 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Learning of Two-Stage Beamformers in Passive IRS-Assisted Systems with Inexact Oracles
Oct 31, 2024



We develop an efficient data-driven and model-free unsupervised learning algorithm for achieving fully passive intelligent reflective surface (IRS)-assisted optimal short/long-term beamforming in wireless communication networks. The proposed algorithm is based on a zeroth-order stochastic gradient ascent methodology, suitable for tackling two-stage stochastic nonconvex optimization problems with continuous uncertainty and unknown (or "black-box") terms present in the objective function, via the utilization of inexact evaluation oracles. We showcase that the algorithm can operate under realistic and general assumptions, and establish its convergence rate close to some stationary point of the associated two-stage (i.e., short/long-term) problem, particularly in cases where the second-stage (i.e., short-term) beamforming problem (e.g., transmit precoding) is solved inexactly using an arbitrary (inexact) oracle. The proposed algorithm is applicable on a wide variety of IRS-assisted optimal beamforming settings, while also being able to operate without (cascaded) channel model assumptions or knowledge of channel statistics, and over arbitrary IRS physical configurations; thus, no active sensing capability at the IRS(s) is needed. Our algorithm is numerically demonstrated to be very effective in a range of experiments pertaining to a well-studied MISO downlink model, including scenarios demanding physical IRS tuning (e.g., directly through varactor capacitances), even in large-scale regimes.
Model-Free Learning of Optimal Deterministic Resource Allocations in Wireless Systems via Action-Space Exploration
Aug 23, 2021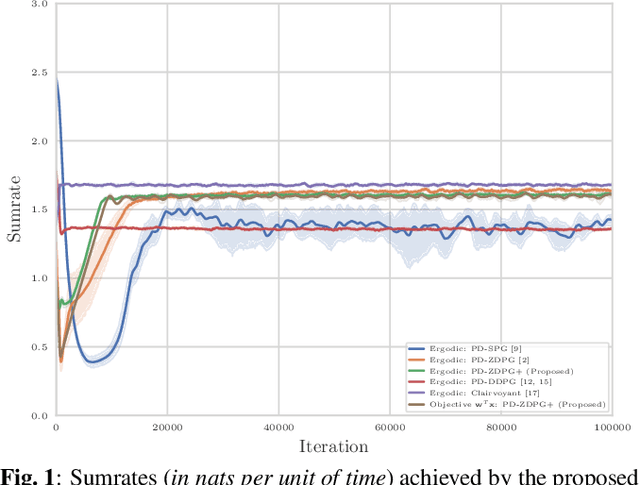
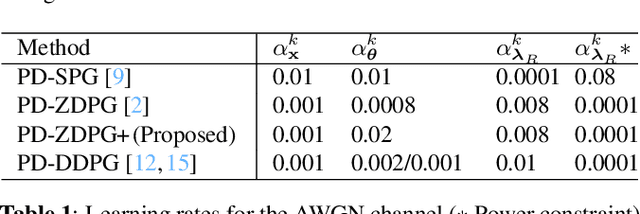
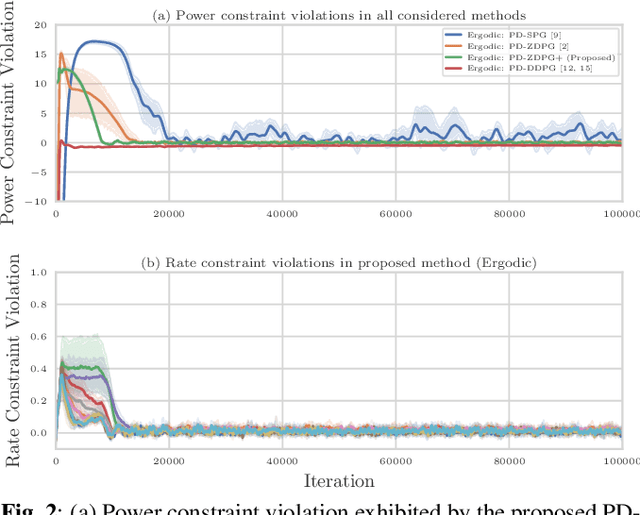
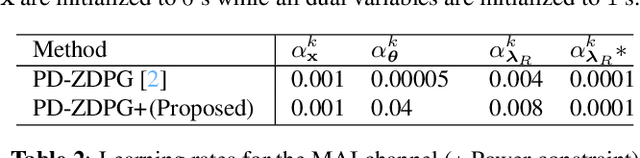
Wireless systems resource allocation refers to perpetual and challenging nonconvex constrained optimization tasks, which are especially timely in modern communications and networking setups involving multiple users with heterogeneous objectives and imprecise or even unknown models and/or channel statistics. In this paper, we propose a technically grounded and scalable primal-dual deterministic policy gradient method for efficiently learning optimal parameterized resource allocation policies. Our method not only efficiently exploits gradient availability of popular universal policy representations, such as deep neural networks, but is also truly model-free, as it relies on consistent zeroth-order gradient approximations of the associated random network services constructed via low-dimensional perturbations in action space, thus fully bypassing any dependence on critics. Both theory and numerical simulations confirm the efficacy and applicability of the proposed approach, as well as its superiority over the current state of the art in terms of both achieving near-optimal performance and scalability.