 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Networks in Human Emotion Synthesis:A Review
Nov 07, 2020

Synthesizing realistic data samples is of great value for both academic and industrial communities. Deep generative models have become an emerging topic in various research areas like computer vision and signal processing. Affective computing, a topic of a broad interest in computer vision society, has been no exception and has benefited from generative models. In fact, affective computing observed a rapid derivation of generative models during the last two decades. Applications of such models include but are not limited to emotion recognition and classification, unimodal emotion synthesis, and cross-modal emotion synthesis. As a result, we conducted a review of recent advances in human emotion synthesis by studying available databases, advantages, and disadvantages of the generative models along with the related training strategies considering two principal human communication modalities, namely audio and video. In this context, facial expression synthesis, speech emotion synthesis, and the audio-visual (cross-modal) emotion synthesis is reviewed extensively under different application scenarios. Gradually, we discuss open research problems to push the boundaries of this research area for future works.
Image Resolution Enhancement by Using Interpolation Followed by Iterative Back Projection
Jan 03, 2016
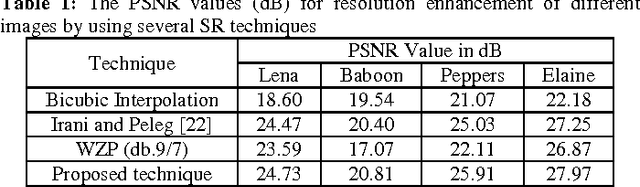

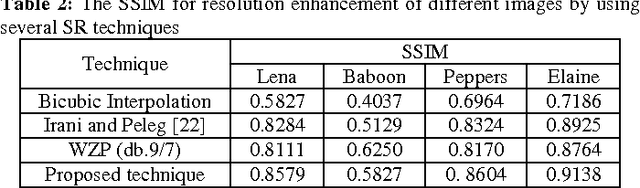
In this paper, we propose a new super resolution technique based on the interpolation followed by registering them using iterative back projection (IBP). Low resolution images are being interpolated and then the interpolated images are being registered in order to generate a sharper high resolution image. The proposed technique has been tested on Lena, Elaine, Pepper, and Baboon. The quantitative peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) results as well as the visual results show the superiority of the proposed technique over the conventional and state-of-art image super resolution techniques. For Lena's image, the PSNR is 6.52 dB higher than the bicubic interpolation.