 2022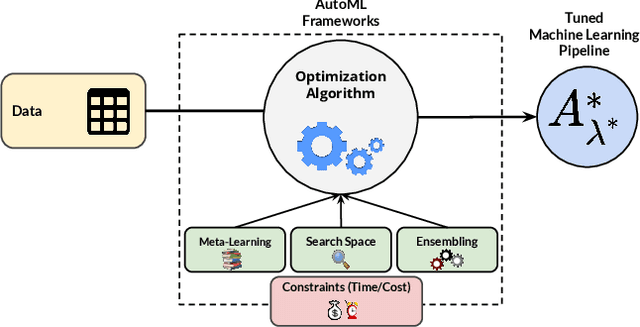
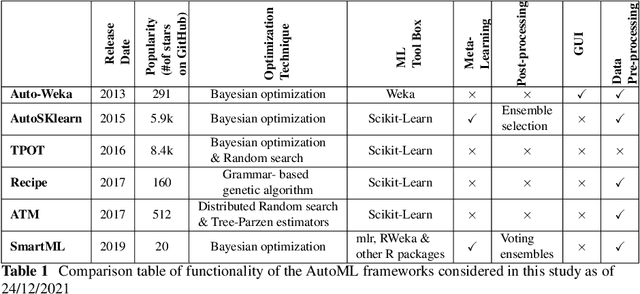
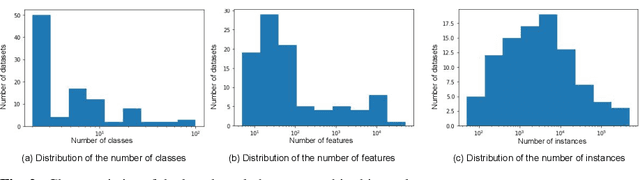
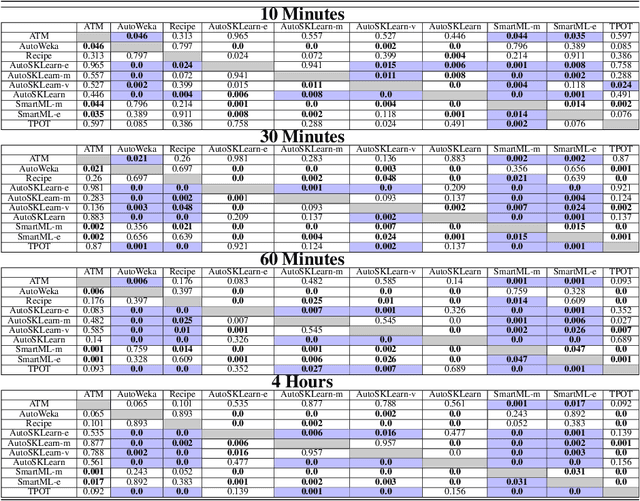
Nowadays, machine learning is playing a crucial role in harnessing the power of the massive amounts of data that we are currently producing every day in our digital world. With the booming demand for machine learning applications, it has been recognized that the number of knowledgeable data scientists can not scale with the growing data volumes and application needs in our digital world. In response to this demand, several automated machine learning (AutoML) techniques and frameworks have been developed to fill the gap of human expertise by automating the process of building machine learning pipelines. In this study, we present a comprehensive evaluation and comparison of the performance characteristics of six popular AutoML frameworks, namely, Auto-Weka, AutoSKlearn, TPOT, Recipe, ATM, and SmartML across 100 data sets from established AutoML benchmark suites. Our experimental evaluation considers different aspects for its comparison including the performance impact of several design decisions including time budget, size of search space, meta-learning, and ensemble construction. The results of our study reveal various interesting insights that can significantly guide and impact the design of AutoML frameworks.
AutoML: Exploration v.s. Exploitation
Dec 29, 2019


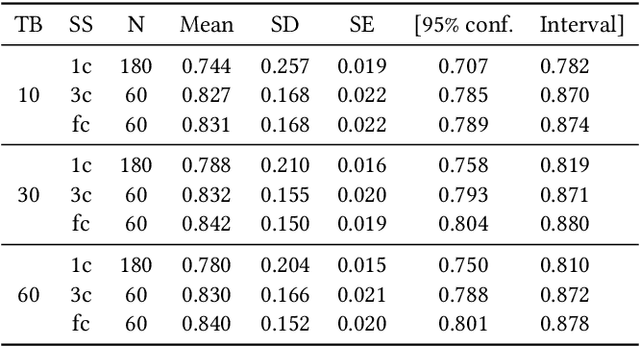
Building a machine learning (ML) pipeline in an automated way is a crucial and complex task as it is constrained with the available time budget and resources. This encouraged the research community to introduce several solutions to utilize the available time and resources. A lot of work is done to suggest the most promising classifiers for a given dataset using sundry of techniques including meta-learning based techniques. This gives the autoML framework the chance to spend more time exploiting those classifiers and tuning their hyper-parameters. In this paper, we empirically study the hypothesis of improving the pipeline performance by exploiting the most promising classifiers within the limited time budget. We also study the effect of increasing the time budget over the pipeline performance. The empirical results across autoSKLearn, TPOT and ATM, show that exploiting the most promising classifiers does not achieve a statistically better performance than exploring the entire search space. The same conclusion is also applied for long time budgets.