 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Assisted Knowledge Graph Completion for Curriculum and Domain Modelling in Personalized Higher Education Recommendations
Jan 21, 2025While learning personalization offers great potential for learners, modern practices in higher education require a deeper consideration of domain models and learning contexts, to develop effective personalization algorithms. This paper introduces an innovative approach to higher education curriculum modelling that utilizes large language models (LLMs) for knowledge graph (KG) completion, with the goal of creating personalized learning-path recommendations. Our research focuses on modelling university subjects and linking their topics to corresponding domain models, enabling the integration of learning modules from different faculties and institutions in the student's learning path. Central to our approach is a collaborative process, where LLMs assist human experts in extracting high-quality, fine-grained topics from lecture materials. We develop a domain, curriculum, and user models for university modules and stakeholders. We implement this model to create the KG from two study modules: Embedded Systems and Development of Embedded Systems Using FPGA. The resulting KG structures the curriculum and links it to the domain models. We evaluate our approach through qualitative expert feedback and quantitative graph quality metrics. Domain experts validated the relevance and accuracy of the model, while the graph quality metrics measured the structural properties of our KG. Our results show that the LLM-assisted graph completion approach enhances the ability to connect related courses across disciplines to personalize the learning experience. Expert feedback also showed high acceptance of the proposed collaborative approach for concept extraction and classification.
Knowledge Graphs as Context Sources for LLM-Based Explanations of Learning Recommendations
Mar 05, 2024


In the era of personalized education, the provision of comprehensible explanations for learning recommendations is of a great value to enhance the learner's understanding and engagement with the recommended learning content. Large language models (LLMs) and generative AI in general have recently opened new doors for generating human-like explanations, for and along learning recommendations. However, their precision is still far away from acceptable in a sensitive field like education. To harness the abilities of LLMs, while still ensuring a high level of precision towards the intent of the learners, this paper proposes an approach to utilize knowledge graphs (KG) as a source of factual context, for LLM prompts, reducing the risk of model hallucinations, and safeguarding against wrong or imprecise information, while maintaining an application-intended learning context. We utilize the semantic relations in the knowledge graph to offer curated knowledge about learning recommendations. With domain-experts in the loop, we design the explanation as a textual template, which is filled and completed by the LLM. Domain experts were integrated in the prompt engineering phase as part of a study, to ensure that explanations include information that is relevant to the learner. We evaluate our approach quantitatively using Rouge-N and Rouge-L measures, as well as qualitatively with experts and learners. Our results show an enhanced recall and precision of the generated explanations compared to those generated solely by the GPT model, with a greatly reduced risk of generating imprecise information in the final learning explanation.
Supporting Student Decisions on Learning Recommendations: An LLM-Based Chatbot with Knowledge Graph Contextualization for Conversational Explainability and Mentoring
Jan 24, 2024Student commitment towards a learning recommendation is not separable from their understanding of the reasons it was recommended to them; and their ability to modify it based on that understanding. Among explainability approaches, chatbots offer the potential to engage the student in a conversation, similar to a discussion with a peer or a mentor. The capabilities of chatbots, however, are still not sufficient to replace a human mentor, despite the advancements of generative AI (GenAI) and large language models (LLM). Therefore, we propose an approach to utilize chatbots as mediators of the conversation and sources of limited and controlled generation of explanations, to harvest the potential of LLMs while reducing their potential risks at the same time. The proposed LLM-based chatbot supports students in understanding learning-paths recommendations. We use a knowledge graph (KG) as a human-curated source of information, to regulate the LLM's output through defining its prompt's context. A group chat approach is developed to connect students with human mentors, either on demand or in cases that exceed the chatbot's pre-defined tasks. We evaluate the chatbot with a user study, to provide a proof-of-concept and highlight the potential requirements and limitations of utilizing chatbots in conversational explainability.
