 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBibRank: Automatic Keyphrase Extraction Platform Using~Metadata
Oct 13, 2023


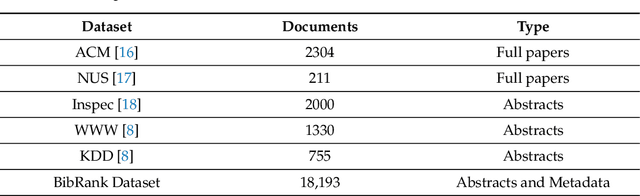
Automatic Keyphrase Extraction involves identifying essential phrases in a document. These keyphrases are crucial in various tasks such as document classification, clustering, recommendation, indexing, searching, summarization, and text simplification. This paper introduces a platform that integrates keyphrase datasets and facilitates the evaluation of keyphrase extraction algorithms. The platform includes BibRank, an automatic keyphrase extraction algorithm that leverages a rich dataset obtained by parsing bibliographic data in BibTeX format. BibRank combines innovative weighting techniques with positional, statistical, and word co-occurrence information to extract keyphrases from documents. The platform proves valuable for researchers and developers seeking to enhance their keyphrase extraction algorithms and advance the field of natural language processing.
* 12 pages , 4 figures, 8 tables
AutoML: Exploration v.s. Exploitation
Dec 29, 2019


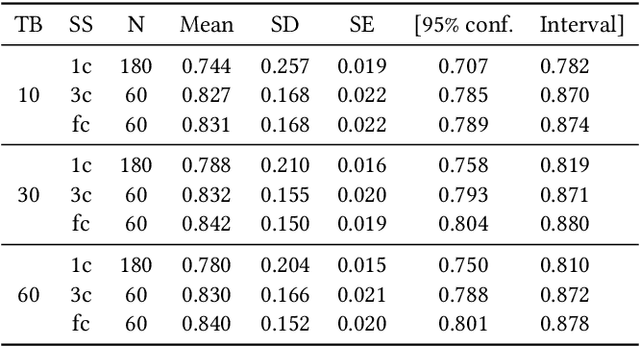
Building a machine learning (ML) pipeline in an automated way is a crucial and complex task as it is constrained with the available time budget and resources. This encouraged the research community to introduce several solutions to utilize the available time and resources. A lot of work is done to suggest the most promising classifiers for a given dataset using sundry of techniques including meta-learning based techniques. This gives the autoML framework the chance to spend more time exploiting those classifiers and tuning their hyper-parameters. In this paper, we empirically study the hypothesis of improving the pipeline performance by exploiting the most promising classifiers within the limited time budget. We also study the effect of increasing the time budget over the pipeline performance. The empirical results across autoSKLearn, TPOT and ATM, show that exploiting the most promising classifiers does not achieve a statistically better performance than exploring the entire search space. The same conclusion is also applied for long time budgets.