Building Contextual Knowledge Graphs for Personalized Learning Recommendations using Text Mining and Semantic Graph Completion
Jan 24, 2024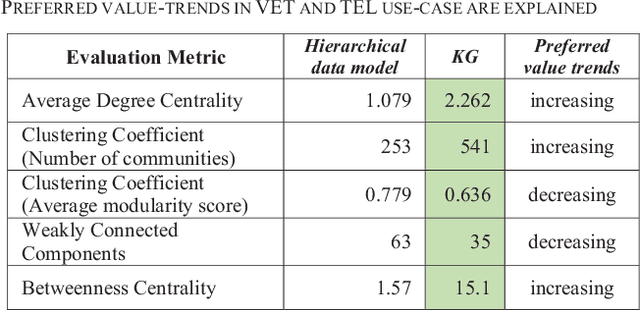
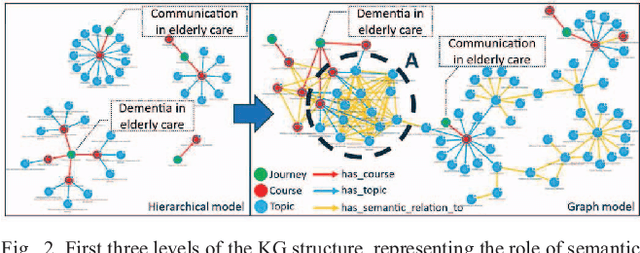


Modelling learning objects (LO) within their context enables the learner to advance from a basic, remembering-level, learning objective to a higher-order one, i.e., a level with an application- and analysis objective. While hierarchical data models are commonly used in digital learning platforms, using graph-based models enables representing the context of LOs in those platforms. This leads to a foundation for personalized recommendations of learning paths. In this paper, the transformation of hierarchical data models into knowledge graph (KG) models of LOs using text mining is introduced and evaluated. We utilize custom text mining pipelines to mine semantic relations between elements of an expert-curated hierarchical model. We evaluate the KG structure and relation extraction using graph quality-control metrics and the comparison of algorithmic semantic-similarities to expert-defined ones. The results show that the relations in the KG are semantically comparable to those defined by domain experts, and that the proposed KG improves representing and linking the contexts of LOs through increasing graph communities and betweenness centrality.
Explainable Graph-based Search for Lessons-Learned Documents in the Semiconductor Industry
May 18, 2021
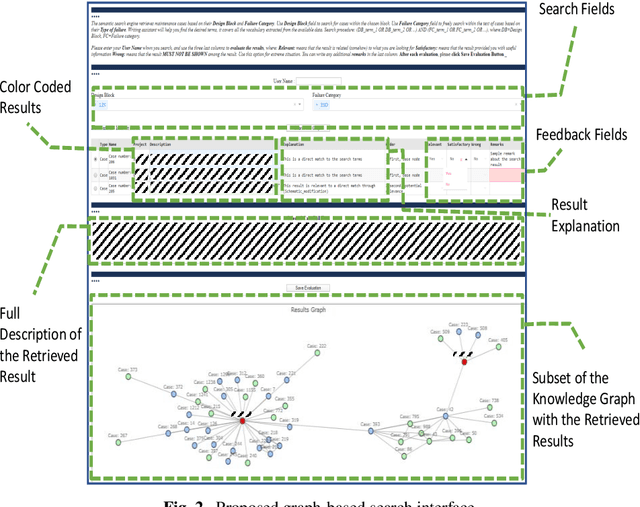
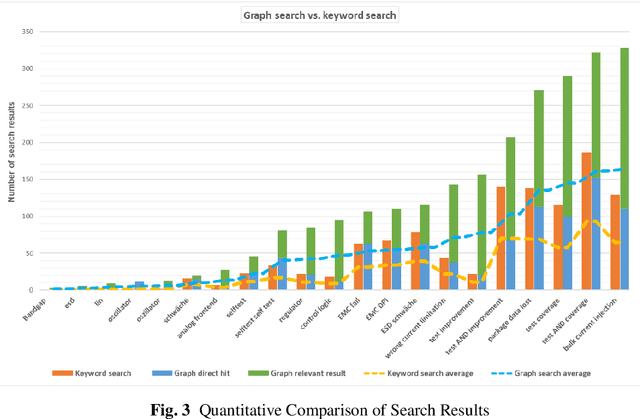
Industrial processes produce a considerable volume of data and thus information. Whether it is structured sensory data or semi- to unstructured textual data, the knowledge that can be derived from it is critical to the sustainable development of the industrial process. A key challenge of this sustainability is the intelligent management of the generated data, as well as the knowledge extracted from it, in order to utilize this knowledge for improving future procedures. This challenge is a result of the tailored documentation methods and domain-specific requirements, which include the need for quick visibility of the documented knowledge. In this paper, we utilize the expert knowledge documented in chip-design failure reports in supporting user access to information that is relevant to a current chip design. Unstructured, free, textual data in previous failure documentations provides a valuable source of lessons-learned, which expert design-engineers have experienced, solved and documented. To achieve a sustainable utilization of knowledge within the company, not only the inherent knowledge has to be mined from unstructured textual data, but also the relations between the lessons-learned, uncovering potentially unknown links. In this research, a knowledge graph is constructed, in order to represent and use the interconnections between reported design failures. A search engine is developed and applied onto the graph to answer queries. In contrast to mere keyword-based searching, the searchability of the knowledge graph offers enhanced search results beyond direct matches and acts as a mean for generating explainable results and result recommendations. Results are provided to the design engineer through an interactive search interface, in which, the feedback from the user is used to further optimize relations for future iterations of the knowledge graph.